September 22, 2003
What is a Reading Error?
William Labov and Bettina Baker
University of Pennsylvania
Abstract
Early efforts to apply knowledge of dialect
differences to reading stressed the importance of the distinction between
differences in pronunciation and mistakes in reading. This report develops a
method of estimating the probability that a possible error in pronunciation is
a true reading error by observing the semantic impact of the given
pronunciation on the childπs reading of the text that follows.
A
diagnostic oral reading test was administered to 579 children who were 1 to 2
years behind grade level in reading in Philadelphia and California elementary
schools.
Subjects were African American, White, and Latino.
For twelve
types of possible dialect-related pronunciation, error rates in the following finite clause were
calculated for correct readings,
incorrect readings, and possible errors.
Possible errors involving final consonant clusters showed following error rates similar to correct
readings for most readers; but for Latinos who learned to read in Spanish
first, they behaved like true errors.
For the copula and irregular past tense items, possible errors behaved
like incorrect readings for all groups.
The likelihood that a possible error was a dialect
pronunciation and not a reading error was compared with the frequency of the
same form in spontaneous speech. For verbal {s}, the r-correlation was 0.855:
the more often the verbal {s} was omitted in speech, the more likely that an
omission in reading was actually a correct reading. The r-correlation for
possessive {s} was ≠0.734. The difference can be linked to the semantic
information conveyed by the two inflections.
The following report is an answer to the question
posed in the title, based on the results of a study of the errors made by 579
struggling readers in inner city schools in Philadelphia and California.[1]
The discussion will provide evidence to support a general answer to the
question of how to define a reading error and a method for determining the
answer in any specific case. It
will also demonstrate differences in the profiles of reading errors of
different groups who come to the task of reading English with different
dialects and language backgrounds.
The focus of the research is to discover the most efficient way of
improving decoding skills for speakers of non-standard dialects of English and
other languages. An essential step
in this program is to distinguish readersπ systematic differences in
pronunciation or grammar from errors in decoding the meaning of the printed
text.
Semantic shadows of reading errors
In the first few years of the acquisition of literacy, the main channel
for appraising the a readerπs progress is oral rather than
silent reading. As the reader
produces successive words and phrases, the teacherπs first responsibility is to
detect reading errors from the oral channel. This channel carries information about the readerπs ability
to decode the printed text -- information coded in the spoken format that is
the output of the readerπs phonetics,
phonology and morphology.
This output is related to the text in a complex way, as a set of a
one-to-many and many-to-one relations.
Many different spellings are pronounced in the same way, and what first
seems to be a correct reading may have been the selection of an
irrelevant homonym: Thus (1) may
bemight
be accepted by the teacher as a correct reading
(1) Text: The sun came up.
Reading:
The sun son came up
.
But
if the sequence in
(1) were followed by additional information, as shown in (2) follows,
the teacher will would realize that the child hads
selected a wrong homonym, son for sun.
(2) Text: The sun came up; it was going to be a hot day.
Reading: The son came up; he was going to be hot.
A reading error can be defined as the selection of the wrong word in a
printed textãthat is, not the word intended by the writer of the text. A question of some importance is how
broadly such differences incorrect selections affect
the over-all interpretation of the text.
As readers improve in fluency, the number of errors in function words
may rise in an innocuous manner, since, for example, the substitution of the
indefinite for the definite article rarely affects the broader interpretation of meaning in a
detectable manner. In
the course of this report, we will develop a generalized method for tracing the
semantic consequences of a possible reading error.
The reading error åsonπ for sun need not have produced an error in the following
text
that followed
in (2), and the readerπs misunderstanding might have been hidden until
some later over-all assessment of comprehension was made. However, we can argue that a true
reading error raises the probability of an error in the following text. The reading error can be said to cast a
semantic shadow over the following text.
We will use the term semantic shadow as
a technical term in the analysis, and, in the course
of the report, develop a generalized method for deciding what is a reading
error by measuring the semantic shadows cast by the potential error.
The determination of what is a reading
error is an essential step in measuring readersπ progress in mastering
alphabetic relations. A comparison
of the reading patterns of different groups cannot be made accurately without a
satisfactory answer to this question.
It has an equal and obvious importance for the construction of methods
of intervention. Efforts to improve
reading should plainly be concentrated on the types of words and constructions
where errors in deciphering the text are maximal.
Potential errors and clear errors
We can begin by examining some actual
cases of potential reading errors, drawn from the diagnostic reading test used
by the Urban Minorities Reading Project [UMRP].
The reading text incorporates the full range of orthographic and
linguistic structures that have been shown to create decoding problems for
beginning readers (Labov et al, 1998) in order to create a profile of the readerπs knowledge
of complex alphabetic relations.
The full text of the reading, ≥Ray and His Cat Come Back≤ [RCCB] is given in Appendix A.
Tutors administering the test are
instructed to write down any deviation from the standard full pronunciation of
the printed text, whether or not they believe it is a reading error.[2] Since we do not know in advance of
analysis whether such a deviation is a reading error, we will refer to any
notation written by the tutor that is not obviously a failure to identify the
intended word as a potential error
rather than an error. An example of a clear error can be seen in (3) below.
(3) Reader: Tyreke J., 8
years old, 3rd grade, African- American,
Philadelphia.
Text: My blood began to boil.
Reading: My boat began to bill.
The
reading blood => boat for blood in (3) is a clear error and so is boil
=> bill for boil. In both cases initial
and final consonants are read correctly; the errors concern the initial cluster
and the vowel pairs oo and oi. The second error bill for=> boil is
in the semantic shadow of the first error.
It seems clear that if blood were
correctly decoded, and the reader knew the idiom involved, there would have
been a higher likelihood of a correct reading of boil. In
what follows, we will produce evidence to justify that inference.
Examples (4) and (5), are cases of potential errors.
(4) Reader:
Filores J., 8 years old, 3rd grade, African- American,
Philadelphia.
Text: I played it cool and took a sip of my coke.
Reading: I play it cool and took a sip of my coke.
The potential error played=>play for played in (4) is a common type of error found in our data and has a number of
possible explanations. It may be a
failure to decipher the past tense signal ≠ed, and indeed such readings of past tense forms as
present tense are extremely frequent.
On the other hand, it may represent a phonological deletion of the final
/d/, though this is not as common for single consonants as in played as compared to consonant clusters in words like served.
In any case, this potential error does not cast a strong semantic
shadow: none of the ten words that
follow the reading play are
misread, and it therefore seems likely that the reader understood the
sentence. The likelihood that the
past tense meaning was understood is increased by the fact that took, the past tense form of take is preserved in (4).
(5) Reader: Raheem G., 11, 4th grade, Latino who learned to read in English first, Philadelphia.
Text: His teeth are as sharp as the edge of my knife.
Reading: His teef are as sharp as the edge of my knee.
The potential error teeth=>teef for teeth in (5)
incorporates a well known dialect
feature of African American Vernacular English [AAVE]: the realization of
syllable final ≠th as final ≠f (Labov et
al, 1968; Rickford, 1999). Members
of the Philadelphia Latino community who have intimate contacts
with the black community share many of these features (Poplack, 1978). It is probable that the reader
understood the second word as åteeth.π
Yet,
there remains a certain amount of doubt, since the reader may have decoded teeth
as /tiyf/ but not made a firm
connection with the meaning åteeth.π
In the semantic shadow of this potential error there is a clear reading
error, knife=>knee for knife, which we suggest would be less likely if åteethπ had been understood. The question remains, was this second
reading error influenced in any way by the initial deviation?
An eight-year old student in the second grade read a sentence with three errors recorded as in (6) [dk = ådonπt knowπ]:
(6) Reader: Maleek N., 8, 2nd grade, African-American, Philadelphia
Text: I told you all about Ray and his bad cat
Reading: I tolπ you all about [dk] and has bad cat.
At first glance, it seems that the
reading tolπ is a phonological
deletion, not a misunderstanding of told as toll. On the other hand, it is still possible
that it represents an incomplete effort at decoding told and that the reader has not arrived at the meaning of
åinform someone in the past.π The
likelihood that this is so is increased by two following errors on words that
are relatively easy to decode, the proper name Ray and the function word his. In (6)
there are two clear errors realized in the semantic shadow cast by the
potential reading error tolπ.
Potential error types
Homonym pairs like son/sun create a problem for the teacher more than for the
reader, since these words are homophones but not homographs. The problem is shared equally by reader
and teacher for homograph/homophones like ring åsurround/sound outπ, cool ånot warm/admirableπ, and tire åauto tire/fatigue.π The main problem that we will confront here is the result of
variations in the pronunciation of a given spelling that creates new
homophones. The simplification of
final consonant clusters (Labov 1966, 1972; Guy 1980) is a process that affects
the speech of all users of English, though it occurs with higher frequency in
non-standard dialects. Speakers of
nonstandard and standard dialects generally show the same patterns of
simplification, but at different frequencies.
Thus for all speakers, the final cluster of find is frequently reduced so that it is pronounced like fine. The range of such reductions are
indicated in (67):
(67) find ‡ /fayn/ = fine
told ‡ /towl/ = toll
mist ‡ /mis/ = miss
rift ‡ /rif/ = riff
The same process affects the clusters formed by the
regular past tense ≠ed suffix,
though at a lower frequency:
(78) dined ‡ /dayn/ = dine
rolled ‡ /rowl/ = roll, role
missed ‡ /mis/ = miss
laughed ‡ /lÊf/ = laugh
The potential loss of meaning of the reductions in (78) is the same
for all itemsãthe loss of the past tense meaning.[3]
Consonant cluster simplification occurs primarily with
final clusters that have the same voicing throughout : / -nd, -lb,
-ld, -st, -ft, -pt, -kt, -vd,/ etc.
It Simplification is much less common with
clusters that have different voicing, where the first consonant is voiced and
the second voiceless, as in /-kt, -nt, -mp, -lk, nk/. In this report, will be concerned with the first type, which are commonly
referred to as homovoiced clusters.
Since the question of dialect effectsimpact on reading
comprehension was first raised, it has generally been generally agreed
that it is important to distinguish reading errors from differences in
pronunciation (Goodman, 1965; Labov, 1965). However, it has not been generally pointed outrecognized that
these dialect differences are potential
errors. When a
reader says /fayn/ for find, we
may be dealing with a colloquial pronunciation of the right word, or a
misreading that has identified the wrong word, fine.
Though consonant cluster simplification occurs in all
spoken dialects, the higher frequencies in non-standard
dialects, particularly AAVE, made this a particularly important issue for
efforts to raise reading levels in inner city, low-economic income areas. TAccordingly, the Urban
Minorities Reading ProjectUMRP made this variableconsonant cluster
simplification a central focus in testing as well as in intervention
methods. The RCCB text used as a reading diagnostic contains the following
words with homovoiced clusters:
(89) told,
old, find, kind, around, worst, thirst, spend, stand, hand, ground, last, risk
Reading errors, clear and potential, were entered by
hand by tutors in the field and later checked against audio recordings of the
test procedures. All items were
then entered into a computer program [RX] (Labov, 2000), which automatically analyzes
automatically
the orthographic structures responsible for errors,
and constructs reading error profiles that reflect the readerπs knowledge of alphabetic
relations
for each type of onset, nucleus and syllable coda, as well as the various
grammatical suffixes involved.
Dialect types
A dialect type is defined as a phonological or grammatical feature that varies with a readerπs language background. Twelve dialect types were identified in the text:
a. words with final homovoiced consonant clusters in the
base form: 13 items
b. words with final homovoiced clusters formed by
addition of the regular past tense suffix ≠ed (sneaked, grabbed, served,
jumpedä): 15 items.
c. other ≠ed
words with regular past tense suffix ≠ed that does not form a consonant cluster (started, stared, played,
tried, poured): 5 items
d. words with the possessive suffix ≠s (Rayπs, catπs, Cindyπs, Mattπs): 4 items
e. words with the contracted copula ås (Hereπs, itπs whatπs, thatπs): 8 items
f. words with the 3rd singular verbal -s suffix (wants, stays, likes): 3 items
g. words with the plural suffix -s: 5 items
h. irregular past tense forms (gave, flew, didnπt,
saidä): 24 items
i. words with initial ch- (chips, chin, chooseä) 5 items
j. words with initial sh- (shame, show,
sharp, shake) 4 items
k. the words brought and bought:
2 items
l. the word sneaked
The rationale for dialect types (a-c) are set out
above. Types (d-f) are forms of
the suffix or clitic ≠s, which are
frequently absent in African American Vernacular English [AAVE]
(Labov et al, 1968); Labov, 1972b; Wolfram, 1969;,
Rickford, 1999; Baugh, 1983;, Weldon,
1994). The grammar of AAVE shows
the absence of subject-verb agreement marked by verbal ≠s, the absence of the attributive possessive ≠s, and the variable occurrence of the contracted form of the
copula ≠s. Type (g),
the plural suffix, is added as a control item for the effect of dialect, since
AAVE preserves plural {s}.[4] Type (h) is a similar control item,
since AAVE uses irregular past forms consistently, with some lexical deviations
from the standard usage.[5]
Dialect
types (i-j) relate to potential errors common with Latino readers. It is regularly reported that speakers
of English with Spanish language background alternate the palatal affricate and
fricatives in choose, chips, shame, etc.
(Wald, 1981). The primary
tendency is to substitute the sh- form
for ch-, but the reverse occurs as
well. Therefore, it is an open
question as to whether the reading Itπs a chameä represents
a reading error or the readerπs pronunciation of the correct word, åshame.π
Studies
of Latino English (Wolfram, 1974; Bayley, 1994; Santa Ana, 1992; Fought, 2003)
also have noted variation in types (a-h), but with distributions that differ
from AAVE. The study of the speech
of the UMRP subjects to be givenpresented below
will instantiate these differences.
Item
(k) bears on the tendency of speakers of AAVE to alternate br- and b- in
the two words listed, so that brought may be pronounced with an initial [b] and bought with [br].
Dialect
type (j) is added as a second control type. In many American dialects, the word sneaked
has a non-standard form snuck, and this form is common among the readers in our
sample. It is evident that the
reading snuck is not a potential
error in the sense defined above, but a correct reading. In order for the reader to produce snuck, he or she must decode sneaked accurately, locate the word that corresponds to the
meaning åsneakedπ, and produce the phonological representation that we spell snuck. The
semantic shadow produced by snuck should
be equal to that cast by the correct reading sneaked; that is, null.
A
dialect item is defined as an
occurrence of a dialect type as a particular word in the text.
Measuring semantic shadows by with the RX program
The examples of errors and potential errors given
above show that no clear resolution of the problem of deciding what is a
reading error can be made from the study of individual cases. We are dealing with probabilities,
which must be established from the readings of large number of subjects. Such data is available: the RCCB text was used with 579 subjects
in the first year of the Urban Minorities Reading ProjectUMRP. The reading deviations and errors noted
by tutors were entered into the RX program, which analyzes each such entry
according to the orthographic and linguistic features that were decoded
correctly, or incorrectly,
nor
or not
at all. The program produces a
profile of reading errors showing rates of success in decoding 27 different
categories of the onset, nucleus and coda, and the major grammatical
suffixes. In order to pursue the
question of defining reading errors, additional routines were written into the
RX program to perform the following functions:
a. Identify dialect items: mark each dialect item in the text as a site of potential errors according to its dialect type.
b. Measure error span: count the number of words from the dialect item to the end of the clause that marks the completion of the major semantic unit in which the word is interpreted.
c. Classify errors: determine for each occurrence of a dialect item whether it was read with no error, a potential error, or a clear error.
d.
Enumerate following errors: count ew the
number of clear or potential errors in the error span that follows each dialect
item (following errors).
e. Calculate means: obtain the average of following errors for correct readings, potential errors, and clear errors by error type and characteristics of the subject population.
f. Establish significance: calculate chi-square for correct readings vs. clear errors, correct readings vs. potential errors, and potential errors vs. clear errors.
Following error frequencies for correct readings vs. clear errors
Figure
1 shows the mean frequencies of following errors by dialect type for dialect
items that were read correctly, and for those items that were not. The
difference between frequencies for clear errors and correct readings are
significant at the p < .0001 level for all dialect types. There is considerable variation in the
frequencies of following errors for these dialect types, especially for those
following incorrect readings. It is maximal for the verbal ≠s
and possessive ≠s suffixes, and minimal for
the regular ≠ed clusters.
This suggests that the non-pronunciation of these grammatical suffixes
by readers may indeed interfere with the comprehension of texts more than
failure to pronounce the final consonants of intact morphemes.[6]
Figure 1.
Frequency of following errors for correct and incorrect readings of
dialect items for all subjects by phonological or grammatical type [N=579] 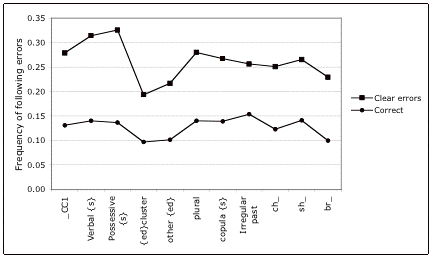
Before proceeding to analyze the data, it is necessary
to confront the fact that the frequency of the errors following the dialect
items can be attributed to two distinct causes. Following errors can be caused by semantic shadows: the consequences of failing to interpret
correctly the dialect item. On the
other hand, it is self evident that poor readers will make more errors in both
cases, and better readers will make fewer errors. The effect of overall decoding skill cannot be separated
from the effect of misreading a particular item.
This ambiguity will not affect the results of this
analysis, since our purpose is to find a decision procedure for classifying the
potential errors. That is, we want
to know for any given dialect type whether the semantic shadow resembles that
of correct readings (that is, a null effect), like that of the clear errors, or
intermediate (significantly different from both).
Figure 2 adds the frequencies of following errors for
the items of interest: possible errors. The dashed line generally follows an
intermediate position, suggesting that sometimes the potential errors do behave
like errors and sometimes they do not.
This is not true for four of the twelve dialect items. Misreadings of
irregular past tense forms show the same semantic shadow as clear errors by
exchanging these fricatives. On
the other hand, readings of words with initial digraphs ch- and sh- by
exchanging these fricatives behave like correct readings, indicating that these
pronunciations are innocuous to the reading process.
Figure 2.
Frequency of following errors for correct readings, potential errors and clear
errors in readings of dialect items for all subjects by phonological or
grammatical type (N=579). Empty
symbols represent those that are not significantly different by chi-square
test.
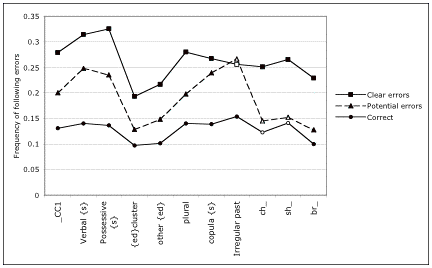
The
intermediate position of other dialect items does not necessarily mean that
they behave in an intermediate way.
We may be dealing with an aggregation of social groups with different
approaches to the reading process, depending on their language and dialect
backgrounds. The fact that the initial digraphs ch-
and sh- behave in such an extreme way for all groups in
Figure 2 may be due to the fact that this behavior is concentrated in the
Latino groupssubjects, and is rare in others. If a particular potential error is
common in some groups, it may be in fact be a correct
reading, since it reflects the native pronunciation of those speakers, while it
may behave in exactly the opposite way for those whose home language does not
include it. Thus the absence of -s
in knows may not reflect the failure to recognize the meaning
of the word on the part of speakers of AAVE, while it that may do so
forbe
the case for Euro-American readers.
Looking
more closely at Figure 2, one can see that the {ed} suffix frequencies of p;otential
errors are closer to those of correct readings than to the error line. The level of following errors for
potential copula errors, on the other hand, is very close to the level for
clear errors, even though it is significantly different from that level. Finally, the br- type behaves almost exactly like ch- and
sh-, indicating that the exchange
of brought and bought is most likely to be a fluctuation of pronunciation
rather than a
misreading.
The
control item sneaked/snuck can now
be examined in the light of this differential
behavior of potential errors. The
oral reading snuck can only be the
result of a correct understanding of the meaning of sneaked and a translation into the alternate form. There were
11 occurrences of snuck for sneaked
in the data base we have been
examining. The total span for
following errors was 110, and in this span, 9 other errors occurred. The frequency of following errors is
.08, not significantly different from the .06 figure for other correct
readings, and significantly different from the level for true errors at .13
(chi-square = 17.8, p < .00001).
The case of sneaked/snuck therefore
confirms the logic of the analysis for the more problematic cases.
Differentiation in reading patterns by ethnicity and language
The
major goal of the UMRP project is to determine whether
differences in the home language of children is are associated
with differences in patterns of reading acquisition, and if so, to determine
how these differences can be used to raise reading levels. The analysis to follow shows how the
examination of reading errors through their semantic shadows contributes to
this goal.
Four
ethnic/language groups formed the subject pool for the UMRP study: African- Americans,
Euro-Americans, Latinos who had learned to read in English first,
and Latinos who had learned to read in Spanish
first. Subjects were drawn from
low-income schools in Philadelphia and in California.[7] There were sizeable regional
differences in reading levels, and this report will therefore present data on
eight groups: four ethnic/language
groups from Philadelphia and four from California.
Figure 3 presents the same data as in Figure 2, for
two groups of California subjects: 79 African Americans, and 83
Latino subjects who had learned to read in Spanish first. The latter is the group with the
strongest Spanish
language influence of the Spanish language; many of
these subjects were born in Mexico and were strongly dominant in Spanish.
Figure 3. Frequency of following errors for correct readings, potential
errors and clear errors in readings of dialect items for California
subjects. AC = African American
[N=79]. SC = Latino subjects who learned to read in Spanish first (N=83) 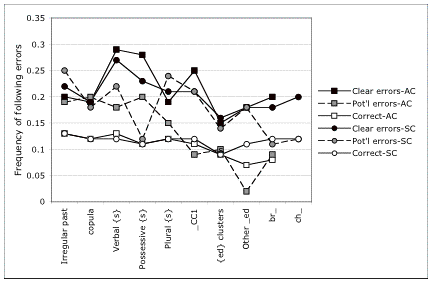
The frequencies of following errors are quite similar for correct
readings for the two groups, and for clear errors as well. For the first seven dialect items, the
values for correct readings are almost identical. A much wider range of variation is seen for the
potential errors. This is partly
the result of sample size: the
pool of tokens of potential errors is much smaller than that for correct and
clear errors. But sample size does
not account for the opposing patterns of the potential errors for the two
groups.
Following the course of the dashed lines, from left to right, one can
see that for both
African Americans (gray squares) and Latinos (gray circles) behave as if past
tense and copula errors behave as if they were true errors. Verbal {s} is intermediate for
both. But possessive {s} is treatedbehaves in a
radically different manner by in the two groups. For Latinos, omission of the possessive in reading leads to
the same low level of following errors as correct readings; for African
Americans the level is quite high.
The situation reverses with the plural, which behaves like clear errors
for Latinos, but like correct readings for African- Americans.
The next three dialect items show an extreme
opposition of the two groups.
Consonant clusters, {ed} clusters, and other {ed} types are at the level
of clear errors for the Latinos, and at the level of correct readings for
African Americans. Figure 3
confirms other indications that African- Americans, like
most native speakers of English, have the underlying forms of these words that
are present in their cognitive representations, even if they do not articulate
the full form in speech. However,
Latinos who have learned to read in Spanish first do not appear to have control
of the same underlying forms. When
they pronounce find as /fayn/, it
is less likely to be a token of the underlying form /faynd/. The same situation applies to the forms
that incorporate the regular suffix {ed}, sometimes to form a consonant cluster
(served), and sometimes to form a
one-consonant coda (played), and
sometimes to form a separate syllable with an epenthetic vowel (started).
Finally, the last two dialect types show clear
identification of potential errors with correct readings. Both groups have data for br-; there
is data for ch- only from Latinos. It
is evident,
on the whole,
that these are features of pronunciation and not reading errors.
The
conclusions to be drawn from the study of following error frequencies do not
bear upon any individual utterance.
For most dialect types, the data is not large enough to give a decisive
answer for any individual. The
information drawn from Figure 3 applies to groups of struggling readers with a
common dialect or language background, information that can serve as a basis for
instructional methods and a pedagogical focus.
For
each language/ethnic group, a dialect item can be classified as equivalent to a
correct response (C), equivalent to a wrong response (W), or intermediate
(I). These classifications are
entered into Table 1. If no
potential errors of this type were made by the group, the cell is left
blank. If the number of potential
errors was less than 5, the classification is entered in parentheses. If the chi-square value for following
errors for the dialect type was significantly different from the opposing classification
at the .01 level, but not significantly different from the given
classification, an asterisk is added.
These are the entries to be weighted most heavily in our interpretation
of the results.
The
areas of strongest group differences are shown in black outline. At left, the potential errors with
verbal {s} (reading stay for stays) are clearly equivalent to a wrong reading for the
groups with a strong Spanish background and for the wWhites from
Philadelphia. It is intermediate
for African Americans and for Latinos from Philadelphia who learned to read in Spanish
first. These readers have no
verbal {s} marker in their underlying systems. For them, the omission of verbal {s} in reading is
equivalent to their normal production of this form, just as snuck reflects the correct reading of snuckedsneaked. For the
others, there is a strong suggestion that failure to pronounce the {s} in oral
reading reflects a difficulty in identifying the verb and its meaning.
The
four following columns reflect the pattern shown in Figure 3. For the group with the strongest
Spanish influence, the Latinos from California who learned to read in Spanish
first, omission of the final consonant, the {ed}, or the plural is equivalent to reading the
word wrong. In the case of root
clusters, but not
{ed}, this is also true for Latinos from Philadelphia who learned to read
in Spanish first, but not for {ed}. For all other groups, no cells appear
where this potential error is significantly identified with a wrong reading. For African Americans, the predominant
pattern is clear identification with a correct reading. Both groups of Latinos who learned to
read in English first show intermediate or non-significant alignment with
correct readings.
The
following column, for potential errors with possessive {s}, again
differentiates Latinos from others.
For whites Whites and African Americans, omission of the
possessive {s} is equivalent to a wrong reading. (Numbers of such items for whites Whites from
California were too small to be significant). This is not the case with Latinos who learned to read
in English readers[8].
No strong group differences emerge from the final five
columns, but rather there is a consensus for all groups. It seems quite clear that omission of
the contracted copula {s} is equivalent to a wrong reading for all groups, and
the same is true for the use of present for irregular past. The reverse is true for the three right
hand columns. There is no
indication that these readings are equivalent to wrong readings, and for most
groups, they are aligned with the following error frequencies for correct
readings.
Table 1. Identification of error status by language/ethnic group and dialect type
- =
percent following errors significantly different from the opposing status.
(E) = learned to read in English first. (S) = learned to read in Spanish
first.
-
|
|
Verbal {s} |
_CC1 |
KKL {ed} |
Oth {ed} |
Plur {s} |
Pos {s} |
Cop-ula |
Irreg past |
br- |
ch- |
sh- |
|
|
AA: Cal |
I |
C* |
C |
C* |
I |
W* |
W* |
W |
C* |
|
|
|
|
AA: Phila |
I |
C* |
C* |
I |
I |
W* |
W* |
I |
C* |
|
|
|
|
White: Cal |
(W) |
|
C |
|
C |
(W) |
W* |
W |
I |
|
|
|
|
White: Phila |
W* |
I |
C* |
I |
I |
W* |
W* |
W* |
C* |
|
|
|
|
Latino(E): Cal |
W* |
I |
I |
W |
I |
W |
W* |
W* |
I |
C* |
|
|
|
Latino(E):Phila |
W* |
C |
C |
C |
I |
I |
W* |
W |
C |
|
|
|
|
Latino(S): Cal |
W* |
W* |
W* |
W* |
W* |
C |
W* |
W* |
C |
C |
C |
|
|
Latino(S): Phila |
I |
W* |
C* |
|
C* |
I |
W |
W |
C |
C* |
(C) |
|
The relationship of reading errors to speech
The
initial motivation for this inquiry was an investigation into the relationship
between the home language or dialect of struggling readers and their patterns
of reading errors. In addition to
recording reading errors through the RX diagnostic, and a the administration of a
range of standardized reading tests, the first year of the UMRP study gathered
recordings of spontaneous speech from all subjects. These recordings used the techniques developed in
sociolinguistic studies of the speech community outside of the
schiol environment to promote the flow of speech and attenuate the effects of
formal observation (Labov, 1984; Roberts ,1993). As in any such investigation, the results showed considerable
variation in volume and quality of speech, but on the whole were reasonably
successful in capturing the vernacular in a form not very distant from that
used in every-day life. They These recordings confirmed
indications that the great majority of the African-American children were
consistent speakers of AAVE, that the Euro-Americans in Philadelphia were
consistent users of the white White Philadelphia vernacular, that Latinos
in Philadelphia were heavily influenced by AAVE patterns, and that Latinos in
California showed maximum influence of Spanish in their English (Santa Ana,
1992; Fought, 2003).
Figure
4 shows an analysis of a random sample of the subjects studied for reading
error patterns, a total of 133 subjects with 15-20 subjects per group.[9]
The dialect patterns for speech are consistent within grouops and
more highly differentiated than the patterns of reading errors. Philadelphia groups are shown with
solid symbols, and California groups with empty
symbols. Philadelphia and
California groups follow parallel trajectories for all five variables,
indicating that the major factor operating here is dialect rather than
region. On the whole, California
subjects show lower levels of dialect features, though the differences are not
as great as with reading levels.
For
the simplification of final homovoiced consonant clusters, (_CC), all groups
show a moderately high proportion of absence of the final consonant, ranging
from .32 to .59. The highest
proportion, for Philadelphia blacks African Americans and Latinos who learned to
read in Spanish first, is twice as high as the
lowest, that for California Wwhites. This pattern echoes that reported in
the sociolinguistic literature: (_CC) is a variable shared by all groups of
English speakers at different levels (Guy, 1980; Labov, 1972).
For
the plural {s}, Figure 4 shows that the plural suffix is intact for whites and
African-Americans, consistent with previous
reports (Labov et al, 1968; Baugh, 1983). Only the Latinos in Philadelphia show
a sizeable absence of final /s/, particularly those who learned to read in
Spanish first.[10]
The
possessive and verbal inflections behave as reported in earlier studies of
AAVE. The Philadelphia African- Americans come
close to categorical absence of these inflections (Labov and Harris, 1986; Myhill
and Harris, 1986). African
Americans in California show a parallel pattern at more moderate levels of
absence. The Latino (S) group
shows a higher relative rate of absence of verbal {s} than the possessive {s}
in both regions. For both white
White
groups, absence of these inflections is rare.
The copula is one of the most intensely studied
variables in the literature on AAVE.
The calculations of in Figure 4 are based on the absence of the
copula against all
Figure 4.
Proportion of absence in spontaneous speech for five linguistic
variables by language/ethnic group [N=133]. (S) = learned to read in Spanish first. (E) = learned to read in English first.
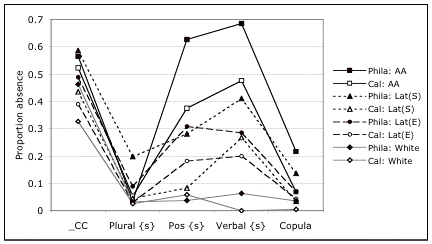
forms of the copula (not just the contracted form, as in Figures 1-3), while the potential errors are simply absence vs. presence of the contracted copula. The Philadelphia African Americans have the highest values, followed as in other cases by the Philadelphia Latinos, who show the strongest African-American influence on speech patterns.
The question
remains as to how these consistent and replicable patterns of speech are
related to reading errors. In
order to establish the possible correlations between these two data sets, the
classifications of Table1 were converted to a numerical scale, reflecting
distance of the potential error types from a correct reading, where C=1, I=2,
W=3. The eight groups were
then ranked in according to degree of absence of the dialect
type (differences of less than .04 being considered a tie). The results are shown in Table 2.
Table 2. Correlations of ranking of language/ethnic groups on absence of five dialect items with approximation to following error frequency of correct readings.
|
|
_CC |
Plural
{s} |
Pos
{s} |
Verbal
{s} |
Copula |
Prop. absence
|
|
|
|
|
|
|
Phila: AA |
1 |
3 |
1 |
1 |
1 |
|
Cal: AA |
2 |
3 |
2 |
2 |
3 |
|
Phila: Lat(S) |
1 |
1 |
4 |
3 |
2 |
|
Cal: Lat(S) |
4 |
3 |
6 |
4 |
4 |
|
Phila: Lat(E) |
4 |
2 |
3 |
4 |
3 |
|
Cal: Lat(E) |
5 |
3 |
5 |
5 |
4 |
|
Phila: White |
3 |
3 |
7 |
6 |
4 |
|
Cal: White |
6 |
3 |
8 |
7 |
5 |
|
|
|
|
|
|
|
Error status
|
|
|
|
|
|
|
Phila: AA |
1 |
2 |
3 |
1 |
3 |
|
Cal: AA |
1 |
2 |
3 |
1 |
3 |
|
Phila: Lat(S) |
3 |
1 |
2 |
1 |
3 |
|
Cal: Lat(S) |
3 |
3 |
1 |
2 |
3 |
|
Phila: Lat(E) |
1 |
2 |
2 |
2 |
3 |
|
Cal: Lat(E) |
2 |
2 |
3 |
2 |
3 |
|
Phila: White |
2 |
2 |
2 |
2 |
3 |
|
Cal: White |
|
1 |
1 |
|
3 |
|
|
|
|
|
|
|
|
r-correlations |
0.101 |
0.487 |
-0.734 |
0.855 |
|
No sizeable correlation is found for final consonant
clusters, which as we have seen shows a continuous range of absence between .30
and .60 for the eight groups.
A moderate correlation is found for the plural. As noted above, the one group
with a sizeable proportion of plural absence in speech, the Latinos (S) from
Philadelphia, has the lowest level of following errors associated with correct
reading.
Very
high correlations of speech and reading error status appear for the possessive
and verbal {s} inflections, but with opposite signs. Verbal {s} shows an r-correlationj of .855.
The higher the absence of verbal {s} in spontaneous speech for a given group,
the more likely it is that this dialect item will behave like a correct
reading. For those who usually do not use verbal {s} in spontaneous speech,
non-pronunciation of the /s/ in stays, wants, likes is not associated with any semantic confusion in the
decoding of the rest of the text.
There are two possible mechanisms that can lead to this result. These readers may read and recognize
the form stays and produce a
translation in their own dialect, comparable to the cases of sneaked/snuck. Or they
may simply ignore the final /s/ and dispense with any information it
provides. It is the second
route that seems more likely, since the verbal {s} provides only redundant
information on person and number that is already signaled by the subject, and
nothing further in the interpretation of the sentence depends on this agreement
marker.
The
reverse situation prevails with the possessive {s} of Rayπs coat, Cindyπs
store, and Mattπs chips, where the r-correlation is -.734. The higher the rate of absence in
spontaneous speech, the less likely that its absence in reading will behave
like a correct reading, and the more likely that it will be associated with
further errors. This opposing
behavior of verbal and possessive inflections can logically be associated with
the difference in semantic content between the verbal and possessive suffixes. Unlike verbal {s}, the possessive {s}
conveys substantive meaning about the relation of two nouns, so that the
≥duckπs nurse≤ is a different entity from the ≥duck nurse.≤ If the ås is present, it signals that the object it is attached dto
is the owner of the entity described by the following noun phrase.[11] If it is absent, a wide variety of
semantic releations sbetween
the two nouns is possible. When the ås signal is not interpreted in a way that will relate the next noun to
the one it is attached to, decoding the following item will be more
difficult. A special
property of the possessive case is that it is the immediately following word
that is most like to show a following error, as in (910) and (110).
(910) Reader:
Shai P., 7 years old, 2nd grade, African American, Philadelphia.
Text: The cat spit out the chips and jumped in Rayπs coat.
Reading: The cat spit out the chips and jumped in Ray cat.
(110) Reader: Michael H., 7 years old, 2nd
grade, African American,
Philadelphia.
Text: The cat spit out the chips and jumped in Rayπs coat.
Reading: The cat spit out the chips and jumped in Ray chuck.
Finally,
Table 2 shows no correlation between speech patterns and the error status of
the copula, since its absence is uniformly associated with high following error
rates, similar to a wrong reading for all groups.
Reading errors with the possessive {s}
The
possessive {s} morpheme occurs four times in the diagnostic text RCCB. In each case, only one word follows:
in
Aunt Cindyπs store
grabbed
Mattπs chips
jumped
in Rayπs coat
didnπt reach up to Rayπs chin
The
first case will not be considered here, as the data are affected by the special
fact that most readers had not internalized the ≥soft-C≤ rule, so that their
attempts to decode the unfamiliar name ≥Cindy≤ usually started with a /k/. The number of potential errors where
the absence of possessive {s} was the only deviation was therefore greatly
reduced.[12]
The
number of potential errors was tabulated for the other three possessive
constructions. These potential
errors were further divided for the following word by the number of correct
readings and the number of incorrect readings inof the
following textword.[13]
The
semantic shadow cast by the omission (or wrong interpretation) of possessive
{s} is easier to characterize than in most other cases: it is the loss of information on the
relationship of possession between Matt or Ray and the referent of
the following word. Incorrect
reading of the following word included a number of items that could reasonably
have been possessed by Matt and Ray: cat, cap, car, face, t-shirt. These are consistent with the possibility that the
reader did decode the possessive meaning from the printed ås, although it was not pronounced. For these cases, the more remote the
error is phonologically from in the printed text, the more likely that it
was motivated by a guess that was semantically informed by the concept of
possession. Thus Ray face for Rayπs chin is a semantically-motivated guess that suggests that the idea of
possession was present. The same
can be said for the reading Matt t-shirt for Mattπs chips. On the other hand, Ray chuck for Rayπs coat or Matt keeps for Mattπs
chips indicates that the concept of
possession was not preserved.
Table 3 shows the numbers of potential errors for those possessive
constructions for four ethnic/language groups, combining regions.
Table
3. Potential errors with three
possessive constructions in RCCB text for four ethnic/language groups. Foll. correct = numbers of correct readings on following
word. Foll. wrong = number of errors on following word. Non-Pos = number of errors that were not possessable objects. Prop Pot Err = proportion of potential errors for all reading.
1 2 3 4 5 6 7
N Potential
Foll. Foll. Non- Prop {s}
abs
errors correct wrong pos Pot
Err in
Speech
African-American 191 79 60 19 10 .138 .508
Latino (English) 130 31 22 9 4 .079 .270
Latino (Spanish) 140 31 23 8 6 .074 .196
White 106 9 6 3 3 .028 .051
The
proportion of potential errors in Table 3 is highly correlated with the
proportion of absence of possessive {s} in speech. The Pearson r-correlation is .993. Figure 5 plots these
figures for the four language/ ethnic
groups. The differences between
groups are significant at the .01 level for all relations except potential
errors for the two Latino groups, where the difference is significant at the
.05 level. It is clear from this
figure that absence of ≠s in reading is
a direct reflection of the readerπs phonology in speech, though at a lower
level.
Despite this close correlation of speech and reading,
Table 3 shows that the semantic shadow cast by failure to read the possessive
suffix is the same for all groups.
There are no significant differences between groups in the proportion of
following correct to. following
wrong readings (column 2/column 3), or in the proportion of non-possessable
errors for to all errors (column 4/column 1).
Figure 5. Absence of possessive {s} in spontaneous speech and in potential reading errors by language/ethnic group
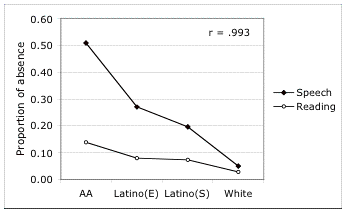
Table 1 indicated that failure to
realize the possessive {s} in reading is likely to be associated with a failure
to comprehend the following material.
Table 3 shows that this is true for all ethnic and language groups. African Americans are particularly
likely to omit this inflection in reading (column 5), and it might seem that
this is a direct reflection of their patterns of speech. It may be that fewer of their omissions
are connected with a failure of comprehension than for other groups, and that
with larger numbers, significant differences will emerge. However, the evidence of Table 3 points
towards a common problem for all readers.
The omission of the possessive inflection in reading carries with it a
greater likelihood of misunderstanding the text to follow for all readers. It follows that direct instruction on
the reading of the possessive {s} will be of value for every struggling reader.
Discussion
The
struggling readers who were tested in the UMRP series read slowly, with much
hesitation, and with little grouping of words into phrases. It often seems that they are decoding
words individually, with no effort to assemble them into meaningful
propositions. Yet this cannot be
the case. The semantic shadows
that are the focus of this report do not represent difficulties in decoding individual
words, but rather the interference of a previous decoding problem with the use
of context to help decode following words. To that extent, we are measuring the consequences of
decoding errors for the syntactic and semantic integration of phrases and
sentences. The originating
errorãpotential or clearãremoves contextual information that would have been
helpful in decoding the following texts.
It may also in addition supply misleading information that leads the
reader to further errors. Thus a
reading errorãclear or potentialãis a natural experiment that yields
information on the role of context in decoding. In any case, the semantic shadows that provide the basic
data for this study would not exist if children were decoding the text
word-by-word.
The findings in this report firmly establish the connection between
speech and reading errors, and anticipate further investigations of this
relationship. At the same time,
they point toward pedagogical issues of some consequence.
From the outset, the UMRP studies study of reading
errors were was confronted with many unanswered questions
about what should be corrected and what should be taught in order to advance
levels of achievement of struggling readers. The many differences between AAVE grammar and the Standard
English of reading texts were reflected in the absence of final inflections in
oral reading. But at first glance,
these seem of minor importance compared to knowledge of the silent-e rule,
which dictates vowel length in a sizeable part of the vocabulary. Even if we allow that the omission of the /s/ in runs
or the omission of the /d/ in served is
a failure to decode part of the text, the question remains as to how often the
information provided by these particles would be essential to the success of a
later effort to answer questions about the text.
The past tense is perhaps the most challenging of
these issues. Our records contain
a large number of misreadings of past tense signals that cannot be related to
speech patterns. Speakers of AAVE use
the past tense forms gave, spoke, began, didnπt in the same way that speakers of other dialects do,[14] Yet, they frequently read these past tense forms
as present tense. The question
remains, how important is past tense information for the success in answering
comprehension questions in the standardized tests that currently measure
reading achievement? Given the
frequent use of the historical present in educated speech, it is clear that
listeners can deal with rapid oscillations of tense signals without becoming
confused. The same questions
can be raised about a wide variety of grammatical forms.
The findings of this report provide one answer to this
question. It is may not
be the absence of the information provided by the grammatical signal that interferes
with successful decoding and the ultimate comprehension of the text. The semantic shadow cast by the error
lowers the probability of correct decoding of the balance of the relevant text. This may be the result of many
different kinds of interference with the assembly of the semantic and
syntactic structures to follow.
From our current results, it appears that reading past tense forms as
present forms is equivalent to the wrong identification of whole lexical items,
as far as the consequences for further decoding are concerned. The same applies to the copula; it is
not so much the omission of the ås signal
that interferes with reading success, but the consequent disturbance of the web
of semantic and syntactic relations that follow.
On the other hand, these results confirm the early
suggestion that too much attention paid to the articulation of final consonant
clusters would be self-defeating and distracting in the teaching of reading,
since whether or not they appear intact in oral reading is a matter of
pronunciation that has little to do with the task of reading: comprehension of
the written text. What is
surprising in these findings is that the same consideration extends to the
clusters formed by the {ed} suffix, and the {ed} suffixes that do not form
clusters. This indicates that at
least for the majority, the {ed} suffix is well established as an underlying
form, and whether or not it is pronounced is not a material issue for the
reading process. Just the opposite
must be said for the possessive {s} suffix.
So far, these remarks apply only to the majority of
our subjects. In this sense, the
struggling readers of African American and
Euro-American background readers form the
main stream of the reading process as we have been studying it. There is a minorityãin this case a very
large minorityãof readers who do not have the same underlying forms in their
mental lexicon. This is most
clearly demonstrated by the dramatic differences between Latinos who have
learned to read in Spanish first and others. When these readers pronounce opened as open,
it is not because they have retrieved the original full form, understood it,
and reproduced it in their colloquial version. Rather, the {ed} remains a partly known object, whose
significance is not clear, and failure to decode it leads to further
consequences down the line.
The implications of these findings as to what should
be taught to whom and when are fairly clear. To some extent they echo the intervention methods set
up by the UMRP on the basis of our earlier studies of AAVE and Latino English.[15] But in other respects, they add
new knowledge, and project new forms of intervention that may be more
effective.[16] Better understanding of the
possessive, the copula, and irregular past tense are important for all
struggling readers, and direct instruction on the decoding of these signals
should lead to a significant advance in reading levels.
The report is an effort to develop is the
systematic study of how phonological decoding interacts with context and the
construction of meaningful discourse. The concept of a semantic shadow provides a
methodological tool that should be helpful in further specifying what is a
grammatical error. What lies
within that shadow must be the focus of further inquiry.
References
Alba, O. (1990). Variacion Fonetica y Diversidad
Social en el Espanol Dominicano
de Santiago. Santiago: Pontificia Universidad
Catolica Madre Y Maestra.
Baugh, J. (1983). Black Street Speech: Its History, Structure and Survival. Austin: University of Texas Press.
Bayley, R. (1994). Consonant cluster reduction in Tejano
English. Language Variation and
Change, 6, :303-326.
Cameron, R. (1992). Ambiguous agreement, functional compensation and
non-specific tu in the Spanish of San Juan, Puerto Rico, and Madrid, Spain. Language Variation and Change, 5,
305-334.
Fought, C. (2003). Chicano English in Context. New York: Palgrave Macmillan.
Goodman, K. S. (1965). Dialect barriers to reading
comprehension. Elementary
English, 42, 853-860.
Guy, G. (1980). Variation in the group and the
individual: the case of final stop deletion. In W. Labov,
ed., Locating Language in Time and Space. New York: Academic Press, 1-36.
Labov, W. and Harris, W. A.
(1986). De facto segregation of black and white vernaculars. In D. Sankoff, ed.,Diversity and Diachrony. Philadelphia: John Benjamins, 1-24.
Labov, W., Baker, B.,
Bullock, S., Ross, L. and Brown, M. (1998). A graphemic-phonemic analysis of the reading errors of inner
city children. http://www.ling.upenn.edu/~labov/Papers/GAREC/GAREC.html.
Labov, W., Cohen, P.,
Robins, C. and Lewis, J. (1968). A
study of the non-standard English of Negro and Puerto Rican Speakers in New
York City. Cooperative Research
Report 3288. Vols I and II. Philadelphia: U.S. Regional Survey, Linguistics
Laboratory, University of Pennsylvania
Labov, W. (1966). Some sources of reading problems. In A. Frazier, ed., New Directions in Elementary English. Champaign, IL: National Council of
Teachers of English. Pp. 140-167. Also as Chapter 1 of Language in the Inner City.
Labov, W. (1972a). Where do
grammars stop? In R. Shuy, ed., Georgetown
Monograph Series on Languages and Linguistics, 25, Pp. 43-88.
Labov, W. (1972b). Language in the Inner City.
Philadelphia: U. of Pennsylvania
Press.
Myhill, J. and Harris, W. A.
(1986). The use of the verbal -s
inflection in BEV. In D. Sankoff, ed., Diversity and Diachrony. Amsterdam: John Benjamins Publishing Co., 25-31.
Poplack, S. (1978). On dialect acquisition and
communicative competence: The case of Puerto Rican Bilinguals. Language in
Society, 7, 89-104.
Poplack, S. (1980). The notion of the plural in Puerto
Rican Spanish: competing constraints on /s/ deletion. In W. Labov,
ed., Locating Language in Time and Space. New York: Academic Press, 55-68.
Rickford, J. (1999). African American Vernacular English:
Features and Use, Evolution, and Educational Implications. Oxford:
Blackwell, Inc.
Roberts, J. (1993). The
Acquisition of Variable Rules: t/d Deletion and ≠ing Production in Preschool
Children. University of Pennsylvania dissertation.
Santa Ana, O. (1992). Chicano English evidence for the
exponential hypothesis: a variable rule pervades lexical phonology. Language Variation and Change, 4,
275-288.
Wald, B. (1981). Limitations on the variable rule
applied to bilingual phonology: The unmerging of the voiceless palatal phonemes
in the English of Mexican Americans in the Los Angeles area. In D. Sankoff and H.
Cedergren, eds.,Variation Omnibus. Edmonton,
Alberta: Linguistic Research.
Weldon, T. (1994). Variability in negation in African
American Vernacular English. Language
Variation and Change, 6, 359-397.
Wolfram, W. (1969). A
Sociolinguistic Description of Detroit Negro Speech. Arlington, Va.: Center for Applied Linguistics.
Wolfram, W. (1974). Sociolinguistic Aspects of
Assimilation: Puerto Rican English in New York City. Arlington, Va.: Center for Applied Linguistics.