The Prosody of Speech Timing
Introduction
There is a vast and interesting literature, over many decades, on durational variation across languages. Much of this deals with the nature and effects of linguistic structures, including "phrases" in the general sense.
Rather than attempting to survey this literature, I'll try to summarize and illustrate some of the key points, while providing a few links to relevant additional readings.
Within a given speech stream, there are five types of factors that systematically influence speech timing, at a variety of scales of time and structure:
- The phonological system of the language (and dialect and style) involved, and its phonetic interpretation.
- The intrinsic duration of the speech gestures and gesture sequences involved
(e.g. low vowels are generally longer than high vowels). - The structure of the message
(including syntax, but also things like stress, focus, anaphora, topic/comment articulation, etc.). - "Audience Design"
(e.g. slower and more careful for difficult-to-understand parts; faster for redundant, obvious, boring stuff). - The process of composing, planning, and executing the utterance sequence.
I. Ritardando al Fine: Word Duration in Pause Groups
We're starting with a mixture of points (5) and (3) involved, by looking at word durations in "pause groups," i.e. speech segments without internal silences greater than 150 msec.
In read speech, these generally correspond closely to message-structure phrases; but in conversational speech, not so much. For example, here's an exchange from the Switchboard Corpus of conversational telephone speech:
| A: | um yeah i'd like to talk about how you dress for work and and um what do you normally what type of outfit do you normally have to wear |
| B: | well i work in uh corporate control so we have to dress kind of nice so i usually wear skirts and sweaters in the winter time slacks i guess and in the summer just dresses |
By that definition of "phrase", the corpus contains 519,598 phrases in 2,438 conversations.
If we look at word duration by (thereby defined) phrasal position, we're abstracting away from many relevant things -- word length and phonological content, within-pause-group phrasal structure, phrasal stress, focus/contrast/anaphora, etc. Nevertheless the results show a remarkably clear pattern, which arguably represents the general prosodic shape of pause groups., independent of those other important factors.
1. Data from Switchboard Corpus (American English conversational telephone speech):
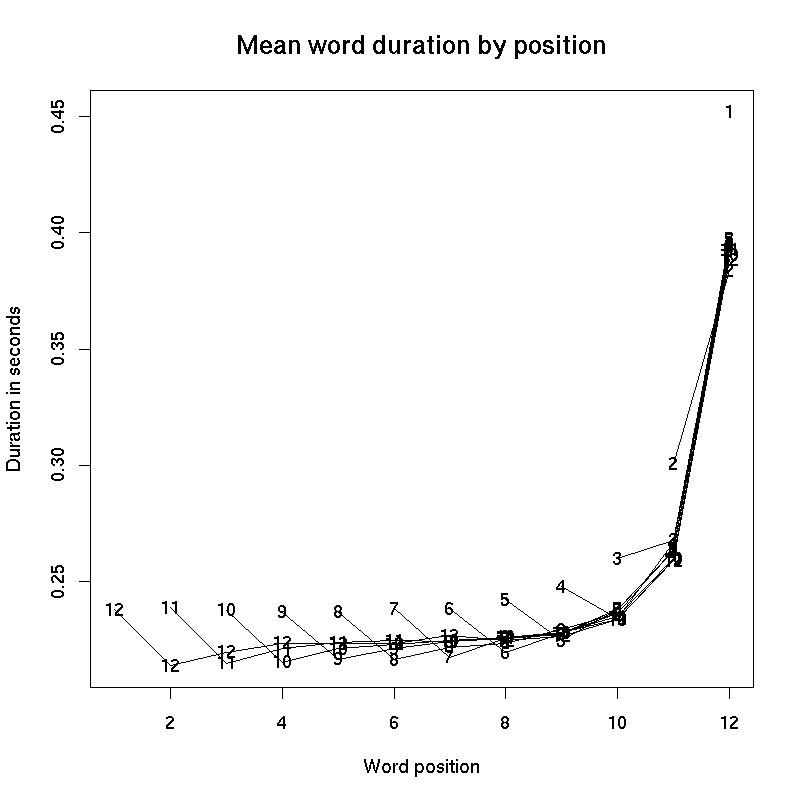
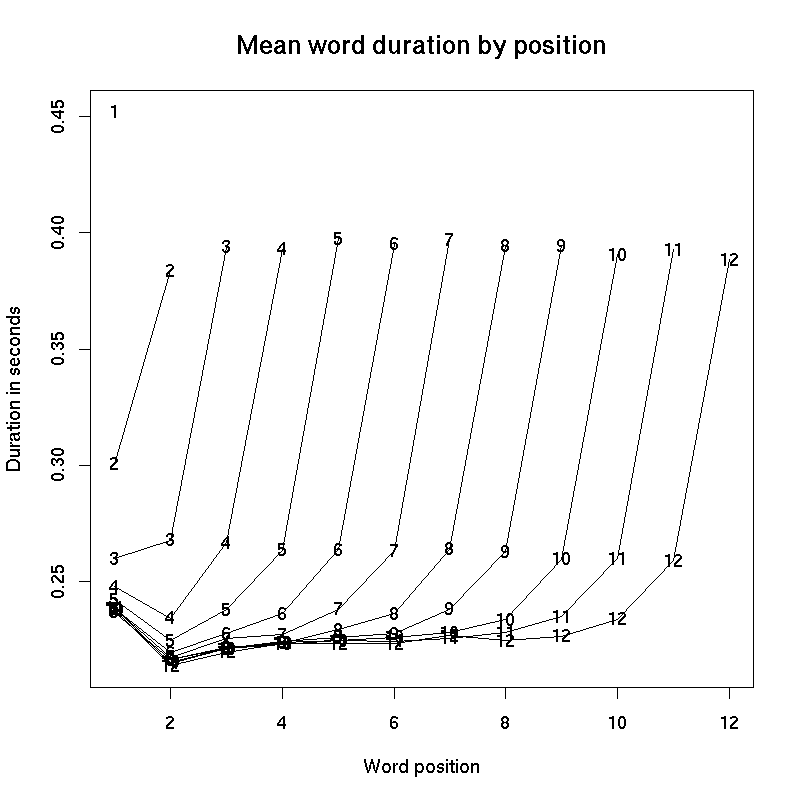
The obvious conclusion is that "pre-pausal lengthening" is an important and indeed dominating effect.
And we see generally similar patterns in other languages, and in read speech.
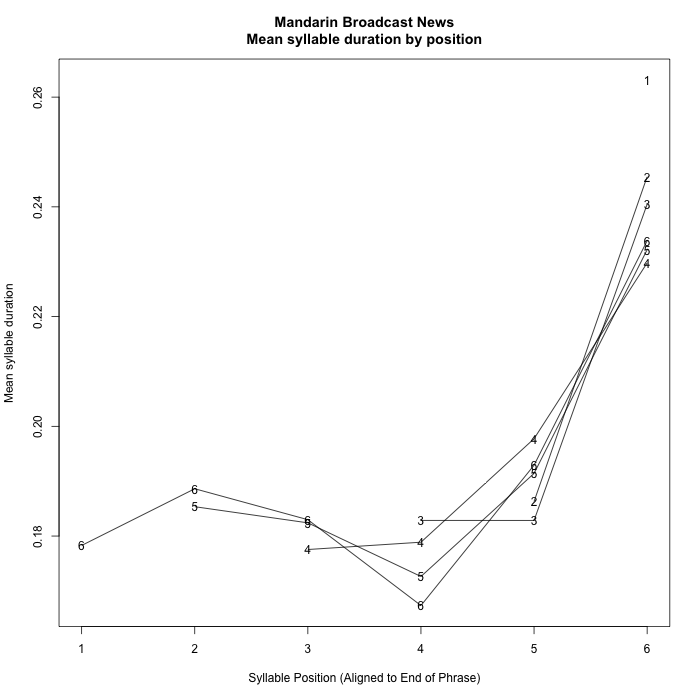
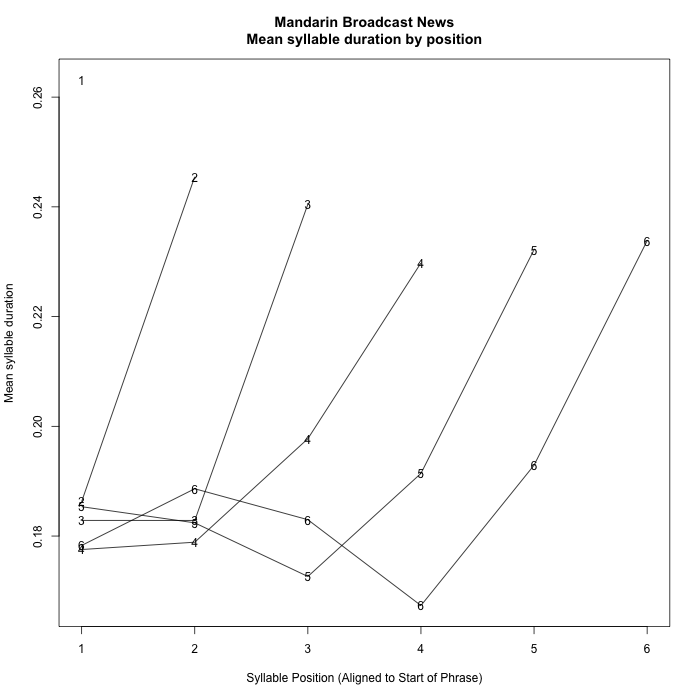
2. Data from Mandarin Broadcast News
This comes from a published corpus of 30 hours of broadcast news material from three sources, which yielded 10,699 breath-group-like phrases from 20 speakers, comprising 96,697 syllables. Given Mandarin monosyllabism, the alignment was in terms of syllables (generally equal to morphemes) rather than words.
Again there is a remarkably consistent pattern, with the difference that there is a strong ante-penultimate durational dip, an apparently initial shortening effect, and an overall increase and decrease in the body of phrase.
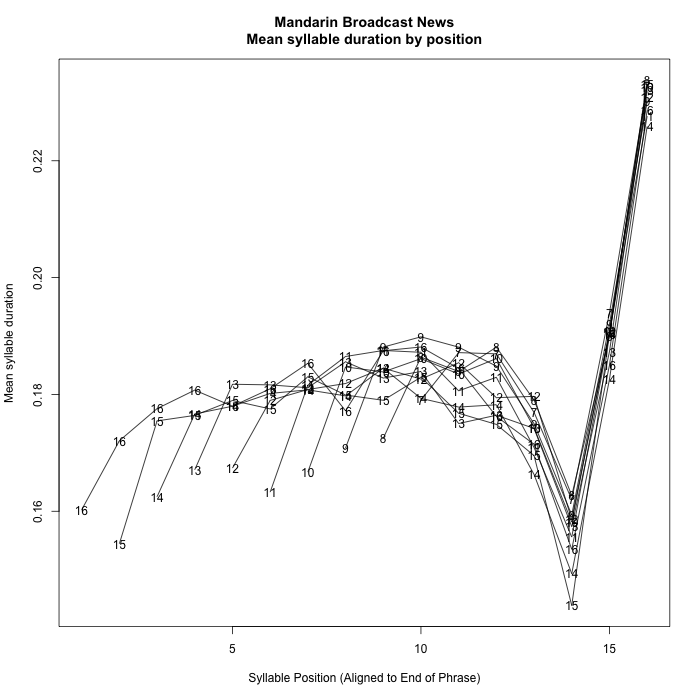
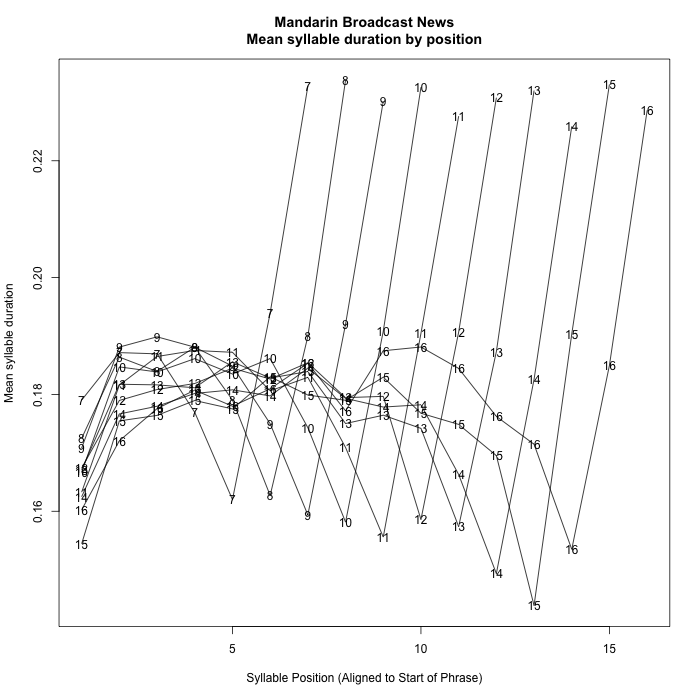
I've left phrases of length 1 to 6 syllables out of those plots, because the overlap with initial and final effects confuses the picture. For completeness, here they are:
3. Data from a Spanish Audiobook
For another project, we aligned the Audible audiobook version of Isabel Allende's La Casa de los Espiritus. This involves 17 hours of speech from a single speaker. As in the Mandarin data, this is read speech; and as in English, the units plotted are word durations.
As in the Mandarin daa, we see a penultimate dip, though a weaker one.
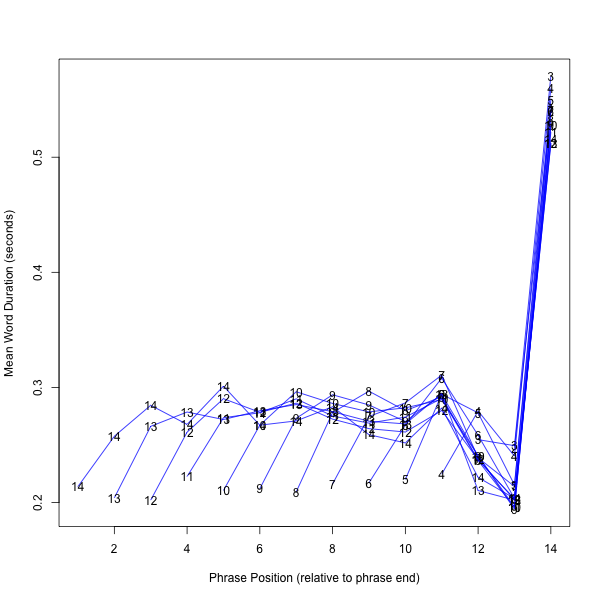
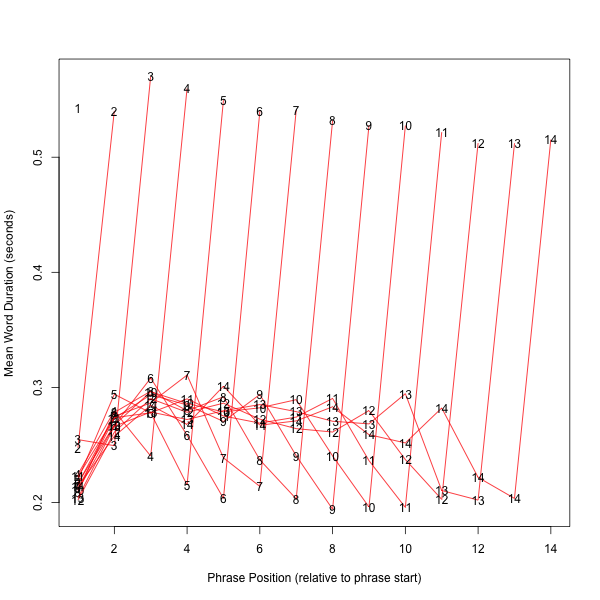
4. Data from English Audiobook Chapters
Finally, here are similar plots from the LibriSpeech Corpus, a collection of 5,832 English audiobook chapters. This is obviously read speech, in which pause structure generally corresponds closely to message structure.
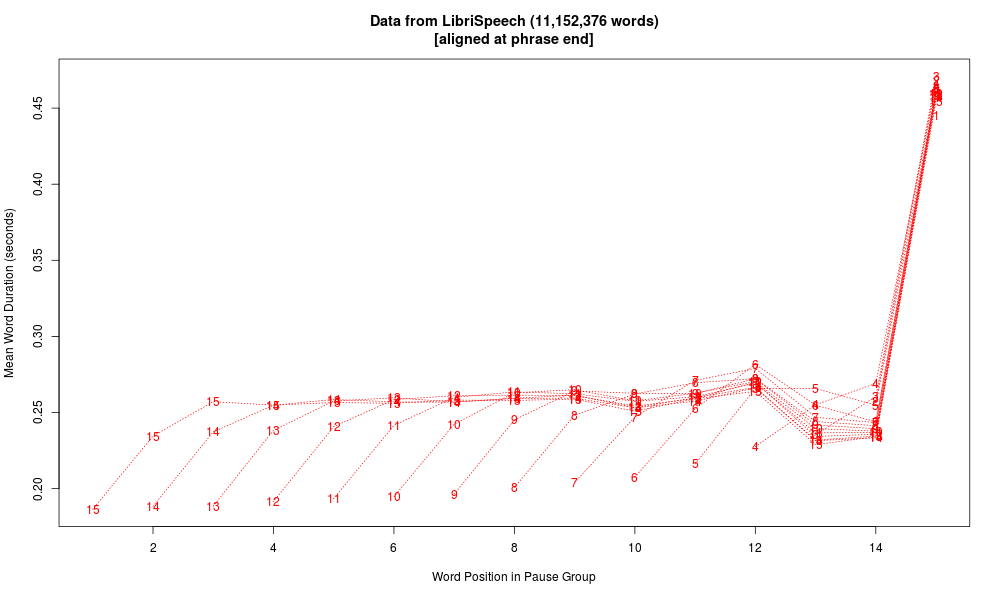
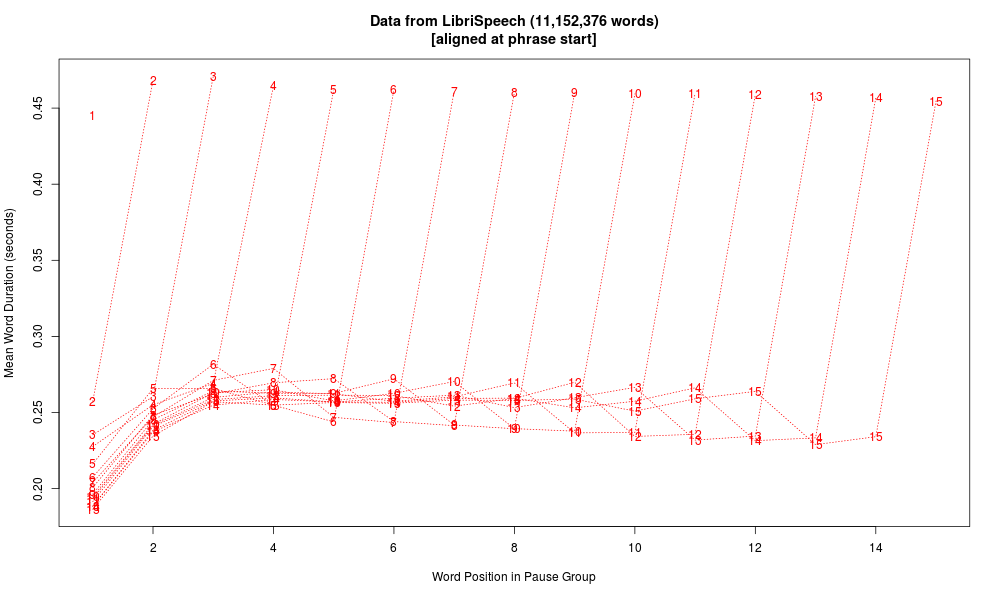
Here's the same data plotted syllable-wise, calculating "syllables" as vowel-onset-to-vowel-onset for non-phrase-final syllables, and vowel-onset-to-silence-onset for phrase-final syllables. Here we see initial shortening and an antepenultimate dip, as in Mandarin, though the pattern in the body of the phrase seems somewhat different:
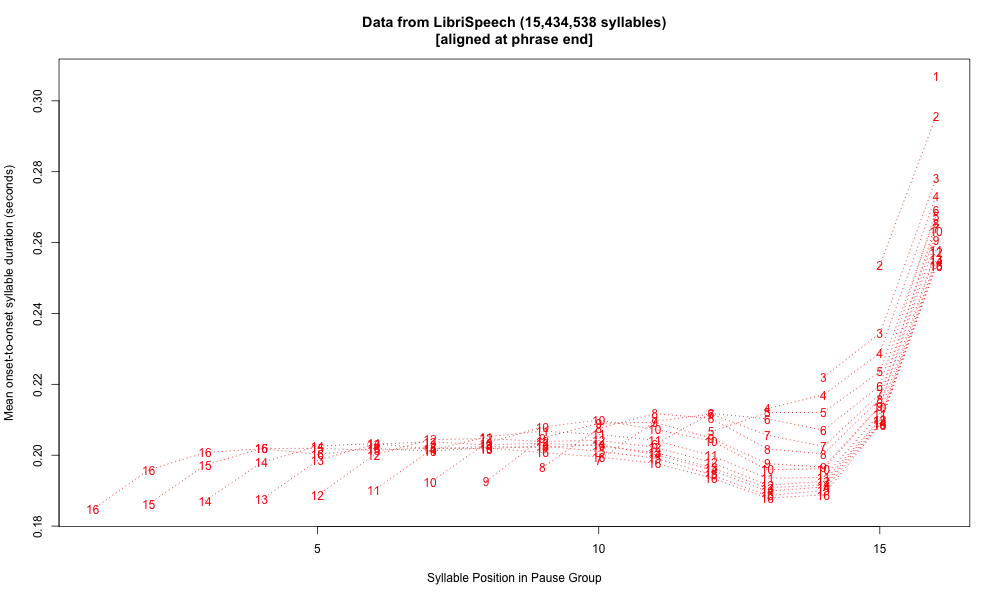
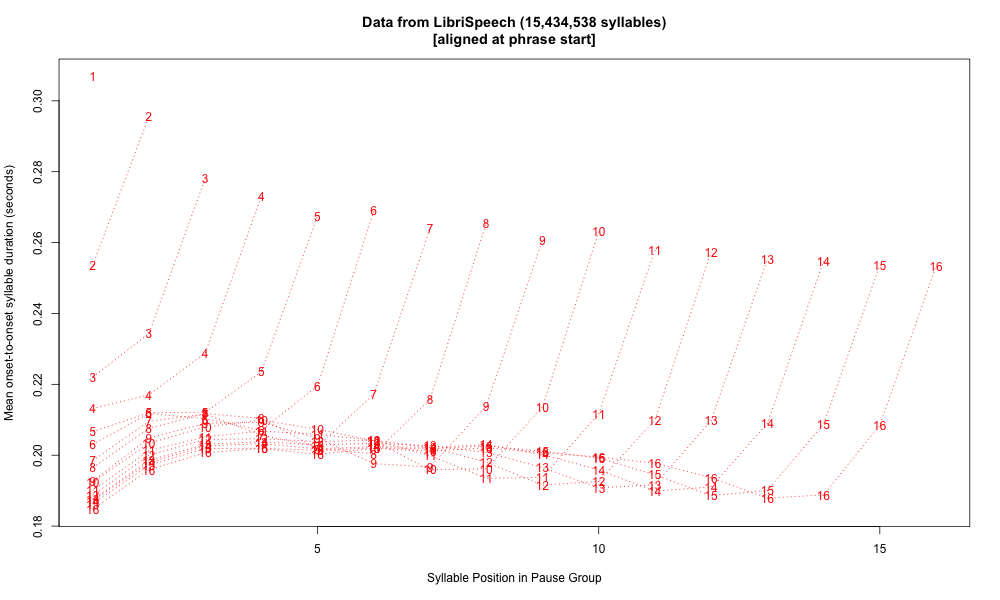
Overall these pause-group plots raise more questions than they answer, but they do emphasize one important lesson, namely that pre-pausal lengthening is a large, robust, and even dominant fact. More broadly, the phenomenon should really be called "pre-boundary" lengthening, since it applies even when the boundary is not marked by a silent pause. But it's also worth noting that the same phenomenon does apply in spontaneous speech where the string is divided due to the process of composition and execution, rather than due to the structure of the message as such.
(As a curious cultural aside, it's worth noting that early Anglophone phonetic luminaries like Henry Sweet, Daniel Jones, and J.R. Firth never observed the phenomenon of pre-boundary lengthening, or at least never commented on it, as far as I've been able to determine. This was apparently due to their obsession with hallucinations of "stress timing", or at least with stress or accent-based syllabic organization. In contrast, l'Abbé Rousselot wrote about final lengthening in the late 19th century, since he had the advantage of speaking a language in which stress feet don't exist. )
[See here, here, here, here, here for further details.]
II. Duration in Structured Digit Strings
We want to look more closely, across languages, at the effects of word and phrase structure, focus, and so on. But there are challenges:
- The effects of intrinsic phonetic differences are as large as the prosodic effects, and interact with them in complex ways.
- Word frequency, recency, and "communicative dynamism" also matter; and it's hard to make these genuinely "neutral" in decontextualized phrases.
- Creating lexically and phrasally comparable material across languages and styles is even harder.
- Because of gestural overlap and the lack of well-defined phonetic segment boundaries, it's unclear what to measure and how to compare measurements.
Amplifying the last point, the "segments" that phoneticians often measure are basically illusions created by non-linearities in the mapping between articulation and sound. From a phonetic point of view, it's wrong to think of "phonemes" as beads on a string -- adjacent phonetic gestures always overlap to a considerable extent, so that a given point in the acoustic stream generally involves effects of three or even four adjacent phonological segments. See here for a discussion of why we should look at speech as the language-specific phonetic interpretation of (relatively abstract) structured phonological representations.
A simple (if limited) way around these problems is a little exercise that I began using in intro phonetics classes 30 years ago. We create 100 random strings of N digits each, in which every digit occurs equally often in every position, and every pair of digits occurs equally often spanning every pair of positions: makenumberlist.py. (A sample output, or another one formatted for reading...)
In a list of this kind, the occurrences of "words" and "word pairs" are controlled, and therefore we can hope to control any local effects of the different intrinsic durations of different phonetic segments, as well as the effects of segmentation choices.
In addition, we can look at the effects of certain types of focus, e.g. correction of wrongly remembered digits. And the same materials can be used across languages (modulo local practices in reading such number strings).
These digit strings can be read as if they were standard U.S. telephone numbers, structured like NNN-NNN-NNNN, usually understood as (3 + (3 + 4)):

The same 10 digits could of course be structured differently, e.g. as ((3 + 2) + (3 + 2)). Example readings of the two versions:
| 752-955-0354 | |
| 752-95-503-54 |
It won't surprise you to learn that this changes the pattern of average digit durations:

To highlight the effects of word structure and intrinsic phonetic duration we can take a look at averages by digit in seven-digit strings of this type, grouped as (3+4):
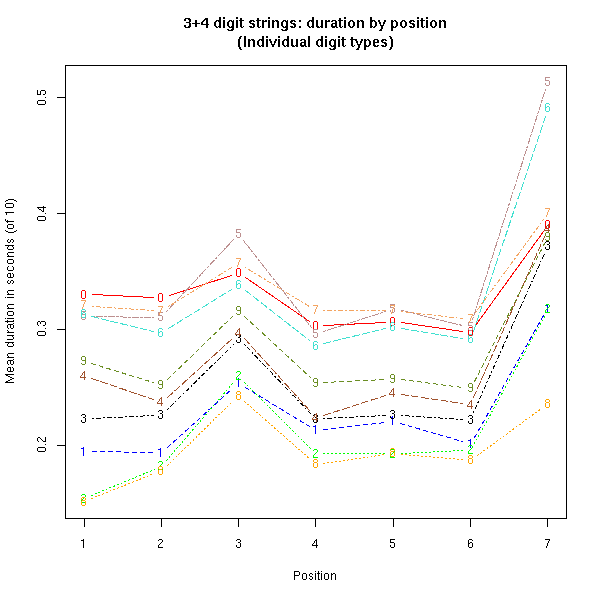
Note that the longest versions of "eight" are shorter than the shortest versions of "five", due to intrinsic-duration effects.
Returning to the 10-digit U.S.-phone-number-type strings, here's a plot of the 10 different English digits of average duration in position 2 versus average duration in position 3. The different digits all fall along the same line -- but there's also a non-zero intercept, as shown by the dashed red line, which is the result of linear regression without an intercept term:

The intercept term may be related to Dennis Klatt's notion of prosodic "incompressibility" -- but that would take us too far afield for now.
If we compare durations in position 9 against dureations in position 10 (the final position), a new phenomenon appears. 0 ("zero") and 7 are now distinctly off the line -- and these are the only two-syllable digits, with an unstressed final syllable:

And for a bit more fun, we can compare positions 2 against 3, 5 against 6, and 9 against 10, in the (3+(3+4) structure:

These simiple experiments provide evidence for durational influences of three levels of structure. Are there more? This is by no means settled -- there are those who believe in N specific levels of a "prosodic hierarchy", for N=3 or so. But an alternative view, which I share, is that an unbounded number of recursive message-structure levels can influence the dynamics of speech production. Thus Ladd & Campbell 1990, "Theories of Prosodic Structure: Evidence from Syllable Duration":
In this study we have compared two approaches to modelling position-in-phrase effects on syllable duration. The model previously employed defined such effects in terms of two levels of phrase, majtg and min-tg. This was replaced by a model distinguishing four levels of phrase ( subordinate and superordinate groupings of phrases at both maj-tg and min-tg levels), to test the independently developed theoretical notion that there is actually no principled limit to the depth of prosodic structure. The second model gave a significantly better account of the distribution of syllable durations. This suggests that the notion of indefinite prosodic depth has merit and may be of practical empirical relevance.
III. The Effect of Contrastive Focus in Different Languages
What we've seen so far doesn't clearly distinguish the direct effects of phrasing (e.g. pre-boundary lengthening) from the effects of relative prominence, given that right-dominant phrasal prominance is normal. One way to change this is by using contrastive or corrective focus to change the prominence relations.
That's what Yong-cheol Lee did in his 2014 Penn PhD thesis, "Prosodic Focus Within and Across Languages". His goal was to find a way to compare prosodic focus across languages.
Speakers produced 100 10-digit strings in isolation for broad focus and in a Q&A dialogue as below for corrective focus, where someone asks whether the phone-number is correct and the speaker answers the question with a string by correcting the wrong digit. [Dialogue translated per language...]
Q: Is Mary‘s number 887-412-4699?
A: No, the number is 787-412-4699.
The results were striking -- in English, the location of a focused digit is clearly marked by modulations of pitch, duration, and amplitude. In Korean, not so much:

And the perceptual results echoed the same difference:

It's apparently not even enough to take the view that the focus domain is phrasal rather than lexical:

Chinese is more or less like English:

Although the accuracy of focus perception was affected by tonal category:

French is also basically like English -- which was a surprise given its apparent lack of dynamic accent, and the (perhaps prescriptive) view that prosodic focus is not possible. Japanese, on the other hand, seems to be like Korean.


See also: Lee, Yong-cheol, Bei Wang, Sisi Chen, Martine Adda-Decker, Angélique Amelot, Satoshi Nambu, and Mark Liberman, "A crosslinguistic study of prosodic focus", IEEE ICASSP 2015.
[Links to more references will come later...]