Types of Language Change
Language is always changing. We've seen that language changes across space and across social group. Language also varies across time.
Generation by generation, pronunciations evolve, new words are borrowed or invented, the meaning of old words drifts, and morphology develops or decays. The rate of change varies, but whether the changes are faster or slower, they build up until the "mother tongue" becomes arbitrarily distant and different. After a thousand years, the original and new languages will not be mutually intelligible. After ten thousand years, the relationship will be essentially indistinguishable from chance relationships between historically unrelated languages.
In isolated subpopulations speaking the same language, most changes will not be shared. As a result, such subgroups will drift apart linguistically, and eventually will not be able to understand one another.
In the modern world, language change is often socially problematic. Long before divergent dialects lose mutual intelligibility completely, they begin to show difficulties and inefficiencies in communication, especially under noisy or stressful conditions. Also, as people observe language change, they usually react negatively, feeling that the language has "gone down hill". You never seem to hear older people commenting that the language of their children or grandchildren's generation has improved compared to the language of their own youth.
Here is a puzzle: language change is functionally disadvantageous, in that it hinders communication, and it is also negatively evaluated by socially dominant groups. Nevertheless is is a universal fact of human history.
How and why does language change?
There are many different routes to language change. Changes can take originate in language learning, or through language contact, social differentiation, and natural processes in usage.
Language learning: Language is transformed as it is transmitted from one generation to the next. Each individual must re-create a grammar and lexicon based on input received from parents, older siblings and other members of the speech community. The experience of each individual is different, and the process of linguistic replication is imperfect, so that the result is variable across individuals. However, a bias in the learning process -- for instance, towards regularization -- will cause systematic drift, generation by generation. In addition, random differences may spread and become 'fixed', especially in small populations.
Language contact: Migration, conquest and trade bring speakers of one language into contact with speakers of another language. Some individuals will become fully bilingual as children, while others learn a second language more or less well as adults. In such contact situations, languages often borrow words, sounds, constructions and so on.
Social differentiation. Social groups adopt distinctive norms of dress, adornment, gesture and so forth; language is part of the package. Linguistic distinctiveness can be achieved through vocabulary (slang or jargon), pronunciation (usually via exaggeration of some variants already available in the environment), morphological processes, syntactic constructions, and so on.
Natural processes in usage. Rapid or casual speech naturally produces processes such as assimilation, dissimilation, syncope and apocope. Through repetition, particular cases may become conventionalized, and therefore produced even in slower or more careful speech. Word meaning change in a similar way, through conventionalization of processes like metaphor and metonymy.
Some linguists distinguish between internal and external sources of language change, with "internal" sources of change being those that occur within a single languistic community, and contact phenomena being the main examples of an external source of change.
The analogy with evolution via natural selection
Darwin himself, in developing the concept of evolution of species via natural selection, made an analogy to the evolution of languages. For the analogy to hold, we need a pool of individuals with variable traits, a process of replication creating new individuals whose traits depend on those of their "parents", and a set of environmental processes that result in differential success in replication for different traits.
We can cast each of the just-listed types of language change in such a framework. For example, in child language acquisition, different grammatical or different lexical patterns may be more or less easily learnable, resulting in better replication for grammatical or lexical variants that are "fitter" in this sense.
There are some key differences between grammars/lexicons and genotypes. For one thing, linguistic traits can be acquired throughout one's life from many different sources, although intitial acquisition and (to a lesser extent) adolescence seem to be crucial stages. Acquired (linguistic) traits can also be passed on to others. One consequence is that linguistic history need not have the form of a tree, with languages splitting but never rejoining, whereas genetic evolution is largely constrained to have a tree-like form (despite the possibility of transfer of genetic material across species boundaries by viral infection and so on). However, as a practical matter, the assumption that linguistic history is a sort of tree structure has been found to be a good working approximation.
In particular, the basic sound structure and morphology of languages usually seems to "descend" via a tree-structured graph of inheritance, with regular, lawful relationships between the patterns of "parent" and "child" languages.
Types of Change
Sound change
All aspects of language change, and a great deal is know about general mechanisms and historical details of changes at all levels of linguistic analysis. However, a special and conspicuous success has been achieved in modeling changes in phonological systems, traditionally called sound change. In the cases where we have access to several historical stages -- for instance, the development of the modern Romance Languages from Latin -- these sound changes are remarkably regular. Techniques developed in such cases permit us to reconstruct the sound system -- and some of the vocabulary -- of unattested parent languages from information about daughter languages.
In some cases, an old sound becomes a new sound across the board. Such a change occurred in Hawai'ian, in that all the "t" sounds in an older form of the language became "k"s: at the time Europeans encountered Hawai'ian, there were no "t"s in it at all, though the closely related languages Tahitian, Samoan, Tongan and Maori all have "t"s.
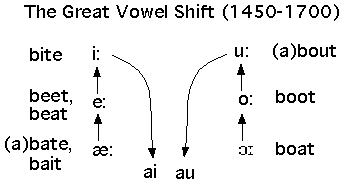
Another unconditioned sound change that occurred between Middle and Early Modern English (around Shakespeare's time) is known as the Great Vowel Shift. At that time, there was a length distinction in the English vowels, and the Great Vowel Shift altered the position of all the long vowels, in a giant rotation.
The nucleus of the two high vowels (front "long i" /i:/, and the back "long u" /u:/) started to drop, and the high position was retained only in the offglide. Eventually, the original /i:/ became /ai/ - so a "long i" vowel in Modern English is now pronounced /ai/ as in a word like 'bite': /bait/. Similarly, the "long u" found its nucleus dropping all the way to /au/: the earlier 'house' /hu:s/ became /haus/. All the other long vowels rotated, the mid vowels /e:/ and /o:/ rising to fill the spots vacated by the former /i:/ and /u:/ respectively, and so on. That is why the modern pronouns 'he' and 'she' are written with /e/ (reflecting the old pronunciation) but pronounced as /i/. In the following chart, the words are located where their vowel used to be pronounced -- where they are pronounced today is indicated by the arrows.
In other cases, a sound change may be "conditioned" so as to apply in certain kinds of environments and not in others. For example, it's very common for tongue-tip ("coronal") consonants to become palatal when they are followed by high front vowels. The residue of this process can be seen in English pairs like divide/division, fuse/fusion, submit/submission, oppress/oppression.
Processes of sound change.
Another dimension along which we can look at sound change is by classifying changes according to the particular process involved.
Assimilation, or the influence of one sound on an adjacent sound, is perhaps the most pervasive process. Assimilation processes changed Latin /k/ when followed by /i/ or /y/, first to /ky/, then to "ch", then to /s/, so that Latin faciat /fakiat/ 'would make' became fasse /fas/ in Modern French (the subjunctive of the verb faire 'to make').Palatalization is a kind of assimilation.
In contrast to assimilation, dissimilation, metathesis, and haplology tend to occur more sporadically, i.e., to affect individual words. Dissimilation involves a change in one of two 'same' sounds that are adjacent or almost adjacent in a particular word such that they are no longer the same. Thus the first "l" in English colonel is changed to an "r", and the word is pronounced like "kernel". Metathesis involves the change in order of two adjacent sounds. Crystal cites Modern English third from OE thrid , and Modern English bird is a parallel example. But Modern English bright underwent the opposite change, its ancestor being beorht, and not all "vowel + r" words changed the relative order of these segments as happened with bird and third . Already by the time of Old English, there were two forms of the word for "ask": ascian and acsian. We don't know which form was metathesized from the other, but we do know that ascian won out in the standard language. Haplology is similar to dissimilation, because it involves getting rid of similar neighboring sounds, but this time, one sound is simply dropped out rather than being changed to a different sound. An example is the pronunciation of Modern English probably as prob'ly.
Other sound change processes are merger, split, loss, syncope, apocope, prothesis, and epenthesis. Merger and split can be seen as the mirror image of each other. A merger that is currently expanding over much of the United States is the merger between "short o" and "long open o". The following table contains examples of words that you probably pronounce differently if you are from the Philadelphia - New York - New England area, or if you are from the South. If you are from Canada, the American Midwest, or from California, you probably find that the vowels in these pairs sound the same, rather than different. If this is the case, you have a merger here.
| Short "o" | Long "Open o" |
| cot hot hock stock |
caught haughty hawk stalk |
Splits are rarer than mergers, and usually arise when a formerly conditioned alternation loses the environment that provided the original conditioning, and the previously conditioned alternation becomes two independent sounds that contrast with each other. This is basically what happened when /f/ and /v/ split in English (/v/ having previously been an alternate of /f/ when /f/ occurred in an intervocalic position).
Loss involves the loss of a sound from a language, as when Hawai'ian lost the /t/ in favor of /k/ (see below).
Syncope and apocope are the loss of medial and final sounds respectively. Middle English 'tame' in the past tense was /temede/. It lost both its medial and final vowels to become Modern English /teymd/. These are usually conditioned changes that do not involve loss of the same sound elsewhere.
Prothesis and epenthesis are the introduction of additional sounds, initially and medially respectively. The addition of the /e/ that made Latin words like scola 'school' into Portuguese escola is the only example of prothesis in foure historical linguistics textbooks I consulted. As for epenthesis, an example other than the one Crystal cites was the /d/ inserted into ME thunrian to give us the Modern English thunder.
How do we know how languages are related?
Linguists rely on systematic sound changes to establish the relationships between languages. The basic idea is that when a change occurs within a speech community, it gets diffused across the entire community of speakers of the language. If, however, the communities have split and are no longer in contact, a change that happens in one community does not get diffused to the other community. Thus a change that happened between early and late Latin would show up in all the 'daughter' languages of Latin, but once the late Latin speakers of the Iberian peninsula were no longer in regular contact with other late Latin speakers, a change that happened there would not spread to the other communities. Languages that share innovations are considered to have shared a common history apart from other languages, and are put on the same branch of the language family tree.
Words in two or more daughter languages that derive from the same word in the ancestral language are known as cognates. Sound changes work to change the actual phonetic form of the word in the different languages, but we can still recognize them as originating from a common source because of the regularities within each language. For example, a change happened in Italian such that in initial consonant clusters, the l that originally followed p and f changed to i. Thus Italian words like fiore 'flower'; fiume 'river'; pioggia 'rain'; and piuma 'feather' are cognates with the French fleur; fleuve; pluie; and plume, respectively, and with Spanish flora, fluvial (adj. 'riverine'); lluvia (by a later change); and pluma respectively.
In the Romance languages below, the word for 'mother' is a cognate in all the six contemporary languages considered, however the word for 'father' is a cognate only in four of the five: in Rumanian, the original word inherited from Latin pater has been replaced by a completely different word, tata.
Spanish and Italian are the only two that retain a phonological reflex of the original Latin medial consonant t, (in both languages, it has been voiced to d, probably a change that occurred in the common ancestor to all the dialects and languages of the Iberian peninsula. All the other Romance languages have dropped it. The original r has also suffered different fates: however, within each language, the same thing happened in both words. Where we find r deleted in final position in the word for 'mother', we also find it deleted in the same position in the word for 'father'.
| English Gloss | French | Italian | Spanish | Portuguese | Rumanian | Catalan | mother | mer | madre | madre | mae | mama | mare | father | per | padre | padre | pae | tata | pare |
The same principles are applied in languages that do not have a written history. Several cognate sets in five languages of the Polynesian family are listed in the next table.
| English Gloss |
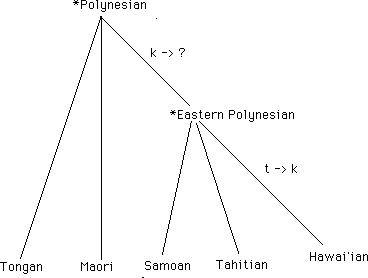
Tongan | Maori | Samoan | Tahitian | Hawai'ian | 1. bird | manu | manu | manu | manu | manu | 2. fish | ika | ika | i?a | i?a | i?a | 3. to eat | kai | kai | ?ai | ?ai | ?ai | 4. forbidden | tapu | tapu | tapu | tapu | kapu | 5. eye | mata | mata | mata | mata | maka | 6. blood | toto | toto | toto | toto | koko |
We see that no changes happened in the nasal consonants, nor in the vowels, but we can observe in lines 2 and 3 that wherever Tongan and Maori have /k/, Samoan, Tahitian and Hawai'ian appear to have /?/ (glottal stop). Apparently there has been an unconditioned change from /k/ to /?/ in the Eastern branch, or a change from /k/ to /k/ in the Western branch of this family. We choose the first as more likely, partly because /t/ is a more common phoneme in the world's languages, partly because backing of consonants is more common than fronting, and partly because of what we know about the culture history: Polynesia was peopled from west to east, and if the change had occurred in the Western branch, that would have been at a time when all five languages were still one speech community. Next, we see in lines 4 - 6 that there is a systematic correspondence between /t/ in the first four languages and /k/ in the easternmost, Hawai'ian. This looks like another systematic, unconditioned sound change, this time in only one language. (We can see from this example that when English borrowed the Polynesian word for "forbidden", we borrowed it from one of the languages west of Hawaii -- we say "taboo", not "kaboo"). This is what a family tree of the five Polynesian languages would look like, based on the small data set above (the picture is somewhat more complex when we look at other cognate sets -- Maori in particular is probably not correctly placed in this diagram, which has been designed as an illustration of the method):
Historical Reconstruction vs. Lexicostatistics
In the examples just discussed, the central enterprise has been to establish a systematic pattern of change, most often sound change: every original Malayo-polynesian /t/ becomes /k/ in Hawaiian, and we can cite many correspondences of cognate pairs to prove it. This level of understanding is useful for several reasons.
First, a systematic pattern of phonological correspondence across many words is unlikely to have arisen by chance, whereas completely unrelated languages often develop surprising similarities in particular words, entirely by chance.
Second, given systematic patterns of this type, we can start to apply the comparative method to reconstruct the parent language. This in turn allows us to examine relationships among reconstructed languages at a greater time depth, even if the process of change entirely obscures the relationships among the vocabulary items in the child languages.
However, establishing patterns of this type is difficult. It requires a large vocabulary in all the languages being compared, in order to find enough cognates; and it also requires a deep knowledge of the grammar of each of the languages, in order to see cognate relationships that might be obscured by morphology and contextual phonological change -- and not to be fooled into seeing false cognates where morphology or phonology have created chance similarities.
Another approach, pioneered by the American Structuralist linguist Morris Swadesh, is called lexicostatistics. For a set of languages of interest, we get a small vocabulary list of common, basic words (typically 100-200 items). For each pair of languages, we determine the percentage of words on this list that appear to be cognate. Determination of cognation is dependent on the subjective judgment of the linguist, and we expect some errors, especially if the scholar does not know the languages very well, but we hope that the error rate will be small enough not to affect the results.
We can then arrange these cognate percentages in a table, from which we draw some conclusions about the degree of relationship among the languages involved.
Here is a recent example, drawn from Central Yambasa Survey Report, by Boone et al., discussing languages of the Centre Province of Cameroon:
| Gunu [two lists] | ||||||||
|---|---|---|---|---|---|---|---|---|
| 82 | Elip | |||||||
| 85 | 90 | Mmala [two lists] | ||||||
| 78 | 90 | 89 | Yangben[two lists] | |||||
| 77 | 81 | 81 | 88 | Baca [two lists] | ||||
| 66 | 72 | 72 | 77 | 78 | Mbule [two lists] | |||
| 58 | 63 | 64 | 66 | 70 | 69 | Bati | ||
| 42 | 41 | 42 | 42 | 42 | 46 | 45 | Hijuk [two lists] | |
| 39 | 38 | 41 | 38 | 37 | 40 | 41 | 88 | Basaa |
Table 5 New lexical similarity percentages for
Central Yambasa
and selected neighbouring tongues
From this table, we can conclude that Elip, Mmala and Yangben are "closely related speech varieties"; that they are somewhat more distant from Gunu, Baca and Mbule; that they are even more distant from Bati; and that they are further yet from Hijuk and Basaa. Based on this sort of consideration, we can construct a sort of family tree, just as we might based on patterns of sound change.
There has been a great deal of controversy about whether family trees based on lexicostatistics are reliable. Those who doubt it point to the possibility that cognate percentages might be strongly affected by vocabulary borrowing, either in a negative or positive direction. For instance, Japanese borrowed many words from Chinese without becoming a Sino-Tibetan language; it has recently borrowed many words from English without becoming an Indo-European language. Those who favor lexicostatistics argue that this sort of borrowing is less common in the basic-vocabulary wordlists that they use.
There are two distinct controversies about the use of lexicostatistical methods. One issue is whether the family trees produced for languages with fairly high cognate percentages (say 60% and higher) are a reliable indication of the detailed structure of "genetic" relationships among languages. Everyone accepts that two languages with 85% cognates are certainly related; the only question is whether they are (necessarily) "more closely related" in a historical sense than either is to a language whose cognate percentages with both are (say) 80%.
For example, we might have a situation in which proto-language A splits into B and C. C in turn splits into D and E. E then undergoes a period of close contact with a completely unrelated language, Z, as a result of of which it borrows a lot of new vocabulary. Now E has a lower cognate percentage with D than D has with B; but the historical fact is that E is more closely related to D than D is to B.
The second controversy is what to make of relationships involving very low cognate percentages, say below 10%. Depending on the nature of the languages and the methods used to determine cognation, these percentages are getting into the range that could (it is argued) arise by chance, or by superficial or indirect recent contact.
Glottochronology
Swadesh and others took this type of analysis further, based on the idea that the average rate of loss of cognates could be regarded as constant over historical time, just like the rate of radioactive decay. Swadesh looked at some languages where historical stages are well documented, and concluded that basic vocabulary decays by 14 percent every millenium. According to the entry on Swadesh in the Encyclopedia of Linguistics:
Thus, if the basic vocabularies of two related languages are found to match by 70 percent, they can be assumed to have developed from a single language that existed approximately 12 centuries before.The assumption that basic vocabulary decay is generally uniform has been largely rejected. If one allows that languages, just like societies, may develop at different rates at different times, the assumption of steady vocabulary decay in particular, and the glottochronological method in general, is seriously undermined.
Everyone recognizes that linguistic decay is not completely uniform. Some people still believe that it is sometimes uniform enough for glottochronological methods to be a useful approximate guide to linguistic (and thus ethnic) history.
What are the results of language change?
When accompanied by splits of populations, language change results first in dialect divergence (the kinds of differences we see between British and American English; between the French of France and of Quebec; between New World and Old World Spanish and Portuguese). Over longer time periods, we see the emergence of separate languages as in the contemporary Romance languages, separated by about 2000 years, and the Germanic languages, whose divergence began perhaps 500 years earlier. Both of these families are part of Indo-European , for which the Ethnologue web page currently lists 455 languages! Though political considerations often intervene in whether a particular speech variety is considered to be a language or a dialect, the basic idea behind linguistic classifications is that dialects are mutually intelligible, whereas languages are not.
Of course, the question of intelligibility is always relative. The following phrases taken from the spontaneous speech of Chicagoans recorded in the early 1990s were difficult for many non-Chicagoans to understand correctly. In "gating" experiments designed to test cross-dialectal comprehension in American English, subjects first heard a word, then a slightly longer segment, then a whole phrase or sentence that may have disambiguated the original mishearing. These experiments were part of the research project on Cross-Dialectal Comprehension done at the Linguistics Lab here at Penn (for more information on the Northern Cities Shift, see "The Organization of Dialect Diversity" on the home page of the Phonological Atlas of North America .)
| Original segment | Many people misheard as | First expansion | Second expansion | drop | ??? (nonsense word containing vowel in "that") | massive drop |
the plane was steady for a while and then it took a massive drop |
| socks | sacks | y'hadda wear socks | y'hadda wear socks, no sandals |
| block | black | one block | old senior citizens living on one block |
| met | mutt | they met | my parents went to Cuba and that's where they met |
| steady | study | steady for a while | the plane was steady for a while and then it took a massive drop |
| head | had | shook 'er head | this woman in while, who just smiled at her and shook 'er head |
These misunderstandings are based on the fact that the Chicago speakers (along with 40 - 50 million other people in the "Inland North" dialect including Rochester, Buffalo, Detroit, Syracuse, and other cities of that region) have a rotation of their short vowels such that the low unrounded vowel of the "short o" words like drop, socks, block, and hot is being fronted to the position where other American dialects have words like that, hat, black, rap, and sacks, , and where "short e" words like met, steady and head can sound like mutt, study and thud or mat, static and had.
The Ethnologue data base includes 7168 living languages, spoken in more than 220 countries. They state that their "criterion for listing speech varieties separately is low intelligibility, as far as that can be ascertained."
How far back can we go?
Most linguists agree that our methods for reconstruction will take as only as far back as about 5000 - 7000 years; after that, the number of cognate sets available for reconstruction becomes just too low to give results that can be reliably distinguished from chance relationships. Although it would be very satisfying to be able to link up some of the existing families at a higher level, the evidence seems too weak to allow us to do so. A minority of scholars, however, argue that this is possible, and one particularly well-known group of such scholars goes by the name of Nostraticists, derived from their views that there exists a super-family of language they have called the "Nostratic", which would include not only Indo-European languages but also Uralic languages such as Finnish and Hungarian, and Afro-Asiatic languages such as Arabic, Hebrew, Hausa and Somali. A New York Times article from 1995 presents a well-balanced view of the Nostraticist position. Dr. Donald Ringe of the Penn Linguistics Department, himself an expert on the ancient Indo-European language Tocharian, is one of the chief critics of the Nostraticist position.
The current Ethnologue listing of "language families" includes 142 members, from Abkhaz-Adyghe to Zaparoan. This does not mean that human language was developed independently 142 times -- it only means that generally-accepted methods can't establish any further relationships among these groupings, at least not for sure.
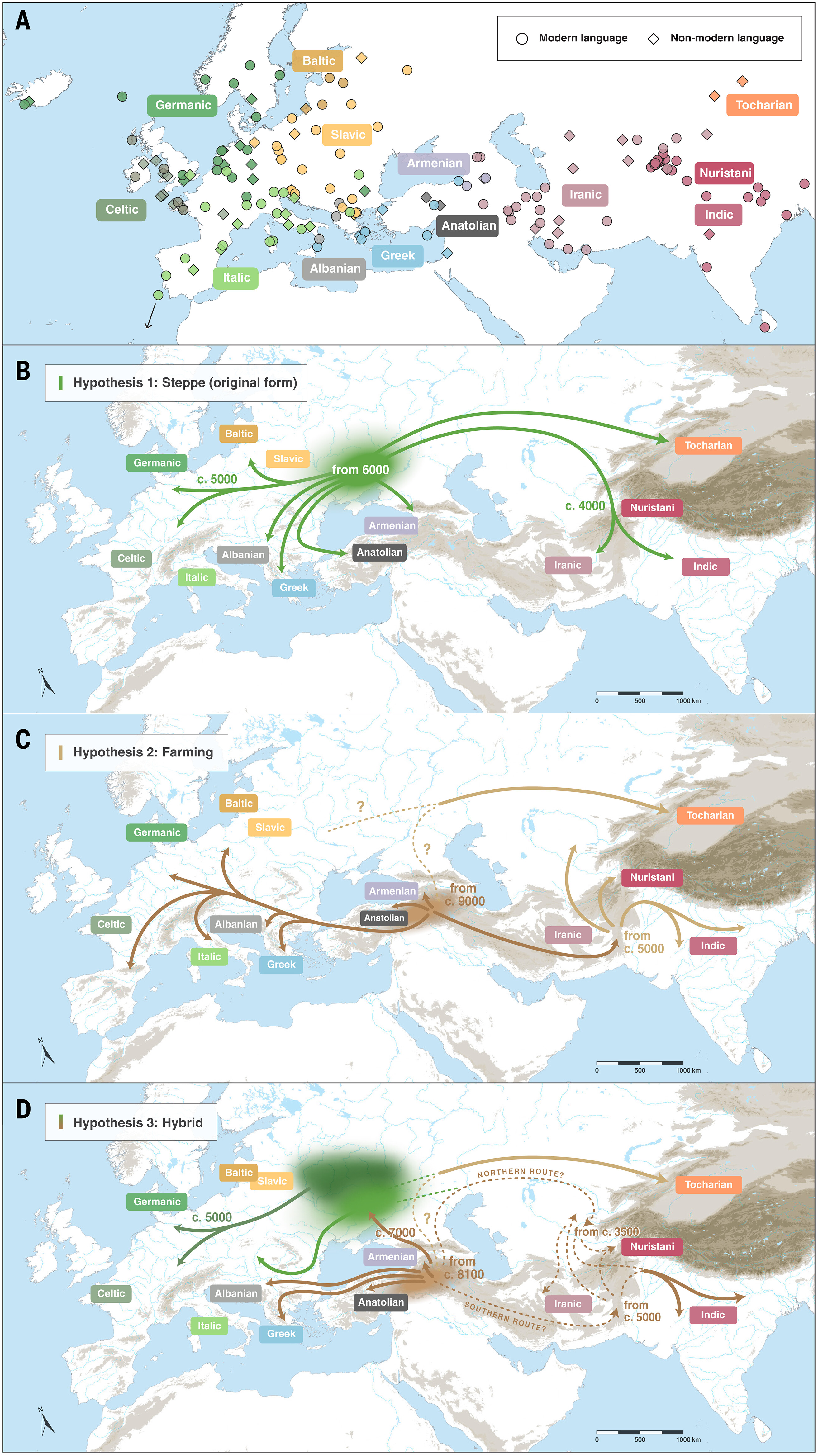
An important recent contribution was Heggarty et al., "Language trees with sampled ancestors support a hybrid model for the origin of Indo-European languages", Science 2023. The conclusions are summarized in this figure:
Other (optional) links on debated historical reconstructions
Founding fathers of the Amerind debate
Splitters and lumpers -- then and now