[N.B.: these are the on-line lecture notes for both lecture 8 (Phonetics) and lecture 9 (Phonolology).]
Learning about the sound structure of language requires covering a lot of ground. Some of the key topics are the anatomy, physiology, and acoustics of the human vocal tract; the nomenclature for the vocal articulations and sounds used in speech, as represented by the International Phonetic Alphabet; hypotheses about the nature of phonological features and their organization into segments, syllables and words; the way that features like tone align and spread relative to consonants and vowels; the often-extreme changes in sound of morphemes in different contexts; the way that knowledge of language sound structure unfolds as children learn to speak; the variation in sound structure across dialects and across time.
You can't learn all of this in a few days. If we tried to cover all of these topics quickly, the result would be little more than a dry terminological list with brief definitions, accompanied by a few diagrams and an abstract discussion of the associated theories. It would not be especially useful for us to require you to memorize these terms with learning anything much about the underlying realities.
Instead of giving a whirlwind tour of the whole of phonetics and phonology, this portion of Ling001 has two more limited goals.
The first goal is to put language sound structure in context. Why do human languages have a sound structure about which we need to say anything more than "vocal communication is based on noises made with the eating and breathing apparatus"? What are the apparent "design requirements" for this system, and how does are they fulfilled?
The second goal is to give you a concrete sense of
what the language sound systems are like. In order to do this, we will
go over, in a certain amount of detail, a few aspects of the phonetics
and phonology of English, and also a bit about the phonetic and phonology
of Mawukakan, a language spoken in the Ivory Coast and Guinea. Along the way,
a certain amount of the terminology and theory of phonetics and phonology
will emerge.
Apparent design features of human spoken language
We can list a few characteristics of human spoken languages:
-
Large vocabulary: 10,000-100,000 items
-
Open vocabulary: new items are added easily
-
Variation in space and time: different languages and "local accents"
-
Messages are typically structured sequences of vocabulary items
Compare what is known about the "referential" part of the vocal signaling system of other primates:
-
Small vocabulary: ~10 items
-
Closed vocabulary: new "names" or similar items are not added
-
System is fixed across space and time: widely separated populations use the same signals
-
Messages are usually single items, perhaps with repetition
Some general characteristics of other primate vocalizations that are retained by human speech:
-
Vocalizations communicate individual identity
-
Vocalizations communicate attitude and emotional state
Some potential advantages of the human innovations:
-
Easy naming of new people, groups, places, etc.
-
Signs for arbitrarily large inventory of abstract concepts
-
Language learning is a large investment in social identity
Experiments on vocabulary sizes at different ages suggest that children must learn an average of more than 10 items per day, day in and day out, over long periods of time.
A sample calculation:
-
40,000 items learned in 10 years
-
10 x 365 = 3,650
-
40,000 / 3,650 = 10.96
Most of this learning is without explicit instruction, just from hearing the words used in meaningful contexts. Usually, a word is learned after hearing only a handful of examples. Experiments have shown that young children can often learn a word (and retain it for at least a year) from hearing just one casual use.
Let's put aside the question of how to figure out the meaning of a new word, and focus on how to learn its sound.
You only get to hear the word a few times -- maybe only once. You have to cope with many sources of variation in pronunciation: individual, social and geographical, attitudinal and emotional. Any particular performance of a word simultaneously expresses the word, the identity of the speaker, the speaker's attitude and emotional state, the influence of the performance of adjacent words, and the structure of the message containing the word. Yet you have tease these factors apart so as to register the sound of the word in a way that will let you produce it yourself, and understand it as spoken by anyone else, in any style or state of mind or context of use.
In subsequent use, you (and those who listen to you speak) need to distinguish this one word accurately from tens of thousands of others.
(The perceptual error rate for spoken word identification is less than one percent, where words are chosen at random and spoken by arbitrary and previously-unknown speakers. In more normal and natural contexts, performance is better).
Let's call this the pronunciation learning problem. If every word were an arbitrary pattern of sound, this problem would probably be impossible to solve.
What makes it work?
In human spoken languages, the sound of a word is not defined directly (in terms of mouth gestures and noises). Instead, it is mediated by encoding in terms of a phonological system:
-
A word's pronunciation is defined as a structured combination of a small set of elements
-
The available phonological elements and structures are the same for all words (though each word uses only some of them)
-
The phonological system is defined in terms of patterns of mouth gestures and noisesi
-
This "grounding" of the system is called phonetic interpretation
-
Phonetic interpretation is the same for all words
How does the phonological principle help solve the pronunciation learning problem? Basically, by splitting it into two problems, each one easier to solve.
-
Phonological representations are digital, i.e. made up of discrete elements in discrete structural relations.
-
Copying can be exact: members of a speech community can share identical phonological representations
-
Within the performance of a given word on a particular occasion, the (small) amount of information relevant to the identity of the word is clearly defined.
-
Phonetic interpretation is general, i.e. independent of word identity
-
Every performance of every word by every member of the speech community helps teach phonetic interpretation, because it applies to the phonological system as a whole, rather than to any particular word.
A simple example of phonological elements and structures
To illustrate, let's start with the (excessively simple) phonological system of a made-up language.
Outlandish has three vowels -- /a/, /i/, /u/ -- and every Outlandish syllable must contain one of these. There are seven consonants that can start syllables --- /p/, /t/, /k/, /b/, /d/, /g/, /s/ -- and a syllable may also lack an initial consonant. Syllables may optionally end with the consonant /n/.
Outlandish thus has 48 possible syllables: the syllable onset has 8 options (/p/, /t/, /k/, /b/, /d/, /g/, /s/ or nothing), the syllable nucleus has three options (/a/, /i/, /u/), and the syllable coda has two options (/n/ or nothing), and 8 x 3 x 2 = 48.
Outlandish words are made up of from 1 to 4 syllables. In consequence, there are 5,421,360 possible Outlandish words -- 48x48x48x48 + 48x48x48 + 48x48 + 48 = 5,421,360.
Thus the phonological elements of Outlandish, as we have described them, are /i/, /a/, /u/, /p/, /t/, /k/, /b/, /d/, /g/, /s/, /n/. The phonological structures of Outlandish include the notions of syllable, onset, nucleus, and coda.
Some examples of Outlandish words might /kanpiuta/ "electronic calculator", /kaa/ "automobile", /pi/ "climbing annual vine with edible seeds", /bata/ "emulsion of milkfat, water and air".
In giving the phonological encoding of these words, we've omitted the structure, because it is unambiguously recoverable from the string of elements. For instance, /kanpiuta/ must be a four-syllable word whose first syllable contains the onset /k/, the nucleus /a/, and the coda /n/, etc.
Real languages all have more complex phonological systems than our made-up language Outlandish does. However, it remains true that phonological structures are mostly recoverable from strings of phonological elements, and therefore can be omitted for convenience in writing. In this way of writing down phonological representations as strings of letter-like phonological elements, the "letters" are usually called phonemes.
From phonemes to mouth gestures and noises (and back again)
We've exemplified half of the situation: the "Outlandish" example explains what kind of thing a phonological system is, and how the pronunciation of words can be specified by "spelling" them in phonological terms.
What about the phonetic interpretation of words, that is, the interpretation of phonemic strings in terms of mouth gestures and the accompanying noises? How does that work?
You'll find quite a lot of material in Crystal on this topic. In these notes, we'll give only a very basic overview. This topic is covered in more detail in Ling 330 (Introduction to Phonetics and Phonology). Ling 520 (graduate Introduction to Phonetics) is a laboratory courses that goes into considerably more detail, and is open to interested undergraduates with appropriate background.
Basic sound production in the vocal tract: buzz, hiss and pop
There are three basic modes of sound production in the human vocal tract that play a role in speech: the buzz of vibrating vocal cords, the hiss of air pushed past a constriction, and the pop of a closure released.
Laryngeal buzz
The larynx is a rather complex little structure of cartilage, muscle and connective tissue, sitting on top of the trachea. It is what lies behind your "adam's apple." The original role of the larynx is to seal off the airway, in order to prevent aspiration of food or liquid, and also to permit the thorax to be pressurized to provide a more rigid framework for heavy lifting and pushing.
{kind=link}
Part of the airway-sealing system in the larynx is a pair of muscular flaps, the vocal cords or vocal folds, which can be brought together to form a seal, or moved apart to permit free motion of air in and out of the lungs. When any elastic seal is not quite strong enough to resist the pressurized air it restricts, the result is an erratic release of the pressure through the seal, creating a sound. Some homely examples are the Bronx cheer, where the leaky seal is provided by the lips; the belch, where the opening of the esophagus provides the leaky seal; or the rude noises made by grade school boys with their hands under their armpits.
The mechanism of this sound production is very simple and general: the air pressure forces an opening, through which air begins to flow; the flow of air generates a so-called Bernoulli force at right angles to the flow, which combines with the elasticity of the tissue to close the opening again; and then the cycle repeats, as air pressure again forces an opening. In many such sounds, the pattern of opening and closing is irregular, producing a belch-like sound without a clear pitch. However, if the circumstances are right, a regular oscillation can be set up, giving a periodic sound that we perceive as having a pitch. Many animals have developed their larynges so as to be able to produce particularly loud sounds, often with a clear pitch that they are able to vary for expressive purposes.
The hiss of turbulent flow
Another source of sound in the vocal tract -- for humans and for other animals -- is the hiss generated when a volume of air is forced through a passage that is too small to permit it to flow smoothly. The result is turbulence, a complex pattern of swirls and eddies at a wide range of spatial and temporal scales. We hear this turbulent flow as some sort of hiss.
In the vocal tract, turbulent flow can be created at many points of constrictions. For instance, the lower teeth can be pressed against the upper lip -- if air is forced past this constriction, it makes the sound associated with the letter (and IPA symbol) [f].
When this kind of turbulent flow is used in speech, phoneticians call it frication, and sounds that involve frication are called fricatives.
The pop of closure and release
When a constriction somewhere in the vocal tract is complete, so that air can't get past it as the speaker continues to breath out, pressure is built up behind the constriction. If the constriction is abruptly released, the sudden release of pressure creates a sort of a pop. When this kind of closure and release is used as a speech sound, phoneticians call it a stop (focusing on the closure) or a plosive (focusing on the release).
As with frication, a plosive constriction can be made anywhere along the vocal tract, from the lips to the larynx. However, it is difficult to make a firm enough seal in the pharyngeal region to make a stop, although a narrow fricative constriction in the pharynx is possible.
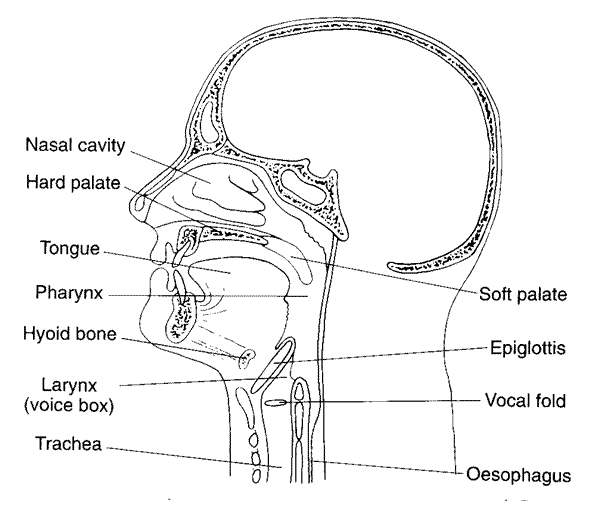
Sound shaping by the vocal tract: vowel color and nasality
Between the larynx and the world at large is about 15 centimeters of throat and mouth. This passageway acts as an acoustic resonator, enhancing some frequencies and attenuating others. The properties of this resonator depend on the position of the tongue and lips, and also on whether the velum is lowered so as to open a side passage to the nasal cavities. Some examples of shapes in a computer model of the human vocal tract, the corresponding resonance patterns, and the sounds that result when a laryngeal buzz in shaped by these resonances, can be found here.
Different positions of the tongue and lips make the difference between one vowel sound and another. As you can easily determine for yourself by experiment, you can combine any vowel sound with any pitch -- or with a whisper, which is a hiss created by turbulent flow at the vocal folds.
You can see (some aspects of) the coordination of the articulators in this old x-ray movie:
And here's a video showing something invisible in the x-ray, namely (some of) what happens in your larynx as you talk:
Here's a high-speed video that gives a better sense of how the vocal folds generate air-pressure variation at the time scale of voice pitch (about 60 to 600 oscillations per second):
And, if you're interested, here's a bit more about the anatomy:
Phonetic syllables: the scale and cycle of sonority
Human speech, like many animal vocalizations, tends to involve repetitive cycles of opening and closing the vocal tract. In human speech, we call these cycles syllables. A syllable typically begins with the vocal tract in a relatively closed position -- the syllable onset -- and procedes through a relatively open nucleus. The degree of vocal tract openness correlates with the loudness of the sound that can be made. Speech sounds differ on a scale of sonority, with vowels at one end (the most sonorous end!) and stop consonants at the other end. In between are fricatives, nasal consonants like [m] and [n], and so on. Languages tend to arrange their syllables so that the least sonorous sounds are restricted to the margins of the syllable -- the onset in the simplest case -- and the most sonorous sounds occur in the center of the syllable.
However, there are some cases where the same -- or at least very similar -- sounds can occur in several different syllabic roles. For example, the glides (sometimes called approximants) that begin syllables like "you" and "we" are almost exactly like vowels, except for their syllabic position. In fact, the mouth position and acoustic content of the "consonant" at the start of "you" and of the "vowel" at the end of "we" are just about exactly the same.
In the International Phonetic Alphabet (IPA), the English word "you" (in standard pronunciations) would be written something like [ju], where the [j] refers to the sound we usually write as "y", and the [u] refers to the vowel as in "boo" or "pool". The English word "we" would be written in the IPA as [wi], where the [w] is familiar, and the [i] refers to the vowel found in "see" or "eat".
In fact, the articulation and sound of IPA [j] is quite a lot like the articulation and sound of IPA [i], while the articulation and sound of IPA [w] is quite like that of IPA [u]. What is different is the role in the syllabic cycle -- [j] and [w] are consonants, while [i] and [u] are vowels.
This means that the English words "you" and "we" are something like a phonetic palindrome -- though "you" played backwards sounds more like "oowee" than "we". More important, this underlines that point that phonetics is the study of speech sounds, not just the study of vocal noises.
The International Phonetic Alphabet
In the mid-19th century, Melville Bell invented a writing system that he called "Visible Speech." Bell was a teacher of the deaf, and he intended his writing system to be a teaching and learning tool for helping deaf students learn spoken language. However, Visible Speech was more than a pedagogical tool for deaf education -- it was the first system for notating the sounds of speech independent of the choice of particular language or dialect. This was an extremely important step -- without this step, it is nearly impossible to study the sound systems of human languages in any sort of general way.
In the 1860's, Melville Bell's three sons -- Melville, Edward and Alexander -- went on a lecture tour of Scotland, demonstrating the Visible Speech system to appreciative audiences. In their show, one of the brothers would leave the auditorium, while the others brought volunteers from the audience to perform interesting bits of speech -- words or phrases in a foreign language, or in some non-standard dialect of English. These performances would be notated in Visible Speech on a blackboard on stage.
When the absent brother returned, he would imitate the sounds produced by the volunteers from the audience, solely by reading the Visible Speech notations on the blackboard. In those days before the phonograph, radio or television, this was interesting enough that the Scots were apparently happy to pay money to see it!
[There are some interesting
connections between the "visible speech" alphabet and the later career
of one of the three performers, Alexander
Graham Bell, who began following in his father's footsteps as a teacher
of the dear, but then went on to invent the telephone. For example, look
at the discussion of Bell's "Ear
Phonautograph" and artificial vocal tract.]
Phonetic notation for elocution lessons -- and for linguistic description
After Melville Bell's invention, notations like Visible Speech were widely used in teaching students (from the provinces or from foreign countries) how to speak with a standard accent. This was one of the key goals of early phoneticians like Henry Sweet (said to have been the model for Henry Higgins, who teaches Eliza Doolittle to speak "properly" in Shaw's Pygmalion and its musical adaptation My Fair Lady).
The International Phonetic
Association (IPA) was founded in 1886 in Paris, and has been ever
since the official keeper of the Inernational Phonetic Alphabet (also
IPA), the modern equivalent of Bell's Visible Speech. Although the IPA's
emphasis has shifted in a more descriptive direction, there remains a
lively tradition in Great Britain of teaching standard pronunciation using explicit training in the IPA.
The IPA and the dimensions of speech production
If you look at the IPA's table of "pulmonic" consonants (roughly, those
made while exhaling normally), you will see that it is organized along two
main dimensions.
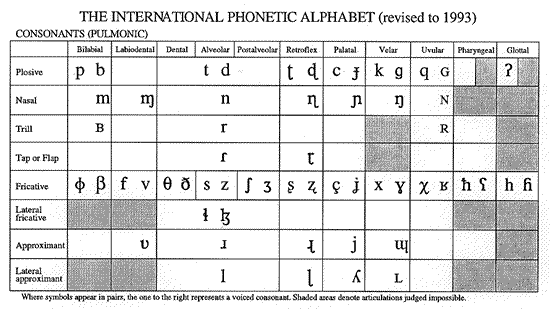
The columns are labelled by positions of constriction, moving from the lips (bilabial) past the teeth (dental) and the hard palate (palatal) and soft palate (velar) to the larynx (glottal). The rows are labelled by the type of manner of constriction: plosive, nasal, fricative, and so forth. The side-by-side pairs of plosives and fricatives are differentiated by whether layrngeal buzz is present during the constriction. You can feel the difference yourself if you put your finger on your adam's apple while saying an extended [s] or [z].
Thus the dimensions along which the IPA is organized are basically the physical and functional dimensions of the human vocal tract, as shown in the diagram earlier on this page. The same was true of Bell's Visible Speech.
The Sound Structure of Mawukakan
An essential part of learning about the sound structure of language is to look at a particular case in detail. We don't have time to teach the appropriate level of detail in this course. However, those of you who are interested in such things can learn a lot on your own, and of course you can go on to take other courses at Penn that take up language sound in detail.
For this course, we will go over in class a book chapter on some aspects of the sound structure of an African language, Mawukakan, available on line via this link.. You will not be responsible for the details of this material -- if any of it is used in any exam question, all needed facts will be presented in the question.
The information in this section was developed a few years ago in the course Ling 505/202 (Introduction to Field Linguistics), with the help of Dr. Moussa Bamba, an accomplished linguist who happens to be a native speaker of Mawu.
 Mawukakan is
more commonly known as "Mawu" (or "Mau", or "Mahou",
among other spellings). For its speakers, the region where they live is
called mawu, the people who live there are the mawuka (adding
a suffix /-ka/ that turns a name for a place into a name for the people
who live there), and the way they speak is called mawukakan (adding
another suffix /-kan/ that turns the name for a people into a name for
the language they speak). Since Mawukakan is not normally written down,
the different ways of spelling the name arise from different transliterations
into other languages, or different ideas about writing systems for Mawukakan
itself: the Ethnologue
entry gives six versions.
Mawukakan is
more commonly known as "Mawu" (or "Mau", or "Mahou",
among other spellings). For its speakers, the region where they live is
called mawu, the people who live there are the mawuka (adding
a suffix /-ka/ that turns a name for a place into a name for the people
who live there), and the way they speak is called mawukakan (adding
another suffix /-kan/ that turns the name for a people into a name for
the language they speak). Since Mawukakan is not normally written down,
the different ways of spelling the name arise from different transliterations
into other languages, or different ideas about writing systems for Mawukakan
itself: the Ethnologue
entry gives six versions.
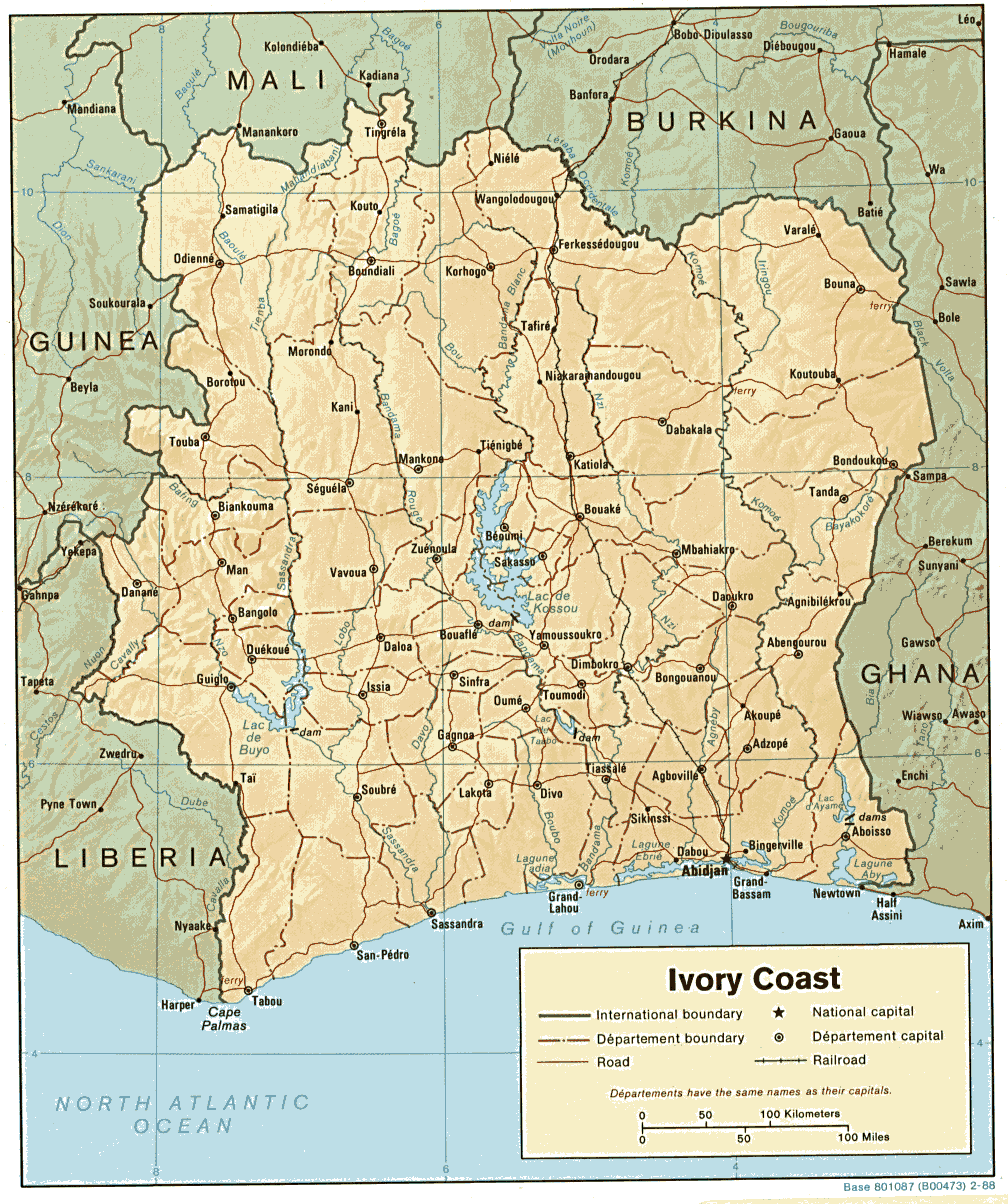
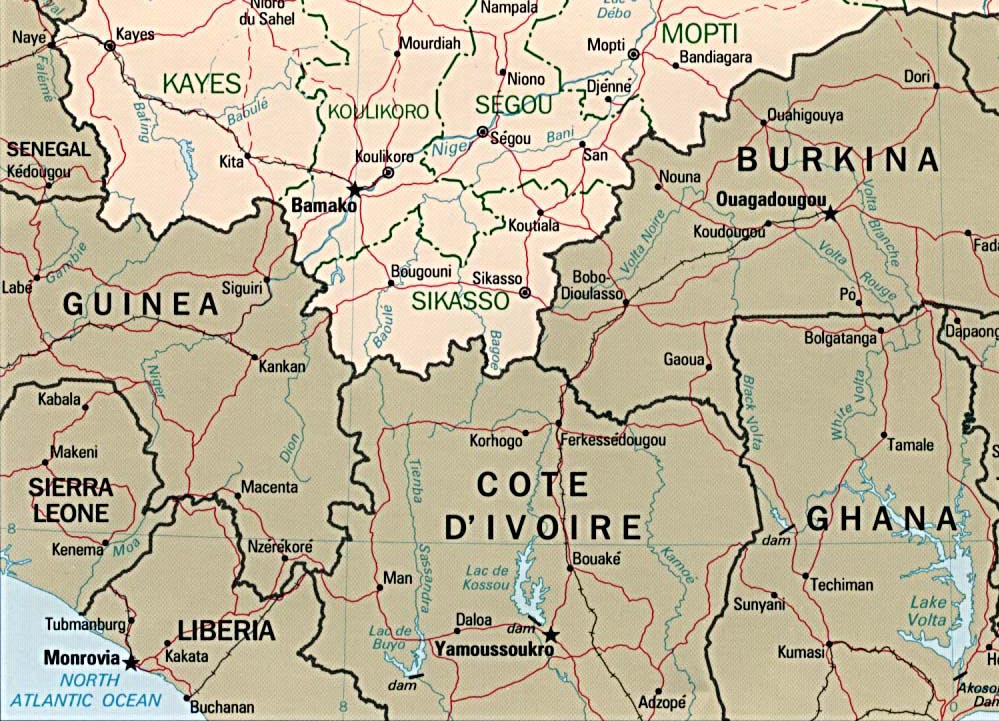
The Mawukakan region is near the city of Touba, in the northwestern region of the Ivory Coast, near the border with Guinea. The traditions of the Mawuka people say that they migrated from the city of Djenne, southwest of Mopti, in what in now Mali.. The Manding people, of which the Mawuka are a branch, are known among other things for the music and poetry of their bards, known as griots, and for their spectacular traditional architecture (here is a picture of the Djenne mosque)
{kind=link}
{kind=link}
{kind=link}