Exercise 2: Simple English Forced Alignment
Goals:
- Verify your ability to use basic unix command-line utilities
- Learn to do basic "forced alignment" in English, and to inspect the results in Praat
You should get this done by February 11. Turn in your results using the Canvas site.
1. In a terminal window, log in to harris. Be sure that /usr/local/bin is on your PATH. You can check this with
echo $PATH
It should be there by default -- if not, contact someone in authority.
2. As inputs, you will need an audio file and a transcript file.
The audio should be a single-track (mono) file with a sampling rate of 16000 Hz or higher. (We'll see later what to do with stereo files, and rates of 11025 or 8000 Hz.) You can diagnose the file type by using soxi -- and you can modify it with sox.
The transcript should be plain text, without speaker indications, comments, stage directions, etc. It can (and should) include notes on various non-speech sounds:
{breath} {noise} {laugh} {cough} {lipsmack}{SL}
(where "{SL}" means silence). We'll see later how to transform transcripts in various other formats in a suitable way.
3. The command to perform the alignment has the form
segment.py wavfile trsfile outputfile_alignment outputfile_words
where "wavfile trsfile outputfile_alignment outputfile_words" are four arbitrary file names, two inputs and two outputs. This is a python wrapper, written by Jiahong Yuan, for the HTK "Hidden Markov Model Toolkit". Jiahong also prepared the acoustic models.
To try this out for yourself, you should start by creating a subdirectory (= "folder") to work in, for example
cd $HOME mkdir AlignTest
Then copy to that location, from /plab/L521, the audio file CPAC1x2.wav and the transcript file CPACx2.txt:
cd /plab/L521 cp CPAC1x2.wav CPAC1x2.txt $HOME/AlignTest
That audio is from the start of this Morning Edition story:
and the transcript looks like this:
Many conservative activists are at a gathering just outside Washington. It's the annual Conservative Political Action Conference, or C PAC.
This is a must attend event
for potential G O P presidential candidates.
Today former Florida governor Jeb Bush will speak. Yesterday there were some strong statements from other big-name Republicans expected to run, including Wisconsin governor Scott Walker, whose sudden rise in the polls, especially in Iowa, has gotten him a lot of attention. Here's N P R's Don Gonyea.
Now you should be able to execute
cd $HOME/AlignTest
segment.py CPAC1x2.wav CPAC1x2.txt CPAC1x2.align CPAC1x2.words
(You can ignore the many WARNING messages generated by HTK...)
The .wrd ("words") output file contains one line per input word, with estimated start and end times in seconds
0.0125 0.1325 {SL}
0.1325 0.2925 Many
0.2925 0.8425 conservative
0.8425 1.5625 activists
1.5625 1.6825 are
1.6825 1.8125 at
1.8125 1.8425 a
1.8425 2.2825 gathering
2.2825 2.5225 just
2.5225 2.8925 outside
2.8925 3.4225 Washington
After two lines that don't matter to us here, the "align" output file contains one line per hypothesized phonetic segment, with estimated start and end times in units of 100 microseconds (tenth of a millisecond). In addition, the segments that begin a word have an extra field representing the word. (This is a standard form for HTK output files...)
#!MLF!#
"/tmp/myl_9840.rec"
0 0 sp -0.156736 sp
0 1200000 sil -97.223206 {SL}
1200000 1600000 M 20.978649 MANY
1600000 1900000 EH1 44.813168
1900000 2300000 N 71.031631
2300000 2800000 IY0 45.456978
2800000 2800000 sp -0.156736 sp
2800000 3400000 K 32.391029 CONSERVATIVE
3400000 3700000 AH0 31.655924
3700000 4000000 N 6.362144
4000000 5300000 S 182.738312
5300000 6200000 ER1 180.644257
6200000 6700000 V 97.627357
6700000 7000000 AH0 44.233978
7000000 7300000 T 33.834343
7300000 7700000 IH0 56.453571
7700000 8300000 V 111.478081
8300000 8300000 sp -0.156736 sp
8300000 10300000 AE1 -16.515697 ACTIVISTS
10300000 10900000 K 46.422062
10900000 11500000 T -62.413967
11500000 11900000 IH0 78.903839
11900000 12700000 V 265.881256
12700000 13300000 AH0 171.342468
13300000 14500000 S 150.116013
14500000 15500000 S 65.163620
15500000 15500000 sp -0.156736 sp
Note that the "word" file times, in seconds, are not only divided by 10,000,000, but also have .0125 seconds (12.5 milliseconds) added. The added time is due to the fact that HTK's times represent the beginning of a 25-msec analysis window.
4. To turn the "align" file into a Praat TextGrid, you can execute e.g.
align2textgrid CPAC1x2.align >CPAC1x2.TextGrid
The align2textgrid program is here. Create a directory $HOME/bin, if it doesn't already exist; put the align2textgrid program there; and make sure that your bin directory is on your $PATH.
Run the align2textgrid program as suggested above; copy the resulting .TextGrid file to an interactive computer (e.g. your laptop), along with the associated .wav file; and use Praat to inspect and check the alignment.
5. A sightly longer example is Barack Obama's weekly radio address from 1/9/2010 (transcript here):
soxi tells us that it's 5:54.37 long:
$ soxi 010910_WeeklyAddress.wav
Input File : '010910_WeeklyAddress.wav'
Channels : 1
Sample Rate : 16000
Precision : 16-bit
Duration : 00:05:34.37 = 5349878 samples ~ 25077.6 CDDA sectors
File Size : 10.7M
Bit Rate : 256k
Sample Encoding: 16-bit Signed Integer PCM
Again, copy the 010910_WeeklyAddress.wav and 010910_WeeklyAddress.txt files from /plab/L521 to your AlignTest directory, and align the file via:
segment.py 010910_WeeklyAddress.wav 010910_WeeklyAddress.txt 010910_WeeklyAddress.align 010910_WeeklyAddress.wrd
And then create a textgrid:
align2textgrid 010910_WeeklyAddress.align >010910_WeeklyAddress.TextGrid
As a check, copy 010910_WeeklyAddress.wav and 010910_WeeklyAddress.TextGrid from your AlignTest directory on harris.sas.upenn.edu to your local machine, and check in Praat that the alignment is a sensible one.
6. You will often want to integrate signal analysis data with time estimates. Praat offers (typically opaque) ways to do this, but you should also learn to do it yourself -- one approach is described here.
Use get_f0a (in /usr/local/bin on harris) to derive f0 and RMS estimates for the 010910_WeeklyAddress.wav file in your AlignTest directory:
get_f0a -i 010910_WeeklyAddress.wav >010910_WeeklyAddress.f0
This informs you of the frame step -- the default is 0.005 seconds, or 200 frames per second -- and produces a text file, 010910_WeeklyAddress.f0, one "frame" per line, with four columns:
The first column is the f0 estimate (0 if the frame is judged to be unvoiced); the second column is 1 for voiced frames and 0 for voiceless ones; the third column is the RMS ("root mean square") amplitude of the signal in that frame; and the fourth column is the serial cross-correlation value of the signal with itself at the lag corresponding to the f0 estimate. (See here for more on what this means...)0.000000 0.000000 0.000000 0.066041 0.000000 0.000000 0.651639 0.219939 0.000000 0.000000 8.019460 0.157286 0.000000 0.000000 20.335880 0.347384 0.000000 0.000000 28.691460 0.466157 0.000000 0.000000 34.468380 0.454464 0.000000 0.000000 45.828236 0.356620 0.000000 0.000000 48.911327 0.356126 0.000000 0.000000 47.427158 0.533596 0.000000 0.000000 78.735306 0.546654 0.000000 0.000000 147.684036 0.751607 0.000000 0.000000 266.498199 0.755252 101.424843 1.000000 364.945343 0.843737 99.401398 1.000000 455.015289 0.736799 114.947121 1.000000 547.264648 0.575233 110.781487 1.000000 626.479492 0.882464 110.946701 1.000000 680.767334 0.922071 110.759850 1.000000 728.275452 0.809053 117.469421 1.000000 771.252197 0.671672
The 010910_WeeklyAddress.wrd file that you created earlier will include a stretch like this, representing the calculated alignments of a sentence in the middle of the transcript:
153.0025 153.7025 sp
153.7025 153.7925 And
153.7925 153.9725 that's
153.9725 154.0825 what
154.0825 154.2025 I'd
154.2025 154.3725 like
154.3725 154.4625 to
154.4625 154.8425 focus
154.8425 154.9825 on
154.9825 155.1725 for
155.1725 155.2025 a
155.2025 155.4425 moment
155.4425 156.1125 sp
The corresonding audio:
Now use the approach described here to interpret what "frames" in the .f0 file the start and end times (153.705 to 156.1125) correspond to; read the .f0 file into R; and plot the estimated f0 contour for that sentence.
As discussed, the nature of fundamental frequency analysis via "serial cross-correlation analysis" (the most commonly used current method) means that a given f0 estimate comes from a region of the signal that depends on what the estimate is. However, the effects are generally fairly small -- in the this case, we can interpret
FrameNumber = (Time - Window/2)/FrameStep + 1
to involve a "Window" of roughly the estimated pitch period, and a "FrameStep" of 0.005 seconds. Rather than adjust this calculation for every period estimate, we can use R to calculate the mean f0 of the file in question, which will turn out to correspond to a period of about 8 or 9 milliseconds:
> X=read.table("010910_WeeklyAddress.f0")
> F0=X[,1]; mean(F0[F0>0])
[1] 116.3789
> 1/mean(F0[F0>0])
[1] 0.00859262
So we can translate the start and end times of our chosen sentence into frame numbers like this:
(153.705 - 0.45)/0.005 + 1 → 30652
(156.1125 - 0.45)/0.005 + 1 → 31133
(You can see that sightly different choices for the analysis window size will not change the frame-number calculations very much.)
Now we can plot that sentence's pitch estimates in a few lines of R:
> X=read.table("010910_WeeklyAddress.f0")
> F0=X[,1]
> Time=(30652:31133)*.005
> plot(Time,F0[30652:31133],ylab="F0")
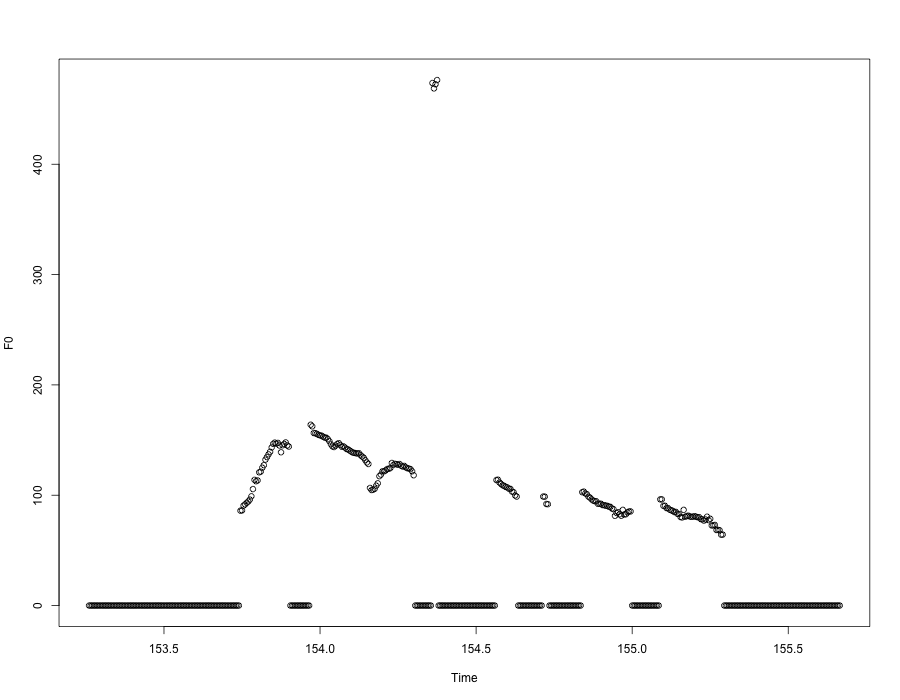
If we restrict the y-axis range to eliminate the mis-tracked points in the middle of the sentence, we'll get something closer to what we hear:
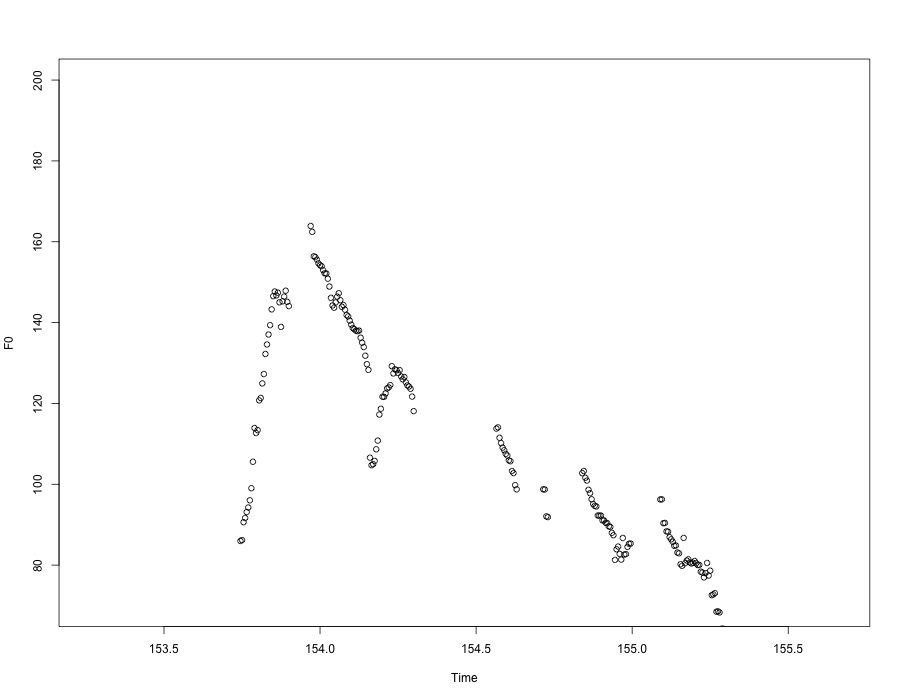
Now do the same thing for another phrase somewhere in that file...
And use Praat on the 010910_WeeklyAddress.wav and 010910_WeeklyAddress.TextGrid files (on your own machine) to check your results.
7. Now try doing forced alignment with your own sample of speech data. It can be a short sentence, or a long interview -- your choice. I recommend starting with a short clip of decent recording quality, to verify that everything is working for you.
Later on, we'll learn how to correct such alignments with minimal human labor, and how to create and use aligners for other languages.
[Forced aligner code by Jiahong Yuan]