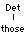1 Foundational issues
This book is an introduction to generative grammar from a Chomskyan
perspective. By the time you finish this chapter, you will have a clearer
understanding of what we mean by this sentence, and by the time you finish
the entire book, your understanding of it should be clearer and deeper
still. But for now, you have probably gained the impression that this book
is about grammar of some sort. And right there, we have a problem. The
problem is that there is an everyday sense of the term 'grammar' and a
quite different sense in which the term is used in linguistics.
Prescriptive versus descriptive grammar
In the everyday sense, 'grammar' refers to a collection of rules
concerning what counts as socially acceptable and unacceptable language
use. Some of these rules, like the ones in (1), make reference to
particular words and apply to both spoken and written language.
| (1)
| a.
|
| Don't use ain't.
|
|
| b.
|
| Don't use seen as the past tense of see (as in I seen
him at the party last night).
|
But mainly, the rules in question concern the proper composition of
sentences in written language, and you probably recall being taught rules
like those in (2) at school.
| (2)
| a.
|
| Don't start a sentence with a conjunction.
|
|
| b.
|
| Don't use contractions.
|
|
| c.
|
| Don't use sentence fragments.
|
|
| d.
|
| Don't end a sentence with a linking verb.
|
|
| e.
|
| Don't use dangling participles.
|
|
| f.
|
| Don't end a sentence with a preposition.
|
|
| g.
|
| Don't use an object pronoun for a subject pronoun in a conjoined noun
phrase.
|
|
| h.
|
| Don't use a plural pronoun to refer back to a singular noun like
everyone, no-one, someone, and the like.
|
|
| i.
|
| Don't split infinitives.
|
|
| j.
|
| Use whom, not who, as the object of a verb or
preposition.
|
Someone who composes sentences in accordance with rules like those in
(2) is said to have good grammar, whereas someone said to have bad grammar
doesn't apply the rules when they ought to be applied,1 producing sentences like (3).
| (3)
| a.
|
| Over there is the guy who I went to the party with.
| violates (2f), (2j)
|
|
| b.
|
| Bill and me went to the store.
| violates (2g)
|
Now if rules like those in (2) were the only ones
that were used to form English sentences, then people who didn't follow
them should produce rampantly variable and confusing sentences, leading
in extreme cases to a complete breakdown of communication. However, even
people who routinely produce sentences like those in (3) do not produce the
likes of (4).
| (4)
| a.
|
| Over there is guy the who I went to party the with.
|
|
| b.
|
| Over there is the who I went to the party with guy.
|
|
| c.
|
| Bill and me the store to went.
|
The sentences in (3) may be instances of bad grammar in the everyday
sense, but they are still English sentences. By contrast, we don't need
to rely on school rules to tell us that the examples in (4) are not
English sentences - even though they contain exactly the same English
words as the sentences in in (3).
Since native speakers of English do not
produce a variable mishmash of words of the sort in (4), there must be
some other sort of rules according to which sentences are composed. We
can determine what some of them are by taking a closer look at the
sequences in (4). What exactly is it that makes them into word salad?
In (4a), the article the is in the wrong order with respect to
guy and party, the nouns that it belongs with. In (4b),
the relative clause (who I went to the party with) is in the
wrong order with respect to the noun that it modifies (guy). In
(4c), the preposition to is in the wrong order with respect to
its object (the store). In other words, the sentences in (4) do
not follow the rules in (5).
| (5)
| a.
|
| Articles precede the nouns they belong with.
|
|
| b.
|
| Relative clauses follow the noun that they modify.
|
|
| c.
|
| Prepositions precede their objects.
|
(There's a fourth rule that's not followed in (4), which you are asked
to formulate in the Exercises.)
Rules like those in (5) have a quite different intention from those
in (2). The rules in (2) are normative or prescriptive,
whereas those in (5) are descriptive. Rules of prescriptive
grammar have the same status as rules of etiquette (like table manners
or dress codes) or the laws of society, which divide the entire spectrum
of possible human behavior into socially acceptable or legal behavior,
on the one hand, and socially unacceptable or illegal behavior, on the
other. Rules of prescriptive grammar make statements about how people
ought to use language. In contrast, rules of descriptive grammar have
the status of scientific observations, and they are intended as
insightful generalizations about the way that human language is used in
fact, rather than about how it ought to be used. Descriptive rules are
more general and more basic than prescriptive rules in the sense that
all sentences of a language are formed in accordance with them, not just
the subset of sentences that count as correct or socially acceptable. A
useful way to think about prescriptive rules is as filtering out some
(relatively minute) portion of the entire output of the descriptive
rules of a language.
In syntax, as in linguistics more generally, we adopt a resolutely
descriptive perspective concerning language. In particular, when linguists
say that a sentence is grammatical, we don't mean that it is
correct from a prescriptive point of view, but that it conforms to
descriptive rules like those in (5). In order to indicate that a sequence
is ungrammatical (in the descriptive sense), we prefix it with an asterisk.
Grammatical sentences are usually not specially marked, but they can be
prefixed with 'ok' for clarity. These conventions are illustrated in (6)
and (7).
| (6)
| a.
| *
| Over there is guy the who I went to party the with.
| (= (4a))
|
|
| b.
| *
| Over there is the who I went to the party with guy.
| (= (4b))
|
| (7)
| a.
| ok
| Over there is the guy who I went to the party with.
| (= (3a))
|
|
| b.
| ok
| Over there is the guy with whom I went to the party.
|
|
Prescriptive grammar is based on the view that
there is a right way to do things and a wrong way to do things. When
there is more than one way of saying something, prescriptive grammar is
often concerned with declaring one (and only one) of the variants to be
correct, and the favored variant is usually justified as being better
(whether more logical, more euphonious, or more desirable on some other
grounds) than the deprecated variant. In the same situation of
linguistic variability, the basic aim of descriptive grammar is simply
to document the variants without passing judgment on them. For
instance, consider the variable subject-verb agreement pattern in (8).
In (8a), the singular verb is (contracted to 's) agrees in
number with the preverbal expletive subject
there (in red), whereas in (8b), the plural verb are
agrees with the postverbal logical subject some boxes (in blue).
The color of the verb indicates which of the two subjects it agrees
with.
| (8)
| a.
|
| There
| 's
| some boxes left on the porch.
|
|
| b.
|
| There
| are
| some boxes left on the porch.
|
The prescriptive and descriptive rules concerning this pattern are
given in (9). The differences between the two rules are emphasized by
underlining.
| (9)
|
| In a sentence containing both the singular expletive subject
there and a plural logical subject ...
|
|
| a.
| Prescriptive rule:
|
| ... the verb should agree in number with the logical subject.
|
|
| b.
| Descriptive rule:
|
| ... the verb can agree in number with either the expletive
subject or with the logical subject.
|
To take another example, let's consider the prescriptive rule that
says, "Don't end a sentence with a preposition."2 A prescriptivist might argue that keeping
the preposition (in italics) together with its object (in boldface), as
in (10a), makes sentences easier to understand, than does separating the
two, as in (10b).
| (10)
| a.
|
| With which friend did you go to the party?
|
|
| b.
|
| Which friend did you go to the party with?
|
But by that token, (11a), where the verb and its object are kept
together, ought to be preferable over (11b), where they are separated.
In fact, however, (11a) is completely ungrammatical.
| (11)
| a.
| *
| Adopt which cat did your friend?
|
|
| b.
| ok
| Which cat did your friend adopt?
|
It is important to understand that there is no conceptual or
semantic reason that prepositions can be separated from their objects in
English, but that verbs can't. From a descriptive perspective, the
grammaticality contrast between (10a) and (11a) is simply a matter of
fact, irreducible to more basic considerations given our present state
of knowledge. (12) highlights the difference between the relevant
prescriptive and descriptive rules.
| (12)
|
| When the object of a preposition appears in a position that
isn't its ordinary one (as in a question), ...
|
|
| a.
| Prescriptive rule:
|
| ... it should be preceded by the preposition.
|
|
| b.
| Descriptive rule:
|
| ... it can either be preceded by the preposition, or it may
stand alone, with the preposition remaining in its ordinary position.
|
The contrasting attitude of prescriptive and descriptive grammar
towards linguistic variation has a quasi-paradoxical consequence:
namely, that prescriptive rules are never descriptive rules. The reason
for this has to do with the way that social systems (not just language)
work. If everyone in a community consistently behaves in a way that is
socially acceptable in some respect, then there is no need for explicit
prescriptive rules to ensure the behavior in question. It is only when
behavior that is perceived as socially unacceptable becomes common that
prescriptive rules come to be formulated to check the unacceptable
behavior. For example, if every customer entering a store invariably
wears both a shirt and shoes, there is no need for the store owner to
put up the sign that says "No shirt, no shoes, no service." Conversely,
it is precisely at illegal dump sites that "No dumping" signs are
posted. In an analogous way, in the domain of language use, rules of
prescriptive grammar are only ever formulated in situations where
linguistic variation is common. But because they are prescriptive, they
cannot treat all of the occurring variants as equal, with the result
that they can't ever be descriptive.
Rule formation in language acquisition
In addition to differing in intention, prescriptive and descriptive rules
of grammar differ in another respect as well: namely, in how they come to
be part of a speaker's knowledge. Prescriptive rules are taught at school,
and because they are taught explicitly, people tend to be conscious of
them, even if they don't actually follow them. By contrast, we follow the
rules of descriptive grammar consistently3
and effortlessly, yet without learning them at school. In fact, children
have essentially mastered these rules on their own by first grade.
Ordinarily, we are completely unconscious of the descriptive rules of
language. If we do become conscious of them, it tends to be in connection
with learning a foreign language whose descriptive grammar differs from
that of our first language. In order to emphasize the difference between
the unconscious way that we learn a native language (or several) in early
childhood and the conscious way that we learn a foreign language later on
in life, the first process is often called language acquisition
rather than language learning.
As you consider the descriptive rules
in (5), you might not find it all that surprising that a child
raised in an English-speaking community would acquire the rule, say,
that articles precede nouns. After all, you might say, all the child
ever hears are articles and nouns in that order.4 So why would it ever occur to an
English-speaking child to put the article and the noun in the other
order? Isn't it just common sense that children learn their native
language by imitating older speakers around them?
Well, yes and no. It is true that children learn some aspects of their
native language by imitation and memorization. Children in
English-speaking communities learn English words, children in
Navajo-speaking communities learn Navajo words, children in
Swahili-speaking communities learn Swahili words, and so on. But language
acquisition isn't purely a process of memorization. In fact, given current
human life spans, it couldn't possibly be!
A thought experiment
To see this, let's consider a toy fragment of English that contains
three-word sentences consisting of a noun, a transitive verb, and
another noun. The toy fragment contains sentences like (13) that are
sensible given the real world as well as sentences like (14) that
aren't, but that might be useful in fairy tale or science fiction
contexts.
| (13)
| a.
|
| Cats detest peas.
|
| (14)
| a.
|
| Peas detest cats. ("The secret life of peas")
|
|
| b.
|
| Children eat tomatoes.
|
|
| b.
|
| Tomatoes eat children. ("The attack of the genetically modified tomatoes")
|
|
| c.
|
| Cheetahs chase gazelles.
|
|
| c.
|
| Gazelles chase cheetahs. ("Gazelle's revenge")
|
Again for the sake of argument, let's assume a (small) vocabulary of
1,000 nouns and 100 verbs. This gives us a list of 1,000 x 100 x 1,000
(= 100 million) three-word sentences of the type in (13)
and (14). Numbers of this magnitude are difficult to put in human
perspective, so let's estimate how long it would take a child to learn
all the sentences on the list. Again, for the sake of argument, let's
assume that children can memorize sentences very quickly, at a rate of
one sentence a second. The entire list of three-word sentences could
then be memorized in 100 million seconds, which comes to 3.17 years.
This may not sound like such a long time, but once we start adding
vocabulary items, the number of sentences and the time that would have
to be spent memorizing them quickly mushrooms. For instance, adding
only 10 adjectives to the child's vocabulary would cause the number of
five-word sentences of the form in (15) to grow to 10 billion (100
million x 10 x 10).
| (15)
| a.
|
| Black cats detest green peas.
|
|
| b.
|
| Happy children eat ripe tomatoes.
|
|
| c.
|
| Hungry cheetahs chase fleet gazelles.
|
Even at the very quick rate of one sentence per second that we're
assuming, the list of all such five-word sentences would take a bit over
317 years to learn. Clearly, this is an absurd consequence. For
instance, how could our memorious child ever come to know, as we plainly
do, that the sentence in (16) is ungrammatical? If grammatical
knowledge were based purely on rote memorization, the only way to
determine this would be to compare (16) to all of the 10 billion
five-word sentences and to find that it matches none of them, which
would take additional centuries beyond the time required to memorize the
sentences.
| (16)
| *
| Cats black detest peas green.
|
And even after all that time, our fictitious language learner still
wouldn't have the faintest clue of why (16) is ungrammatical!
In addition to this thought experiment with its comically absurd
consequences, there is another reason to think that language acquisition
isn't entirely based on rote memorization---namely, that children use what
they hear of language as raw material to construct linguistic rules. How
do we know this? We know because children sometimes produce rule-based
forms that they have never heard before.
Rule-based word formation
One of the earliest demonstrations that children acquire linguistic
rules, rather than simply imitating the forms of adult language, was the
well-known wug experiment (Berko 1958). In
it, the psycholinguist Jean Berko used invented words to examine (among
other things) how children between the ages of 4 and 7 form plurals in
English. She showed the children cards with simple line drawings of
objects and animals and elicited plurals from them by reading them
accompanying texts like the one in (17).
| (17)
|
|
| This is a wug. Now there is another one. There are two of them.
There are two ___.
|
More than 75% of the children pluralized the invented words
cra, lun, tor, and wug in exactly the same
way that adults did in a control group: they added the sound -z
to the word (Berko 1958:159-162).5 Since none of the children had
encountered the invented words before the experiment, their response
clearly indicates that they had acquired a plural rule and were using it
to produce the novel forms.
In the wug experiment, both the children being studied and
the adults in the control group produced novel rule-based forms.
Children are also observed to produce novel rule-based forms like
comed or goed instead of existing irregular adult forms,
like came for went. This process is known as
overregularization. Some further instances are given in (18)
(Marcus et al. 1992:148-149,
based on Brown 1973).
| (18)
| a.
|
| beated, blowed, catched, cutted, doed, drawed, drived, falled,
feeled, growed, holded, maked, sleeped, standed, sticked, taked,
teached, throwed, waked, winned
(Adam, between the ages of 2 and 5)
|
|
| b.
|
| drinked, seed, weared
(Eve, between the ages of 1 1/2 and 2)
|
Overregularizations don't amount to a large fraction of the forms
that children produce overall (less than 5% in the case of past tense
forms, according to Marcus et al.
1992:35), but they clearly show that even the acquisition of words
doesn't boil down to rote memorization.
Question formation
In addition to morphological rules (which concern the structure of
words), children also acquire syntactic rules (which concern the
structure of sentences). Some of these rules are of particular interest
children form them on their own. At the same time, however, these novel
rules don't differ in arbitrary ways from the adult rules that the
children acquire eventually. Rather, the children's rules share certain
abstract properties with the adult rules, even when they differ from
them.
To see this, let's consider how young children form yes-no questions
(as the name implies, yes-no questions are ones to which the expected
answer is either 'yes' or 'no'). Some 3- to 5-year-olds form such
questions from declarative sentences by copying the auxiliary element to
the beginning of the sentence, as in (19) (Crain
and Nakayama 1987:536). (We use the term 'auxiliary element' as a
convenient way of referring to be, can and other similar
elements which invert with the subject in (adult) English questions.
See Modals and auxiliary verbs in English
for more details.)
| (19)
| a.
|
| The girl is tall.
| --->
| Is the girl is tall?
|
|
| b.
|
| The red pig can stand on the house.
| --->
| Can the red pig can stand on the house?
|
In the course of language acquisition, the questions in (19) give way
to those in (20), where we can think of the auxiliary element as having
been moved rather than copied.
| (20)
| a.
|
| Is the girl ___ tall?
|
|
| b.
|
| Can the red pig ___ stand on the house?
|
But now notice a striking indeterminacy, first pointed out by
Chomsky 1971:26-27. When children produce questions
like those in (20), there is no way of telling whether they are using the
adult rule for question formation in (21a) or the logically possible
alternative rule in (21b).
| (21)
| a.
|
| Adult question formation rule:
| To form a question from a declarative sentence containing an auxiliary
element, find the subject of the sentence, and
invert the subject and the auxiliary.
|
|
| b.
|
| Logically possible alternative:
| To form a question from a declarative sentence containing an auxiliary
element, find the first auxiliary element, and move it to the
beginning of the sentence.
|

| Don't confuse 'subject' with 'simple subject.'
Subjects, in contrast to simple subjects, are possible responses to
questions like Who is tall? and Who can stand on the
house? So the subjects in (20) are the noun phrases the girl
and the red pig.
If the subject consists of a single word or of a clause, then the
simple subject is identical to the subject; otherwise, the simple
subject of a sentence is obtained by stripping the subject of any
modifiers (yielding girl and pig as the simple subjects
of (20)).
The notion of subject is basic to syntactic theory, but we will have
no further use for the notion of simple subject.
|
Both rules in (21) give the same result for simple sentences, which
are likely to form most of the data that young children attend to. Both
rules also require children to identify auxiliary elements. However,
the adult rule additionally requires children to identify the subject of
the sentence by grouping together sequences of words such as the
girl or the red pig into a single abstract structural unit.
Because of this grouping requirement, the adult rule is called
structure-dependent. By contrast, the rule in (21b) is not
structure-dependent, since it requires the child only to classify words
according to their syntactic category, but not to group them into
structural units. The rule in (21b) is simpler in the sense that it
relies on fewer cognitive operations as well as computationally less
complex ones, and children might reasonably be expected to experiment
with it in the course of acquiring question formation. Nevertheless,
Chomsky 1971 predicted that children would use only
structure-dependent rules in the course of acquisition.
As we mentioned, both rules give the same result for simple
sentences. So how could we possibly tell which of the two rules a child
was actually using? Well, forming yes-no questions is not restricted to
simple sentences. So although we can't tell which rule a child is using
in the case of simple sentences, the rules in (21) give different
results for complex sentences like (22), where the entire sentence
contains a relative clause. For the question at hand, what is relevant
is that the entire sentence contains the auxiliary is, and that,
in addition, there is a relative clause (who was holding the plate),
which contains a second auxiliary was.
|
| (22)
|
|
| The boy who was holding the plate is crying.
|
A child applying the structure-dependent question formation rule to
(22) would first identify the subject of the entire sentence (the boy
who was holding the plate) and then invert the entire
subject---including the relative clause and the auxiliary contained
within it (was)---with the auxiliary of the entire sentence
(is). On the other hand, a child applying the
structure-independent rule would identify the first auxiliary
(was) and move it to the beginning of the sentence. In this
case, the two rules have very different results, as shown in (23).
| (23)
| a.
|
| Structure-dependent rule:
| [ The boy who was holding the plate ] is crying.
| --->
| Is [the boy who was holding the plate] ___ crying?
|
|
| b.
|
| Structure-independent rule:
| The boy who was holding the plate is crying.
| --->
| Was the boy who ___ holding the plate is crying?
|
Recall that Chomsky predicted that children would not use
structure-independent rules, even though they are simpler than
structure-dependent ones. This prediction was tested in an experiment with
3- to 5-year-old children by Crain and Nakayama
1987. In the experiment, the experimenter had the children pose
yes-no questions to a doll (Jabba the Hut from Star Wars). For
instance, the experimenter would say to each child Ask Jabba if the boy
who was holding the plate is crying. This task elicited various
responses. Some children produced the adult question in (23a), whereas
others produced the copy question in (24a) or the restart question in
(24b).
| (24)
| a.
|
| Is [the boy who was holding the plate] is crying?
|
|
| b.
|
| Is [the boy who was holding the plate], is he crying?
|
Notice that although neither of the questions in (24) uses the adult
rule in (21a), the rules that the children used to produce them are
structure-dependent in the same way that the adult rule is. This is
because children who produced (24a) or (24b) must have identified the
subject of the sentence, just like the children who produced (23a). What
is also noteworthy is that out of the 155 questions that the children
produced, none were of the structure-independent type in (23b). Moreover,
no child produced the structure-independent counterpart of (24a), shown in
(25), which results from copying (rather than moving) the first auxiliary
element in the sentence.
| (25)
|
|
| Was the boy who was holding the plate is crying?
|
In other words, regardless of whether a child succeeded in producing
the adult question in (23a), every child in the experiment treated the
sequence the boy who was holding the plate as a unit, thus
confirming Chomsky's prediction.
Syntactic structure
We have seen that young children are capable of forming and applying
both morphological and syntactic rules. Moreover, as we have seen in
connection with question formation, children do not all immediately adopt
the rules that adults use. Nevertheless, the syntactic rules that children
postulate in the course of acquisition are a subset of the logically
possible rules that they might experiment with in principle. In
particular, children's syntactic rules are constrained, as we have just
seen, by structure dependence. Another way of putting this is that the
objects that syntactic rules operate on (declarative sentences in the case
of the question formation rule) are not just simple strings of words, but
rather groups of words that belong together, so-called constituents.
Intuitions about words belonging together
Evidence for syntactic constituent structure, often simply
called syntactic structure, isn't restricted to data from child
language acquisition. Further evidence comes from the intuitions that
adults (and even children) have that certain words in a sentence belong
together, whereas others do not. For instance, in a sentence like (26), we
have the strong intuition that the first the belongs with
dog, but not with did, even though the is adjacent to
both.
| (26)
|
|
| Did the dog chase the cat?
|
Similarly, the second the in (26) belongs with cat and
not with chase. But a word doesn't always belong with the following
word. For instance, in (27), the first the belongs with dog,
just as in (26), but dog doesn't in turn belongs with the second
the.
| (27)
|
|
| Did the dog the children like chase the cat?
|
Words that belong together can sometimes be replaced by placeholder
elements such as pronouns. This is illustrated in (28).
|
| The term 'pronoun' is misleading since it suggests that pronouns
substitute for nouns regardless of syntactic context. In fact, what
pronouns substitute for is entire noun phrases (as will be discussed
in more detail in Chapter 2).
A less confusing term for them would be 'pro-noun phrase,' but we'll
continue to use the traditional term.
|
| (28)
| a.
|
| Did the dog chase the cat?
| --->
|
| Did she chase him?
|
|
| b.
|
| Did the dog the children like chase the cat?
| --->
|
| Did the dog they like chase him?
|
It's important to recognize that pronouns don't simply replace strings
of words regardless of context. Just because a string like the dog
is a constituent in (28a) doesn't mean that it's always a constituent. We
can see this by replacing the dog by a pronoun in (28b), which leads
to the ungrammatical result in (29).
| (29)
|
|
| Did the dog the children like chase the cat?
| --->
| *
| Did she the children like chase the cat?
|
The ungrammaticality in (29) tells us that the and dog
belong together less closely in (28b) than in (28a). What the pronoun
replacement evidence tells us is that the and dog combine
directly in (28a), whereas in (28b), dog combines first with the
relative clause, and the combines with the result of this
combination, not with dog directly.
In some sentences, we have the intuition that words belong together
even when they are not adjacent. For instance, see and who
in (30a) belong together in much the same way as see and Bill
do in (30b).
| (30)
| a.
|
| Who will they see?
|
|
| b.
|
| They will see Bill.
|
Finally, we can observe that there are various
sorts of ways that words can belong together. For instance, in a phrase
like the big dog, big belongs with dog, and we have
the intuition that big modifies dog. On the other
hand, the relation between saw and Bill in (30b) isn't one of
modification. Rather, we have the intuition that Bill is a
participant in a seeing event.
In the course of this book, we will introduce more precise ways of
expressing and representing intuitions like the ones just discussed. For
the moment, however, what is important is that we have strong intuitions
that words belong together in ways that go beyond adjacency.
Structural ambiguity
Another, particularly striking piece of evidence for the existence of
syntactic structure is the phenomenon of structural ambiguity.
The classified advertisement in (31) is a humorous illustration.
| (31)
|
|
| Wanted: Man to take care of cow that does not smoke or drink.
|
World knowledge tells us that the intent of the advertiser is to hire a
clean-living man to take care of a cow. But because of the way the
advertisement is formulated, it also has an unintentionally comical
interpretation---namely, that the advertiser has a cow that does not smoke
or drink and that a man is wanted to take care of this clean-living cow.
The intended and unintended interpretations describe sharply different
situations; that is why we say that (31) is ambiguous, and not merely that
it is vague. Moreover, the ambiguity of the sentence can't be pinned on a
particular word, as it can be in the ambiguous sentences in (32).
| (32)
| a.
|
| As far as I'm concerned, any gender is a drag. (Patti Smith)
|
|
| b.
|
| Our bikinis are exciting. They are simply the tops.
|
Examples like (32) are called instances of
lexical ambiguity, because their ambiguity
comes from their containing a lexeme (= vocabulary item)
with two distinct meanings. In (31), on the other hand, the words
themselves have the same meanings in each of the two interpretations,
and the ambiguity comes from the possibility of grouping the words in
distinct ways. In the intended interpretation, the relative clause
that does not smoke or drink modifies man; in the
unintended interpretation, it modifies cow.
To avoid any confusion, we should emphasize that we are here
considering structural ambiguity from a purely descriptive perspective,
focusing on what it tells us about the design features of human language
and disregarding the practical aim of effective communication. As
writers of advertisements ourselves, of course, we would be careful not
to use (31), but to disambiguate it by means of an appropriate
paraphrase. For the ordinary interpretation of (31), where the
relative clause modifies man, we would place the relative clause
next to the intended modifiee, as in (33a). The comical interpretation
of (31), on the other hand, cannot be expressed unambiguously by moving
the relative clause. If it were the desired interpretation, we would
have to resort to a more drastic reformulation, such as (33b).
| (33)
| a.
|
| Wanted: Man that does not smoke or drink to take care of cow.
|
|
| b.
|
| Wanted: Man to take care of nonsmoking, nondrinking cow.
|
Universal Grammar
Formal universals
The structure dependence of linguistic rules is a general principle
of the human language faculty (the part of the mind/brain that
is devoted to language), often also referred to as Universal
Grammar, especially when considered in abstraction from any
particular language. There are two sources of evidence for this.
First, as we have seen, the syntactic rules that children form in the
course of acquiring their first language, even when they are not the
rules that adults use, are structure-dependent. Second, even though
structure-independent rules are logically possible and computationally
tractable, no known human language actually has rules that disregard
syntactic structure. For instance, no known human language has either
of the computationally very simple question formation rules in (34).
| (34)
| a.
|
| To form a question, switch the order of the first and second words in
the corresponding declarative sentence.
| The girl is tall.
| --->
| Girl the is tall?
|
|
| The blond girl is tall.
| --->
| Blond the girl is tall?
|
|
| b.
|
| To form a question, reverse the order of the words in the corresponding
declarative sentence.
| The girl is tall.
| --->
| Tall is girl the?
|
|
| The blond girl is tall.
| --->
| Tall is girl blond the?
|
The structure dependence of linguistic
rules is what is known as a formal universal of human language---a
principle shared by all human languages that is independent of the meanings
of words. Formal universals are distinguished from substantive
universals, which concern the substance, or meaning, of linguistic
elements. An example of a substantive universal is the fact that all
languages have indexical elements such as I, here,
and now. These words have the special property that their meanings
are predictable in the sense that they denote the speaker, the speaker's
location, and the time of speaking, but that what they refer to varies
depending on who the speaker is.
Recursion
Human language exhibits another formal universal: the property of
recursion. A simple illustration of this property is the fact that
it is possible for one sentence to contain another. For instance, the
simple sentence in (35a) forms part of the complex sentence in (35b), and
the resulting sentence can form part of a still more complex sentence.
Recursive embedding is illustrated in (35) up to a level of five
embeddings.
| (35)
| a.
|
| She won.
|
|
| b.
|
| The Times reported that
[she won].
|
|
| c.
|
| John told me that
[the Times reported that
[she won]].
|
|
| d.
|
| I remember distinctly that
[John told me that
[the Times reported that
[she won]]].
|
|
| e.
|
| They don't believe that
[I remember distinctly that
[John told me that
[the Times reported that
[she won]]]].
|
|
| f.
|
| I suspect that
[they don't believe that
[I remember distinctly that
[John told me that
[the Times reported that
[she won]]]]].
|
Parameters
Formal universals like the structure dependence of linguistic rules and
recursion are of particular interest to linguistics in the Chomskyan
tradition. This is not to deny, however, that individual languages also
differ from one another, and not just in the sense that their
vocabularies differ. This means that Universal Grammar is not
completely fixed, but allows some variation. The ways in which the
grammars of languages can differ are called parameters.
One simple parameter concerns the order of verbs and their objects. In
principle, two orders are possible: verb-object (VO) or object-verb (VO),
and different human languages use either one or the other. As illustrated
in (36) and (37), English and French are languages of the verb-object (VO)
type, whereas Hindi, Japanese, and Korean are languages of the object-verb
(OV) type.
| (36)
| a.
| English
|
| Peter read the book.
|
|
| b.
| French
|
|
Pierre lisait le livre.
Pierre was.reading the book
'Pierre was reading the book.'
|
| (37)
| a.
| Hindi
|
|
Peter-ne kitaab parh-ii.
|
|
| b.
| Japanese
|
|
Peter-ga hon-o yon-da.
|
|
| c.
| Korean
|
|
Peter-ka chayk-ul il-ess-ta.
Peter book read
'Peter read the book.'
|
Another parameter of
Universal Grammar concerns the possibility, mentioned earlier, of
separating a preposition from its object, or preposition
stranding. (The idea behind the metaphor is that the movement of the
object of the preposition away from its ordinary position leaves the
preposition stranded high and dry.) The alternative to preposition
stranding goes by the name of pied piping, by analogy to the Pied
Piper of Hameln, who took revenge on the citizens of Hameln for mistreating
him by luring the town's children away with him.6 In pied piping of the syntactic sort, the
object of the preposition moves away from its usual position, just as in
preposition stranding, but it lures the preposition along with it. An
example of each parametric option is given in (38).
| (38)
| a.
| Preposition stranding:
| ok
| Which house does your friend live in?
|
|
| b.
| Pied piping:
| ok
| In which house does your friend live?
|
Just as in English, preposition stranding and pied piping are both
grammatical in Swedish. In fact, in Swedish, preposition stranding counts
as prescriptively correct, and it is pied piping that is frowned upon, on
the grounds that it sounds stiff and artificial.
| (39)
| a.
| Swedish
| ok
|
Vilket hus bor din kompis i?
which house lives your friend in
'Which house does your friend live in?'
|
|
| b.
|
| ok
| I vilket hus bor din kompis?
|
On the other hand, preposition stranding is completely ungrammatical
in French and Italian. Speakers of these languages reject examples like
(40) as word salad, and accept only pied-piping examples, as in (41).
| (40)
| a.
| French
| *
|
Quelle maison est-ce que ton ami habite dans?
which house is it that your friend lives in
Intended meaning: 'Which house does your friend live in?'
|
|
| b.
| Italian
| *
|
Quale casa abita il tuo amico in?
which house lives the your friend in
Intended meaning: 'Which house does your friend live in?'
|
| (41)
| a.
| French
| ok
| Dans quelle maison est-ce que ton ami habite?
|
|
| b.
| Italian
| ok
| In quale casa abita il tuo amico?
|
Generative grammar
At the beginning of this chapter, we said that this book was an
introduction to generative grammar from a Chomskyan perspective. Until
now, we have clarified our use of the term 'grammar,' and we have indicated
that a Chomskyan perspective on grammar is concerned with the formal
principles that all languages share as well as with the parameters that
distinguish them. Let's now turn to the notion of a generative grammar.
| (42)
|
|
| A generative grammar is an algorithm for specifying,
or generating, all and only the grammatical sentences in a
language.
|
What's an algorithm? It's simply any explicit, step-by-step
procedure for accomplishing a task. Computer programs are the
algorithms par excellence. More ordinary examples of algorithms include
a recipe for sushi, a knitting pattern, the instructions for assembling
an Ikea bookcase, or the steps on the back of your bank statement for
balancing your checkbook.
An important point to keep in mind is that it is often difficult to
construct an algorithm for even a seemingly trivial procedure. A quick way
to gain an appreciation of this is to describe how to tie a bow. Like
language, tying a bow is a skill that we've mastered around school age, and
that we perform more or less unconsciously thereafter, but describing (not
demonstrating) how to do it is anything but easy. In an analogous way,
constructing a generative grammar of English is a completely different task
than speaking the language, and much more difficult (or at least difficult
in a different way)!
Just like a cooking recipe, a generative grammar needs to specify the
ingredients and procedures that are necessary for generating grammatical
sentences. We won't introduce all of these in this first chapter, but in
the remainder of the section, we'll introduce enough ingredients and
procedures to give a flavor of what's to come.
Elementary trees and substitution
The raw ingredients that sentences consist of are vocabulary
items. These belong to various syntactic categories, like
noun, adjective, transitive verb, preposition, and so forth. Depending
on their syntactic category, vocabulary items combine with one another
to form constituents, which in turn belong to syntactic categories of
their own. For instance, determiners (a category that includes the
articles a and the and the demonstratives this, that,
these and those) can combine with nouns to form noun phrases,
but they can't combine with other syntactic categories like adverbs,
verbs, or prepositions.
| (43)
| a.
| ok
| a house
| (44)
| a.
| *
| a slowly
|
|
| b.
| ok
| the cats
|
| b.
| *
| the went
|
|
| c.
| ok
| those books
|
| c.
| *
| those of
|
It's possible to represent the information contained in a constituent
by using labeled bracketings. Each vocabulary item is enclosed in
brackets that are labeled with the appropriate syntactic category. The
constituent that results from combining vocabulary items is in turn
enclosed in brackets that are labeled with the constituent's syntactic
category. The labeled bracketings for the constituents in (43) are given
in (45).
| (45)
| a.
|
| [NounPhr [Deta ]
[Noun house ] ]
|
|
| b.
|
| [NounPhr [Detthe ]
[Noun cats ] ]
|
|
| c.
|
| [NounPhr [Detthose ]
[Noun books ] ]
|
Noun phrases can in turn combine with other syntactic categories, such
as prepositions or transitive verbs. Prepositions combine with a single
noun phrase to form prepositional phrases. A transitive verb combines with
one noun phrase to form a verb phrase, which in turn combines with a second
noun phrase to form a complete sentence.
| (46)
| a.
|
| [PrepPhr [Prep on ]
[NounPhr [Detthe ]
[Noun table ] ] ]
|
| b.
|
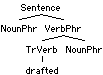
| [VerbPhr [TrVerb drafted ]
[NounPhr [Deta ]
[Noun letter ] ] ]
|
| c.
|
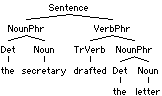
| [Sentence
[NounPhr [Detthe ]
[Noun secretary ] ]
[VerbPhr [TrVerb drafted ]
[NounPhr [Deta ]
[Noun letter ] ] ] ]
| | |
Again, however, noun phrases don't combine with any and all syntactic
categories. For instance, noun phrases can't combine with adverbs or
determiners.
| (47)
| a.
| *
| slowly the letter
|
|
| b.
| *
| the this letter
|
As constituent structure grows more complex, labeled bracketings very
quickly grow difficult for humans to process. Because of this, it's often
more convenient to use an alternative mode of representing constituent
structure called tree diagrams, or trees for short.
Trees convey exactly the same information as labeled bracketings, but the
information is presented differently. Instead of enclosing an element in
brackets that are labeled with a syntactic category, the category is placed
immediately above the element and connected to it with a line or
branch. The labeled bracketings that we have seen so far translate
into the trees in (48) and (49).7
Trees like those in (48) and (49) resemble dishes that are ready to
serve; they don't provide a record of exactly how they were brought into
being. We can provide such a record, however, by representing vocabulary
items themselves in the form of trees that include combinatorial
information. For example, prepositions and transitive verbs can be
represented as trees with empty slots for noun phrases to fit into, as
shown in (50).
| (50)
| a.
|
| 
|
| b.
|
| 
|
We'll refer to trees for vocabulary items like those in (50) as
elementary trees. The purpose of elementary trees is to
represent the combinatorial possibilities of a vocabulary item, and so
they ordinarily contain unfilled nodes. Such nodes are called
substitution nodes, and they are filled by a
substitution operation, defined in (51).
| (51)
| a.
|
| 
|
| b.
|
| 
|
| c.
|
| 
|
|
| Tree No. 1 has a substitution node
of some syntactic category.
|
| The root (= topmost) node in Tree No. 2
has the same syntactic category as the substitution node
in Tree No. 1.
|
| The root node of Tree No. 2 is identified
with the substitution node in Tree No. 1.
|
Elementary trees don't necessarily contain substitution nodes, though;
ones that invariably play the role of Tree No. 2 in the
substitution operation don't. The elementary tree for the noun in (52b) is
an example.
Notice that there are two conceivable ways to arrive at trees for noun
phrases like those cats, depending on whether it is the noun that is
taken as the substitution node, as in (52), or the determiner, as in (53).
At this point, there is no reason to prefer one way over the other, but in
Chapter 5, we will argue
for a variant of (52).
In summary, a generative grammar as we've constructed it so far
consists of a set of elementary trees, which represent the vocabulary items
in a language and the range of their combinatorial possibilities, and a
substitution operation, by means of which the elementary trees combine into
larger constituents and ultimately into grammatical sentences. In Chapter 4, we will introduce two
further formal operations. The first, adjunction, will enable the
grammar to generate sentences containing modifiers, such as adjectives or
relative clauses modifying nouns (the big dog, the dog
that the children like). The second, movement, will
enable the grammar to represent the similarities as well as the differences
between declarative sentences (They will see Bill) and questions
corresponding to them (Will they see Bill?, Who(m) will they
see?).
Grammaticality
The aim of a generative grammar is to generate all and only the grammatical
sentences of a language. The notion of grammaticality is therefore basic
to syntactic theory, and so it is important to distinguish it from notions
with which it is easily confused.
First of all, 'grammatical' needs to be distinguished from 'makes
sense.' The sentences in (54) 'make sense' in the sense that they are
easily interpreted by speakers of English. Nevertheless, as indicated by
the asterisks, they are not grammatical.8
| (54)
| a.
| *
| Is our children learning?
|
|
| b.
| *
| Me wants fabric.
|
|
| c.
| *
| To where are we be taking thou, sir?
|
|
| d.
| *
| The introduction explained that "the Genoese people, besides of hard
worker, are good eater too, and even 'gourmand,' of that honest
gourmandise which will not drive a man to hell but which is, after
all, one of the few pleasures that mankind can enjoy in this often
sorrowful world."
|
Conversely, there are English sentences that are grammatical, but that
don't 'make sense.' The 'fairy tale' or 'science fiction' sentences in
(14) are of this type. Two further examples are given in (55). Since such
sentences are grammatical, they aren't preceded by an asterisk. However,
if necessary, a prefixed pound sign is used to indicate their
meaning-related anomaly.
| (55)
| a.
| #
| Colorless green ideas sleep furiously.
(Chomsky 1965:149)
| cf. Revolutionary new ideas appear infrequently.
|
|
| b.
| #
| I plan to travel there last year.
| cf. I plan to travel there next year.
|
Second, 'grammatical' must be distinguished from 'easily processable by
human beings.' This is because it turns out that certain well-motivated
grammatical operations can be applied in ways that result in sentences that
are virtually impossible for human beings to process. For instance, it is
possible in English to modify a noun with a relative clause, and sentences
containing nouns modified in this way, like those in (56), are normally
perfectly acceptable and easily understood. (Here and in the following
examples, the relative clauses are bracketed and the modified noun is
underlined.)
| (56)
| a.
|
| The mouse [that the cat chased] escaped.
|
|
| b.
|
| The cat [that the dog scared] jumped out the window.
|
But now notice what happens when we modify the noun within the relative
clause in (56a) with a relative clause of its own.
| (57)
|
|
| The mouse [that the cat [that the dog scared] chased]
escaped.
|
Even though (57) differs from (56a) by only four additional words and
one additional level of embedding, the result is virtually uninterpretable
without pencil and paper. The reason is not that relative clause
modification can't be applied more than once, since the variant of (56a) in
(58), which contains exactly the same words and is exactly as long, is
perfectly fine.
| (58)
|
|
| The mouse escaped [that the cat chased ] [that the dog
scared].
|
Rather, the unacceptability of (57) has to do with limitations on human
short-term memory (Chomsky and Miller 1963:286,
Miller and Chomsky 1963:471). Specifically,
notice that in the acceptable (58), the subject of the main clause the
mouse doesn't have to "wait" (that is, be kept active in short-term
memory) for its verb escaped since the verb is immediately adjacent
to the subject. The same is true for the subjects and verbs of each of the
relative clauses (the cat and chased, and the dog and
scared). In (57), on the other hand, the mouse must be kept
active in memory, waiting for its verb escaped, for the length of
the entire sentence. What is even worse, however, is that the period
during which the mouse is waiting for escaped overlaps with
the period during which the cat must be kept active, waiting for its
verb chased. What makes (57) so difficult, then, is not the mere
fact of recursion, but that two relations of exactly the same sort (the
subject-verb relation) must be kept active in memory at the same time. In
none of the other relative clause sentences is such double activation
necessary. For instance, in (56a), the mouse must be kept active
for the length of the relative clause, but the subject of the relative
clause (the cat) needn't be kept active since it immediately
precedes its verb chased.
A final point to bear in mind is that any sentence of a language is
an expression (specifically, a sequence of words) that is paired with a
particular interpretation. Grammaticality is always determined with
respect to such pairings of form and meaning. This means that a
particular sequence can be grammatical under one interpretation, but not
under another. For instance, (59) is ungrammatical under an
subject-object-verb (SOV) interpretation (that is, when the sentence is
interpreted as Sue hired Tom).
(59) is grammatical, however, under an object-subject-verb (OSV)
interpretation (that is, when it is interpreted as Tom hired Sue;
cf. Sue, Tom hired; Tim, he insulted). On this interpretation,
Sue receives a special intonation that marks contrast, which
would ordinarily be indicated in writing by setting off Sue from
the rest of the sentence by a comma. In other words, the grammaticality
of (59) depends on whether its interpretation is analogous to (60a) or
(60b).
| (60)
| a.
| ok
| Her, he hired. (The other job candidates, he didn't even call back.)
|
|
| b.
| *
| She him hired.
|
Grammar versus language
We conclude this chapter by considering the relationship between the two
concepts of grammar and language. The notion of language seems
straightforward because we are used to thinking and speaking of "the
English language," "the French language," "the Chinese language," and so
forth. But these terms are actually much vaguer than they seem at first
glance because they cover a plethora of varieties, including ones that
differ enough to be mutually unintelligible. For instance, Ethnologue
distinguishes 32 dialects of English in
the British Isles alone. In addition, distinct dialects of English are
spoken in former British colonies, including Canada, the United States,
Australia, New Zealand, India, and many African, Asian, and Caribbean
nations, and many of these dialects have subdialects of their own.
Similarly, Ethnologue distinguishes 13 dialects of French, not
counting colonial varieties. Chinese is divided into 13 major dialects as
well, which in turn encompass 50 subdialects, many of them mutually
unintelligible. Moreover, we use terms like "the English language" to
refer to historical varieties that differ as profoundly as present-day
English does from Old English, which is about as intelligible to a speaker
of modern English as German (in other words, not very).
Although the most salient differences between dialects are often
phonological (that is, speakers of different dialects often have different
accents), dialects of a so-called single language can differ syntactically
as well. For instance, in standard French, as in the Romance languages
more generally, adjectives ordinarily follow the noun that they modify.
But that order is reversed in Walloon, a French dialect spoken in Belgium.
The two parametric options are illustrated in (61)
(Bernstein 1993:25-26).
| (61)
| a.
|
| Standard French
|
un chapeau noir
a hat black
|
| b.
|
| Walloon
|
on neûr tchapê
a black hat
'a black hat'
| |
Another example of the same sort, though considerably more cathected
for speakers of English, concerns multiple negation in sentences like (62a).
| (62)
| a.
|
| The kids didn't eat nothing.
|
|
| b.
|
| The kids didn't eat anything.
|
In present-day standard English, didn't and nothing each
contribute their negative force to the sentence, and the overall force of
(62a) isn't negative; rather, the sentence means that the kids ate
something. In many nonstandard varieties of English, however, (62a)
conveys exactly the same meaning as standard English (62b); that is, the
sentence as a whole has negative force. In these dialects, we can think of
the negation in nothing as agreeing with (and reinforcing) the
negation in didn't rather than cancelling it; hence the term
negative concord for this phenomenon ('concord' is a variant term
for 'agreement'). Negative concord is routinely characterized as
"illogical" by prescriptivists,9 and it is
one of the most heavily stigmatized features in present-day English.10 However, it was productive in earlier forms
of English, and it is attested in renowned masters of the language such as
Chaucer and Shakespeare. Moreover, negative concord is part of the
standard forms of languages like French, Italian, Spanish, and modern
Greek. From a descriptive and generative point of view, negative concord
is simply a parametric option just like any other, and negative concord is
no more illogical than the noun-adjective order in (61a).
In both of the examples just discussed, we have dialects of the "same
language" (English and French, respectively) differing with respect to a
parameter. The converse is also possible: two "different languages" that
are parametrically (all but) indistinguishable. For example, the same
linguistic variety spoken on the Dutch-German border may count as a dialect
of Dutch or German depending on which side of the political border it is
spoken. An analogous situation holds of many other border dialects.
According to Max Weinreich, "a language is a dialect with an army and a
navy." A striking (and sad) confirmation of this aphorism concerns the
recent terminological history of Serbo-Croatian. When Yugoslavia was a
federal state under Tito, this variety was considered a single language
with a number of regional dialects. The breakup of Yugoslavia into several
smaller states has brought with it attempts to introduce a distinction
between Serbian and Croatian as two separate "languages."
As the previous discussion has shown, the notion of "language" is based
more on sociopolitical considerations than on strictly linguistic ones. By
contrast, the term "grammar" refers to a particular set of parametric
options that a speaker acquires. For this reason, the distinction between
language and grammar that we have been drawing has been referred to as the
distinction between E-language and I-language (mnemomic
for 'external' and 'internal' language) (Chomsky
1986).
As we have seen, the same language label can be associated with more
than one grammar (as in the case of English with and without negative
concord), and a single grammar can be associated with more than one
language label (as in the case of border dialects). It is important to
distinguish the concept of shared grammar from mutual intelligibility. To
a large extent, standard English and many of its nonstandard varieties are
mutually intelligible even where their grammars differ. On the other hand,
it is perfectly possible for two or more varieties that are mutually
unintelligible to share a single grammar. For instance, in the Indian
village of Kupwar (Gumperz and Wilson 1971),
the three languages Marathi, Urdu, and Kannada, each spoken by a different
ethnic group, have been in contact for about four hundred years, and most
of the men in the village are bi- or trilingual. Like the standard
varieties of these language, their Kupwar varieties have distinct
vocabularies, thus rendering them mutually unintelligible, but in Kupwar,
the considerable grammatical differences that exists among the languages as
spoken in other parts of India have been virtually eliminated. The
difference between standard French and Walloon with respect to prenominal
adjectives is a less drastic instance of this same convergence phenomenon.
Here, too, the adjective-noun order in Walloon is due to language contact,
in this case between French and Flemish, the other language spoken in
Belgium; in Flemish, as in the Germanic languages more generally,
adjectives precede the nouns that they modify.
Finally, it is worth noting that it is perfectly possible for a single
speaker to acquire more than one grammar. This is most strikingly evident
in balanced bilinguals. Speakers can also acquire more than one grammar in
situations of syntactic change. For instance, late Old English and Middle
English went from being object-verb (OV) languages to being verb-object
(VO) languages, and individual speakers during the transition period
acquired and used both parametric options. Finally, speakers can acquire
more than one grammar in situations of stable variation between
parametrically distinct varieties of a single "language." For instance,
English speakers whose first dialect is a negative concord dialect might
acquire the standard non-negative concord dialect in the course of their
schooling.
Notes
1. It's also possible to
overzealously apply rules like those in (2), even in cases where they
shouldn't be applied, a phenomenon known as
hypercorrection. Two common instances are
illustrated in (i).
|
| Hypercorrect example
| Explanation
|
| (i)
| a.
|
| Over there is the guy whom I think took her to the party.
| Should be: the guy who I think took her to the party;
(the relative pronoun who is the subject of the relative
clause, not the object; cf. the guy { who,
*whom } took her to the party)
|
|
| b.
|
| This is strictly between you and I.
| Should be: between you and me
(the second pronoun is part of the object of the preposition
between, not part of a subject)
|
2. The prescriptive rule is actually
better stated as "Don't separate a preposition from its object," since the
traditional formulation invites exchanges like (i).
| (i)
|
|
| A:
| Who are you going to the party with?
|
|
|
|
| B:
| Didn't they teach you never to end a sentence with a preposition?
|
|
|
|
| A:
| Sorry, let me rephrase that. Who are you going to the party with,
Mr. Know-it-all?
|
3. As William Labov has often
pointed out, everyday speech (apart from false starts and other
self-editing phenomena) hardly ever violates the rules of descriptive
grammar.
4. Actually, that's an
oversimplification. Not all the articles and nouns an
English-speaking child hears appear in the article-noun order. To
see why, carefully consider the underlined sentence in this footnote.
5. When children didn't respond this
way, they either repeated the original
invented word, or they
didn't respond at all. It's not clear what to make of these responses.
Either response might indicate that the children were stumped by the
experimental task. Alternatively, however, repetition might have been
intended as an irregular plural (cf. deer and sheep), and
silence might indicate that the children thought that some of the
invented words were phonologically strange, as some of them (for
instance, cra) indeed are.
6. The terms 'preposition stranding' and
'pied piping' were both invented by John Robert Ross, a syntactician with a
penchant for metaphorical terminology. Ross's groundbreaking syntactic
work is discussed in Chapter 10.
7. Online corpora that are annotated
with syntactic structure, such as the Penn Treebank, the Penn-Helsinki Corpus of Middle
English, and others like them, tend to use labeled bracketing because
the resulting files consist entirely of ASCII characters and are easy to
search. They can also be massaged in more or less drastic ways by using
computer languages like PERL. The readability of such corpora for humans
can be improved by suitable formatting of the labeled bracketing itself or
by translating bracketed structures into tree diagrams.
8. (54a) is from a speech by
George W. Bush in Florence, SC on January 11, 2000 (http://politicalhumor.about.com/library/blbushisms2000.htm).
(54b) was the subject line of an email message in response to an offer
of free fabric; the author was humorously attempting to imitate the
language of a child greedy for goodies. (54c) is from "Pardon my
French" (Calvin Trillin. 1990. Enough's enough (and other rules of
life). 169). (54d) is from "Connoisseurs and patriots" (Joseph
Wechsberg. 1948. Blue trout and black truffles: The peregrinations of
an epicure. 127).
9. Two important references
concerning negative concord and the supposed illogicality of negative
concord and of nonstandard English more generally are Labov
1972a, 1972b.
Those who argue that negative concord is illogical often liken the
rules of grammar to those of formal logic or arithmetic, where one negation
operator or subtraction operation cancels out another; that is, (NOT
(NOT A)) is identical to A, and (-(-5)) = +5. But
grammar is not identical to logic. If it were, then prescriptivists (by
their own logic!) would have to distinguish between sentences containing
even and odd numbers of negative expressions. In fact, however, sentences
with triple negation, like (i.a), count as prescriptively incorrect on a
par with sentences with double negation, like (i.b).
| (i)
| a.
|
| They never told nobody nothing.
|
|
| b.
|
| They never told nobody.
|
10. Because of the social stigma associated
with it, it is essentially impossible to study negative concord in
present-day English. This is because even for those speakers of negative
concord varieties who don't productively control standard English as a
second dialect, the influence of prescriptive grammar is so pervasive that
it renders their judgments about negative concord sentences
uninterpretable. In other words, when such speakers reject a sentence, we
don't know whether they are rejecting it for grammatical or for social
reasons.
Exercises and problems
Exercise 1.1
The sentences in (4) violate several descriptive rules of English,
three of which are given in (5). As mentioned in the text, there is a
fourth descriptive rule that is violated in (4). Formulate it (you should
be able to do this in one sentence).
Exercise 1.2
(1)-(4) illustrate the facts of subject-verb agreement in the
nonstandard variety of English spoken in Belfast, Ireland (data from
Henry 1995, chapter 2). Formulate a brief
description of the data.
| In this exercise (as in linguistics more generally), it is helpful
to distinguish carefully between form and function (the signifier and
signified of Ferdinand de Saussure). In different dialects, one and the
same form (say, a singular verb form) can have different functions.
|
| (1)
| a.
| ok
| The girl is late.
|
| (2)
| a.
| *
| The girl are late.
|
|
| b.
| ok
| She is late.
|
|
| b.
| *
| She are late.
|
|
| c.
| ok
| Is { the girl, she } late?
|
|
| c.
| *
| Are { the girl, she } late?
|
| (3)
| a.
| ok
| The girls are late.
|
| (4)
| a.
| ok
| The girls is late.
|
|
| b.
| ok
| They are late.
|
|
| b.
| *
| They is late.
|
|
| c.
| ok
| Are { the girls, they } late?
|
|
| c.
| *
| Is { the girls, they } late?
|
Exercise 1.3
Which of the newspaper headlines in (1) are lexically ambiguous,
which are structurally ambiguous, and which are a mixture of both types
of ambiguity? Explain.
| (1)
| a.
|
| Beating Witness Provides Names
|
|
| b.
|
| Child teaching expert to speak
|
|
| c.
|
| Drunk gets nine months in violin case
|
|
| d.
|
| Enraged cow injures farmer with ax
|
|
| e.
|
| Prostitutes appeal to Pope
|
|
| f.
|
| Teacher Strikes Idle Kids
|
|
| g.
|
| Teller Stuns Man with Stolen Check
|
Exercise 1.4
In the text, we showed that sentences are recursive categories. In
other words, one instance of the syntactic category 'sentence' can contain
another instance of the same category. Provide evidence that noun phrases
and prepositional phrases are recursive categories as well.
Exercise 1.5
Which, if any, of the sentences in (1)-(4) are ungrammatical? Which,
if any, are semantically or otherwise anomalous? Briefly explain.
| (1)
| a.
|
| They decided to go tomorrow yesterday.
|
|
| b.
|
| They decided to go yesterday tomorrow.
|
| (2)
| a.
|
| They decided yesterday to go tomorrow.
|
|
n | b.
|
| They decided tomorrow to go yesterday.
|
| (3)
| a.
|
| Yesterday, they decided to go tomorrow.
|
|
| b.
|
| Tomorrow, they decided to go yesterday.
|
| (4)
|
|
| They decided to go yesterday yesterday.
|
| (5)
|
|
| How long didn't Tom wait?
|
Exercise 1.6
A. Consider the first stanza of Lewis Carroll's Jabberwocky. The poem
doesn't 'make sense' in any conventional way, yet for the most part
(apart from the novel lexical items) the sentences are grammatical. But
there's at least one that isn't. Find the sentence(s) in question, and
explain your answer.
| (1)
|
|
| 'Twas brillig, and the slithy toves
Did gyre and gimble in the wabe:
All mimsy were the borogroves,
And the mome raths outgrabe.
|
B. The grammars of Early Modern English (1500-1710) and present-day
English differ enough for certain Early Modern English sentences to be
ungrammatical today. Find three such sentences from the King James Bible (1611).
C. As best as you can, briefly describe the source of the ungrammaticality.
Problem 1.1
Are syntactic structure and recursion equally basic properties of human
language? Explain in a few sentences.