Linguistics 520: Lab Assignment #2
9/4/2013: Due 9/10/2013
Goals:
1. Learn the basics of interpreting waveforms and spectrograms
2. Learn to do word-level segmentation in Praat textgrids
3. Learn to transfer Praat segmentation into R dataframes
4. Prepare to do basic word-level duration modeling
As a result of the previous lab, you should have a directory ("folder") containing 100 files named something like Lab1X001.wav, Lab1X002.wav, ..., Lab1x100.wav. (The exact names don't matter, though it will be helpful if the names end in numbers 001.wav through 100.wav.)
Now you need to learn three things, if you don't already know them. The first one is how to interpret waveforms and spectrograms so as to mark the boundaries between the digits in your recordings. The second one is how to use the Praat program to put the results of this interpretation into a computer file. And the third one is how to do this efficiently -- or at least no more inefficiently than necessary.
Your specific assignment for this lab is to segment your first ten digit-string files at the word (i.e. digit) level, in the style described below, creating and saving corresponding Praat TextGrid files. I suggest that you do one file "by hand", and then use the Praat script described below to re-do that one and the next nine examples.
How to use Praat to choose and mark the boundaries
We assume that you know how to read one of your digit-string recordings into Praat, and "view and edit" it along with an empty TextGrid. If you don't know how to do this, go through the early stages of one of the many Praat tutorials on the web, or ask someone in the lab to show you how to get started. The basic recipe is to open the audio file using the Open>>Read from file... menu item in the Praat Objects window; then create an empty TextGrid by selecting the resulting Sound object in the Objects list and using the Annotate>>To TextGrid... menu item; then
The boundaries that you will need to deal with are of three basic types. In the first type of boundary, there's a fairly sharp and well-defined juncture between two regions that are acoustically quite different.
For example, here's the start of the digit sequence 752-955-0354:
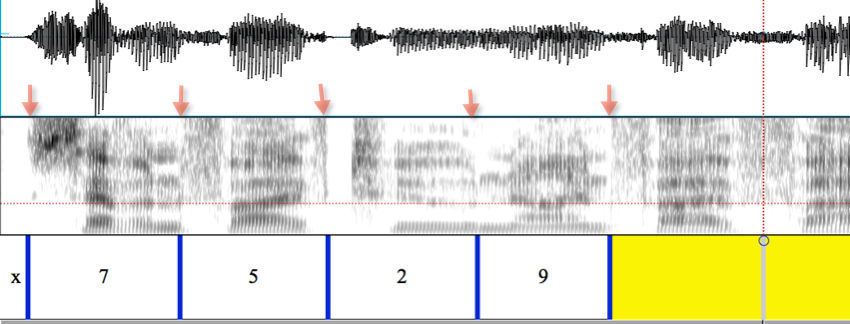
The boundary between silence (here marked as 'x') and the initial [s] of "seven" is the change from nothing to something, and so here (where the background is pretty quiet) it's easy to see.
The boundary between the final [n] of "seven" and the initial [f] of "five" is also easy to see: the nasal murmur is voiced (shows the acoustic result of the quasi-periodic oscillation of the vocal folds, with strong low-frequency energy), while the [f] is a fricative (with the noise-like sound caused by turbulent flow of air past the upper teeth and lower lip, and relatively little low-frequency energy.)
The boundary between the final /v/ of "five" and the initial [t] of "two" is clearly marked, because the stop gap of 2's [t] is basically another silence, though a short one. Note that the final /v/ of 5, though nominally a voiced fricative, in fact has no voicing -- phonetically, it's just a short version of [f]. That's why I used the forward slashes /v/ to indicate that 'v' here is a phonemic label, not a phonetic one. (We'll discuss later in what ways and to what extent this is a coherent distinction...)
The boundary between the final /u/ of "two" and the initial nasal murmur of "nine" is again well marked.Both are voiced, but the nasal murmur has a very different resonance pattern, and the transition between the two patterns is a fairly rapid one.
But now we come to a second type of boundary, where two adjacent "segments" effectively merge into one: the jucture between the final /v/ of "five" (which can be basically just a short [f], remember) and the initial [f] of the second "five". There's no clear re-articulation or other marking to indicate where one stops and the other starts.
Based on the previous examples, we might guess that the final [f] should be shorter than the initial one -- but we have to signal-internal basis for making that judgment, so in such cases you should just "split the difference" by placing the boundary in the middle of the common region, and move on. If you check your choice by playing the resulting segments, this should validate your decision, or at least not show it to be wrong.
Now we come to a new variant of something that we've already seen: the boundary between the digit "five" and a following sound. The new twist here is that in this case, the final /v/ of "five" is voiced, as we can see clearly in the waveform:
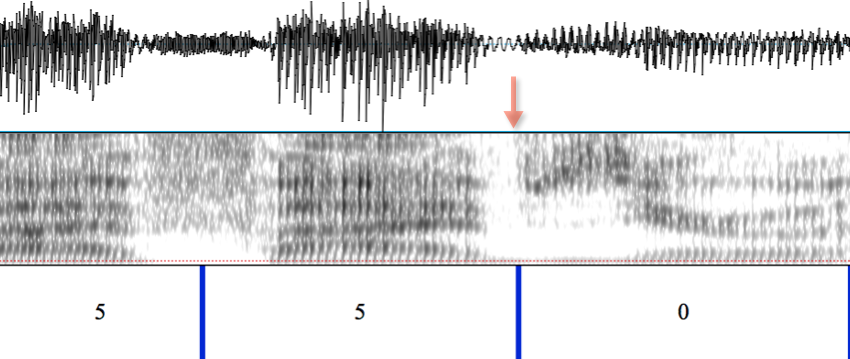
That's because the next segment -- the initial [z] of "zero" -- is also voiced. In this case, the boundary between the /v/ segment and the [z] segment is also quite plain, because the [z] segment is strident (i.e. noisy, in plain language), while the /v/ is realized with little or no turbulent noise -- it's basically an approximant, or what is sometimes called a "frictionless fricative".
For the third basic type of segmentation that you'll encounter in this exercise, let's look at the transitions "five eight" and "zero eight" in the string 519-158-1081:
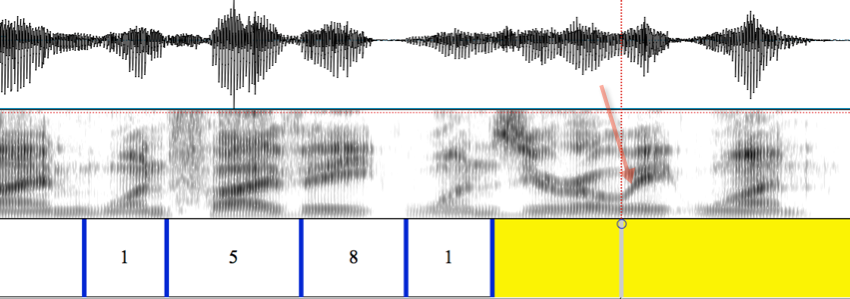
The "five eight" transition is similar to what we've seen before: the final /v/ of "five" finally emerges as a voiced fricative [v], but the boundary between it and the initial vowel of "eight" is clear enough. And we can see that the vowel of "eight" is slightly diphthongal -- the first and second formants, appearing here as the lower-frequency two darker bands in the spectrogram, are moving apart, signaling movement higher and fronter in the vowel space, corresponding to the off-glide in [ei].
But when we come to the boundary between the final vowel of "zero" and the initial vowel of "eight" -- marked with the red arrow in the figure above -- we see something new.
Because our vocal organs can't move from one position to another without traversing the space in between, and because the inertia and other physical qualities of the lips and the tongue body make them relatively sluggish organs, the transition from the /o/ configuration to the /e/ configuration takes an amount of time that's fairly large relative to the duration of the phonetic segments we're looking at.
In this case, it takes around 50 milliseconds. This is about the same length as the final [v] of the "five" in the picture. So where should we place the boundary? Logically, this transition doesn't really belong to either of the segments that it connects.
And this situation tells us something central about speech: the acoustic segments that we've been looking at up to this point are basically illusions created by non-linearities in the mapping between articulation and sound. From a phonetic point of view, it's wrong to think of speech as beads on a string -- adjacent phonetic gestures always overlap to a considerable degree, something like this:
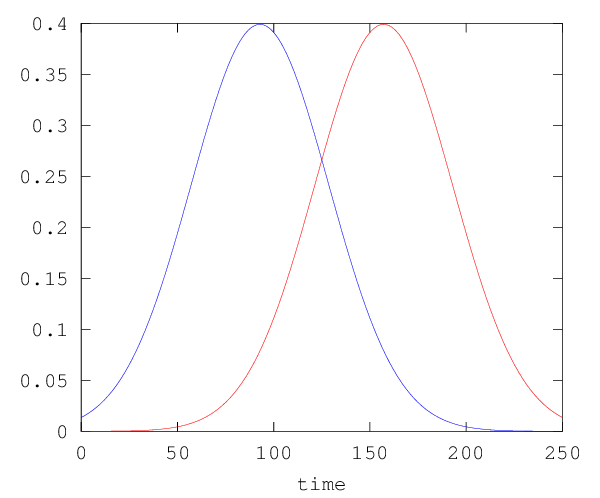
Even when we get a relatively sharp acoustic boundary, created by an event like an oral closure or release, or the phase transition between vocal-cord oscillation and no vocal-cord oscillation, the underlying articulatory gestures are heavily co-articulated (i.e. overlapped). We'll discuss this issue at much greater length at later points in the course.
How to use a Praat script to mark boundaries somewhat more efficiently
You will probably have noticed by now that phonetics research can be somewhat tedious.
In due course, we'll learn about the glorious future in which all the tedium is taken over by computers, and we humans can concentrate on the things that most of us are better at, or at least enjoy more. (You should already be grateful that you don't need to make and measure paper spectrograms...)
To start with, it's instructive to do some of this work by hand, because it's a way to learn what the phenomena of speech are like. In other words, up to a certain point the tedium of segmenting utterances is Good For You.
However, you learn nothing about phonetics from the repetitive process of opening audio files, creating TextGrids, saving the TextGrids to appropriately-named files, removing sound and TextGrid objects from Praat's Objects window, etc., etc. Forty years ago, the iterated tasks would have been putting a sheet of special paper around the drum of an electro-mechanical spectrograph machine, aligning the relevant segment of audio tape around a different drum, and inhaling the fumes as the stylus burned a spectrogram image into the paper. You wouldn't have learned anything about phonetics from that process either, and you're lucky to have avoided it by temporal accident.
Because Praat has an internal scripting language, many of the operations that you can perform by hand can be automated. And this script, which you'll learn to use in class, will take care of everything except the segmentation process itself.
More detailed instructions:
(1) Put the Praat script TextGridMaker.Praat in the same directory as your audio files.
(2) In Praat, use Praat>>Open Praat script... to open that script.
(3) This will create a window in which you can edit the file. Find the passage near the top of the file that reads
form Enter directory and search string
# Be sure not to forget the slash (Windows: backslash, OSX: forward slash) at the end of the directory name.
sentence Directory /Users/myl/data/ling520/Lab1/
sentence Word Lab1X09
sentence Filetype wav
endform
and make two changes:
(a) modify the directory (= folder) name /Users/myl/data/ling520/Lab1 so that it corresponds to the directory you're working in.
(b) modify the line that reads sentence Word Lab1X09 so that it is an appropriate a prefix of the .wav files you want to segment. In the version of the script on the course website, the string "Lab1X09" would match 10 of my files Lab1X090.wav, Lab1X091.wav, ..., Lab1X099.wav. (The idea here is to use this to limit the subset of files you want to segment in one session -- if you quit Praat and start over again, this script will force you to redo all the files you've already segmented, so you'll want to partition the task into smaller parts.)
(4) In the script window, use File>>Save... to save the script file.
(5) In the script window, use the menu item Run>>Run to execute the script.