Language Production and Perception
It is worth noting that several aspects of this picture are controversial. Some philosophers doubt that meanings are things that can be put into one-to-one correspondence with phrases of ordinary language, or can ever be said to be fully shared between two people, or even are well-defined things at all. Some social scientists observe that most linguistic communication is a cooperative process that is not well modeled by making the speaker entirely the active creator of a message, and the listener entirely its passive recipient.
Nevertheless, there are many circumstances where this perspective gives a useful common-sense framework, and it lies behind most research on speaking and understanding speech. Although we are all able to speak and to understand, we have no conscious access to the many complex neurophysiological processes that underlie these abilities, and so an experimental approach is necessary.
Linguists and psycholinguists have looked at many aspects of the production and perception of spoken language, too many to do more than list in a single lecture. Rather than give an abstracted list of issues and techniques, we'll look in a bit of detail at two kinds of studies -- those that use speech errors to learn about language production, and those that look at the time course of spoken word recognition. Keep in mind that these are two small parts of a very large and interesting picture, about which you can learn much more by taking a course in psychology of language.
A window on language generation: slips of the tongue and pen.
In figuring out how the brain works, one standard line of inquiry is to look at how it fails. This approach was first taken to the problem of speech generation by Sigmund Freud, in his 1901 work The Psychopathology of Everyday Life.Freud focused on the substitution of words either in speech (lapsus linguae, slips of the tongue) or in writing (lapsus calami, slips of the pen). The substitution is contrary to the conscious wishes of the person speaking or writing, and in fact sometimes is subversive of these wishes. The speaker or writer may be unaware of the error, and may be embarrassed when the error is pointed out. Freud believed that such "slips" come from repressed, unconscious desires.
Freud's general term for such errors was "faulty action (Fehleistung)," which has been translated as the pseudo-Greek scientism parapraxis. The colloquial label is "Freudian slip."
In Freud's analysis, a slip of the tongue is a form of self-betrayal.
Here are a few of the examples he cited.
-
The President of the Austrian Parliament
said " I take notice that a full quorum of members is present and herewith
declare the sitting closed!"
The hotel boy who, knocking at the bishop's door, nervously replied to the question "Who is it?" "The Lord, my boy!"
A member of the House of Commons referred to another as the honourable member for "Central Hell," instead of "Hull."
Another professor says, "In the case of the female genital, in spite of the tempting ... I mean, the attempted ..... "
When a lady, appearing to compliment another, says "I am sure you must have thrown this delightful hat together" instead of "sewn it together", no scientific theories in the world can prevent us from seeing in her slip the thought that the hat is an amateur production. Or when a lady who is well known for her determined character says: "My husband asked his doctor what sort of diet ought to be provided for him. But the doctor said he needed no special diet, he could eat and drink whatever I choose," the slip appears clearly as the unmistakable expression of a consistent scheme."
Slips of the tongue often give this impression of abbreviation; for instance, when a professor of anatomy at the end of his lecture on the nasal cavities asks whether his class has thoroughly understood it and, after a general reply in the affirmative, goes on to say: "I can hardly believe that this is so, since persons who can thoroughly understand the nasal cavities can be counted, even in a city of millions, on one finger ... I mean, on the fingers of one hand." The abbreviated sentence has its own meaning: it says that there is only one person who understands the subject.

-
The cartoon has a few other linguistic aspects. It would be irresponsible
for us not to point out that the pilgrim's use of archaic verb forms
is entirely bogus. The /-st/ ending in didst is the archaic second
person singular past, whereas the context calls for third person singular
past; and goeth is archaically inflected for third person singular
present, rather than being the bare verb stem as required by the where
did X go? construction.
There has been quite a bit of research on slips of the tongue since 1901, and (to the extent that Freud's theory is susceptible of empirical test) this research tends to undermine Freud's conception, and to substitute another one. The characteristics of slips are the result of the information-processing requirements of producing language. If this theory is correct, then slips tell us much less than Freud thought about unconscious intentions, and much more about language structure and use.
Linguistic theory tells us that there is a hierarchy of units below the level of the sentence: phrase, word, morpheme, syllable, syllable-part (such as onset or rhyme), phoneme, phonological feature. Slips can occur at each of these levels. In addition, slips can be of several types: substitution (of one element for another of the same type), exchange (of two elements of the same type within an utterance), shift (of an element from one place to another within the utterance), perseveration (re-use of an element a second time, after the 'correct' use), anticipation (re-use of an element, before the 'correct' use).
In a review article entitled Speaking and Misspeaking
(published in Gleitman and Liberman, Eds., An Invitation to Cognitive
Science), Gary Dell gives the following made-up examples, all related
to the target utterance "I wanted to read the letter to my grandmother."
- phrase (exchange): "I wanted to read my grandmother to the letter."
- word (substitution): "I wanted to read the envelope to my grandmother."
- inflectional morpheme (shift): "I want to readed the letter to my grandmother."
- stem morpheme (exchange): "I readed to want the letter to my grandmother."
- syllable onset (anticipation): "I wanted to read the gretter to my grandmother."
- phonological feature (anticipation or perseveration): "I wanted to read the letter to my brandmother."
Language is a complex and hierarchical system. Language use is creative, so that new utterance is put together on the spot out of the piece-parts made available by the language being spoken. A speaker is under time pressure, typically choosing about three words per second out of a vocabulary of 40,000 or more, while at the same time producing perhaps five syllables and a dozen phonemes per second, using more than 100 finely-coordinated muscles, none of whom has a maximum gestural repetition rate or more than about three cycles per second. Word choices are being made, and sentences constructed, at the same time that earlier parts of the same phrase are being spoken.
Given the complexities of speaking, it's not surprising that about one slip of the tongue on average occurs per thousand words said. In fact, perhaps it is surprising that more of us are not like Mrs. Malaprop or Dr. Spooner.
Mrs. Malaprop was a character Richard Brinsley Sheridan's play "The Rivals" (1775), who used words "mal a propos", French for "out of place". Some of her usages were "She's as headstrong as an allegory on the banks of the Nile;" "Comparisons are odorous;" "...you will promise to forget this fellow -- to illiterate him, I say, quite from your memory;" "He is the very pineapple of politeness."
Some of Yogi Berra's witticisms owe something to Mrs. Malaprop: "I just want to thank everyone who made this day necessary." "Even Napoleon had his Watergate."
Spooner was an real historical figure -- the Reverend William
A. Spooner, Dean and Warden of New College, Oxford, during Victoria's
reign -- whose alleged propensity for exchange errors gave the name of
spoonerism to this class of speech error. The term came into general
use within his lifetime. Some of the exchanges attributed (apocryphally)
to him are:
-
Work is the curse of the drinking classes.
...noble tons of soil... (noble sons of toil)
You have tasted the whole worm. (wasted the whole term)
I have in my bosom a half-warmed fish. (half-formed wish)
...queer old dean... (dear old queen, referring to Queen Victoria).
Linguists have accumulated large collections of speech errors,
and used the statistical distribution of such errors to evaluate models
of linguistic structure and the process of speaking. For instance, the
distribution of unit sizes in a corpus of exchanges, reproduced below,
has been argued to tell us that words, morphemes and phonemes are especially
important units in the process of speaking:

Many other details of the distribution of speech errors are also revealing. For example, word-level slips of all kinds obey the syntactic category rule: the target (i.e. the word replaced) and the substituting word are almost always of the same syntactic category. Nouns replace nouns, verbs replace verbs, and so on.
The syntactic category rule is by far the strongest influence on word-level errors. There are other influences -- for instances, the substituting word tends to be related in meaning and in sound to the target -- but these are generally less strong.
When the substituting word comes completely from outside the utterance -- rather than being an exchange of words or an anticipation or perseveration of words within the utterance -- this is called a "non-contextual word substitution." In such cases, it is common for the substitute and the target to be semantically and pragmatically similar. For instance, U.S. President Gerald Ford once toasted Egyptian President Anwar Sadat "and the great people of Israel -- Egypt, excuse me." However, even in such non-contextual word substitutions, there are other influences besides semantic similarity, such as association with nearby words, or similarity in pronunciation. For example, in one of the speech-error corpora, a speaker refers to "Lizst's second Hungarian restaurant" instead of "Lizst's second Hungarian rhapsody." Restaurant and rhapsody are not particularly similar in meaning, but both are associated with Hungarian -- and both are three-syllable words with initial stress that start with /r/.
In this case, as in nearly all such cases, the syntactic category rule is obeyed -- restaurant and rhapsody are both nouns.
There is a large scientific literature in which linguists
and psycholinguists examine numerous detailed properties of speech error
corpora. One general observation that emerges is that Freud's cited examples
are atypical. There are very few naturally-occurring speech errors in
which one can see any evidence of repressed fears or desires, either in
motivating the use of the incorrect utterance or the avoidance of the
correct one. Some observed errors are:
- The shirts fall off his buttons (buttons fall off his shirts)
- The ricious vat (vicious rat)
- A curl galled her up (girl called)
- ...sissle theeds... (thistle seeds)
- My jears are gammed (gears are jammed)
- ...by the sery vame... (very same)
- This is the most lescent risting (recent listing)
- Did the grass clack? (glass crack)
- I have a stick neff (stiff neck)
- is noth wort knowing (not worth)
In fact, Motley (1980) was able to create "Freudian slip" effects of this kind in the experimental induction of speech errors. He used one of the standard techniques for inducing phonemic exchange errors, which works as follows. The subject is asked to read a list of word pairs such as "dart board." Some of these are target pairs, in which the experimental hopes to induce an error, and some are bias pairs. A "bias pair" has something in common (say initial phonemes) with the desired error. Three bias pairs precede every target pair. A sample of sequence of this kind is
dart board
(bias pair)
dust bin
(bias pair)
duck bill
(bias pair)
barn door
(target pair: --> darn bore?)
Under these conditions, subjects produce about 10-15% spoonerisms on the target items. The experimenter can then systematically examine the factors that make errors more or less likely. For instance, errors are generally more likely when the results are real words (barn door --> darn bore) than when the results are not (born dancer --> dorn bancer), or when the rest of the target words are phonologically similar (e.g. left hemisphere --> heft lemisphere, where the same vowel follows, vs. right hemisphere --> hight remisphere, where different vowels follow).
In Motley's 1980 experiment, he used manipulation of the experimental context as the independent variable. The subjects were male undergraduates, and the context was either electrical or sexual. In the "electrical" context, the subjects were attached to (fake) electrodes and told that mild shocks would be administered if they performed badly. In the "sexual" context, the test was administered by a provocatively-dressed and conventionally attractive female experimenter (it's not clear if subjects' sexual preference was controlled).
Motley then looked at the likelihood of errors whose output has electrical associations (as in the case of the word pair shad bock), as opposed to sexual ones (as in the word pair tool kits). He found that errors tended to correspond to the contextual conditions: in the electrical context, electrical errors were more common, while in the sexual condition, sexual errors were more common.
Motley's results show that genuinely Freudian slips -- errors that reveal unexpressed thoughts -- do happen. At least, slips of the tongue can be primed or biased in the direction of topics or concepts that are on the speaker's mind. However, the same experiment shows that it is easy to cause slips of the tongue for purely phonological reasons, without any semantic or even lexical priming. We can conclude that many speech errors -- perhaps most speech errors -- do not real the speaker's secret fears and desires, but rather the innocent (if still hidden) properties of his or her language production system.
Speech non-errors: l'art du contrepet
The French, subtle as always, have for several centuries practiced a form of linguistic joke called the contrepet, which is a sort of Freudian slip waiting to happen. The joke occurs in the form of a phrase, itself innocuous and plausible, which if it were to be subjected to a particular exchange (of phonemes, syllables or words), would become obscene and scurrilous. For example,-
Le pape ne veut pas qu'on tue.
A few examples are more disrespectful rather than obscene, such as this one:
-
Il y a deux espèces de gendarmes,
les courts et les longs.
The word contrepet means "counter-flatulence", the idea apparently being that the hidden "counter" phrase emerges like passing gas. The prestigious series Le Livre de Poche has published a volume on this topic by one Luc Etienne, entitled L'Art du Contrepet.
Although contrepèterie is mainly practiced by French adults rather than children, it shares with the language games discussed in an earlier lecture the property of depending on sound rather than on spelling. In addition, it depends on the author and the audience sharing an understanding of what speech errors are like.
Many famous French writers -- Rabelais, de Vigny, Hugo,
Jarry -- have devoted themselves to this form. As far as I know,
this particular kind of word-play has never caught on in English-speaking
countries, though perhaps the target word pairs in Motley's "sexual" condition
might be considered as somewhat lame anglo-saxon contrepèterie.
There is a kind of joke, popular among high-school students,
in the riddling form "what is the difference between X and Y?" where the
answer is a pair of phrases involving a speech-error-like exchange, one
half of which is typically obscene.
Speech perception
Towards the beginning of the course, we talked about how well human speech perception works. Even without conversational context, arbitrary isolated spoken words are perceived as the speaker intended about 98 times out of a hundred. In context, with decent sound quality, perceptual errors in transcription are even rarer.Speech perception is not only very accurate, it is also very rapid. A spoken word unfolds in time over the course of perhaps half a second. Some clever experimental techniques have demonstrated that human speech perception normally keeps up with the flow of speech -- we recognize words as they are spoken, and often before they have been completely pronounced.
Speech perception can be studied on many levels, but in this lecture, we'll limit ourselves to a brief account of some of the work on the time course of spoken word recognition, and some of the factors that influence it.
Towards the beginning of a word's utterance, the acoustic evidence is consistent with many possible continuations. For instance, when we've heard the initial consonant cluster and the start of the vowel in the word bride, what we've heard is consistent with other words such as brine, bribe, and biar.
We can define the uniqueness point as the point at which the word becomes uniquely identifiable - i.e. no other words in the mental lexicon continue from that beginning.
t: tea, tree, trick, tread, trestle, trespass, top, tick, etc.
tr: tree, trick, tread, tressle, trespass, etc.
tre: tread, trestle, trespass, etc.
tres: trestle, trespass, etc.
tresp: trespass (uniqueness point has been reached,
at least as far as the stem morpheme is concerned)
A simple approach to charting the time course of word recognition
is just to ask subjects to listen for a particular word in running speech,
and to press a key when they hear it. Typical time values for this kind
of task, for one- and two-syllable content words in normal utterance contexts,
are about 250-275 milliseconds after the onset of the word. If we allow
50-75 milliseconds for the generation of the response, then an internal
decision time of about 200 milliseconds (or one fifth of a second) from
the word onset is estimated. Since such words are typically about 400 milliseconds
long, this implies that the internal decision is generally taking place
when only about half the word has been heard. Does this mean that the internal decision is taking place at the uniqueness point? Actually, it seems that (in normal utterance contexts) words are usually recognized even before their uniqueness point! Of course, in doing so, the listener is taking a chance on being wrong -- presumably the gamble is motivated by the predictive value of the context.
There are several ways to estimate the uniqueness point
of a word. One is to look in the dictionary to see what other words have
pronunciations that start the same way. Another, more direct method is
the gating paradigm.
This technique simply involves cutting the sound of the word
off before it is finished, playing the incomplete word to listeners, and
tabulating their guesses about what the word is.
The plots below show subjects' response to gated versions of two words that start the same way -- shark and sharp. These monosyllables are about 600 milliseconds long, because they were spoken carefully in isolation. As the plots show, reliable identification (16 out of 16 responses correct) is not achieved until near the end of the word's pronunciation, after the release of the final consonant has been heard.
At earlier points, the commoner word ("sharp") is guessed more often for both cases. As more and more of the word shark is heard, "sharp" responses decrease and "shark" responses take over. When the word is actually sharp all along, "sharp" responses start out ahead, and gradually drive out the few "shark" responses.
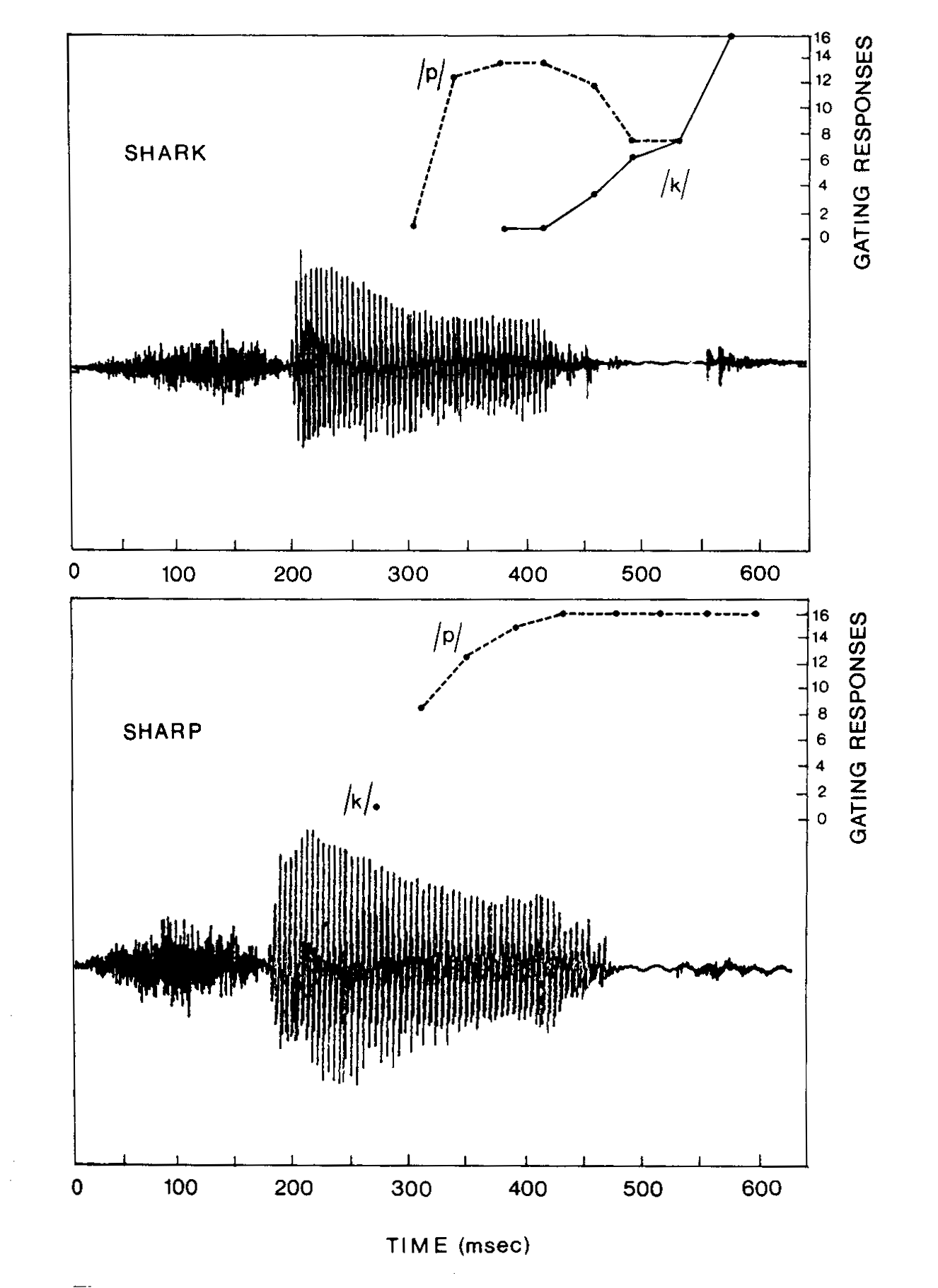
These results show us that by half-way through the time couse of the word (much less after only 200 msec.), there is by no means adequate acoustic information to distinguish these words. In an experiment looking at words in running speech, the average word recognition point was estimated to be less than 200 msec. after word onset, as usual, while a set of gating experiments showed that the average acoustic decision point for the same set of spoken words was more than 300 msec. after word onset. This is known as the "early selection" effect.
The graphs above show us something else -- subjects are "betting the odds" by choosing the more frequent word, in the absence of other evidence. This same pattern applies for words recognized in normal utterance context -- the context will bias the choice one way or the other, usually very strongly, even without acoustic evidence.
Here are a few sentence beginnings, chosen at random from
the 1995 New York Times wire service, some continuing with "sharp" while
others continue with "shark". Can you tell them apart?
-
She once went deep-sea fishing , caught
a 275-pound ___ . . .
The Kerrey-Danforth recommendations drew ___ . . .
Moon (29 of 52 for 292 yards, 2 touchdowns and 2 interceptions) wasn't ___ . . .
After writing about monsters like the cat-like dinofelis and Peter Benchley 's white ___ . . .
Dallas looked ___ . . .
Encountering a ___ . . .
I 've swam with billfish and every type of ___ . . .
A good high-speed jointer with ___ . . .
In the 52.8 million words of the 1995 New York Times newswire, "sharp" occurs 1422 times while shark only occurs 101 times. Thus in the absence of any evidence, either from sound or from context, the smart bet (roughly 14 to 1 odds) is "sharp" -- as indeed is shown by the responses of the subjects in the graphs above. Once enough acoustic evidence has come in that the 'cohort' of plausible words can be narrowed down roughly to "shark" or "sharp" (perhaps along with "shard" -- 14 occurrences in the 1995 NYT -- and a few other very uncommon possibilities), the subjects are giving roughly 14 times as many "sharp" responses as "shark" responses, even when the word will really turn out to be "shark". People are exquisitely sensitive to this sort of frequentistic information about about their language -- not many people can make mathematically correct bets in poker or other card games, but every normal person can (unconsciously) "play the odds" to a couple of decimal places in understanding speech.
A natural hypothesis is that this educated gambling is what is responsible for early selection. Many experiments have supported this hypothesis. For instance, listeners respond to a word more slowly when it occurs in an implausible context ("John buried the guitar"), and even more slowly when it occurs in a semantically anomalous context "John drank the guitar").
The increases in response latency caused by semantic anomaly are generally rather small -- perhaps 50 msec. Overall there is a strong asymmetry in the role of "bottom-up" (acoustic) evidence and "top-down" (contextual) evidence. Good acoustic evidence will override even the strongest contextual preferences -- if someone says "John drank the guitar", then listeners will think the phrase is weird, but they will hear it nevertheless.
Responses slow down even further if the input is not even syntactically plausible -- "The drank John guitar", or worse. Experimenters sometimes call such quasi-random sequences word salad, because it is like the results of mixing up a bunch of words in a salad bowl. In word salad, the listener has nothing to rely on except the acoustic evidence and the effects of raw word frequency independent of context. Still, spoken word recognition under such conditions remains accurate and close in time to the uniqueness point.
All in all, the human speech perception system is amazingly
well adapted to make quick decisions based on an optimal combination of
all available information. This system is operating at an idle when listening
to clearly-pronounced speech under reasonable acoustic conditions -- conditions
in which computer speech recognition systems still make more mistakes
than we would like. When the speech is slurred and erratic, when there
is background noise or music or other people speaking at the same time,
the system really shows its power. Under these conditions, where human
listeners may still make out most of what is said without too much trouble,
the performance of the best current computer systems degrades very rapidly.
This remains an area of active research, where we know a lot about how
well human perception works, but not very much about how it happens.