Basic Linear Algebra Review
Linear Algebra has become as basic and as applicable as calculus, and fortunately it is easier.
--Gilbert Strang
Today, most scientific mathematics is applied linear algebra, in whole or in part. This is true of most inferential and exploratory statistics, most data mining, most model building and testing, most analysis and synthesis of sounds and images, and so on. This is just as true for research on speech, language and communication as it is for every other area of science.
Therefore we begin this course with a brief review of linear algebra, and will return to the topic repeatedly. This introduction will also show you how to express each concept in Matlab. The Matlab examples will be in red. Note that the double "greater-than" >> is the Matlab prompt.
This review will be limited to the case of real numbers. However, in general (and in Matlab) scalars, vectors and matrices can be made out of complex numbers -- and at a couple of points in the course, this will become important.
Vectors, matrices and basic operations on them
A scalar is any real (later complex) number. The name "scalar" derives from its role in scaling vectors. Operations defined on scalars include addition, multiplication, exponentiation, etc.
>> 3+4
ans =
7
>> 3*4
ans =
12
>> 3^4
ans =
81
A vector is an n-tuple (an ordered set) of numbers, e.g. a member of R^n (where R stands for the real numbers). Thus two-dimensional vectors are elements of the set {R × R}, e.g. [1 2] or [-43.2565 -114.6471] or [2.8768e+11 0].
Geometrically, a vector of dimensionality n can be interpreted as point in an n-dimensional space, or as a directed magnitude (running from the origin to that point). The dimensionality n (that is, the number of elements in n) can be anything: 1 or 37 or 10 million or whatever.
Note 1: the origin is the vector consisting of all zeros -- in whatever dimensionality.
Note 2: ordinary language words such as length or size can be ambiguous when applied to a vector: we might mean the dimensionality of the vector, i.e. the number of elements in it (so that a vector [3 4] has length 2 in this sense), or we might mean the geometric distance from the origin to the point denoted by the vector (so that a vector [3 4] has length 5 in this sense). We'll try to avoid uses whose meaning is not clear from context. When we want to be absolutely clear, we'll use terms like dimensionality to mean "length in the sense of number of elements", and terms like magnitude or geometric length to mean "length in the sense of euclidean distance from the origin".
You can enter a vector in Matlab by surrounding a sequence of numbers with open and close square brackets:
>> a = [1 2 3 4]
a =
1 2 3 4
The individual numbers that make up a vector are called elements or components of the vector.
Operations on vectors include scalar multiplication (also of course scalar addition, subtraction, division)
>> a=[4 3 2]
a =
4 3 2
>> 3*a
ans =
12 9 6
and vector addition. Two vectors of the same size (i.e. number of elements) can be added: this adds the corresponding elements to create a new vector of the same size. You can't add two vectors of different sizes.
>> [1 2 3 4] + [9 8 7 6]
ans =
10 10 10 10
>> [1 2 3 4] + [9 8 7]
??? Error using ==> +
Matrix dimensions must agree.
Scalar multiplication has a simple geometric interpretation. A vector -- viewed as a point in space -- defines a line drawn through the origin and that point. Multiplying the vector's elements by a scalar moves the point along that line. For any (non-zero) vector, any point on the line can be reached by some scalar multiplication. We can visualize this easily in 2-space (where points are defined by pairs of numbers), and also in 3-space (where points are defined by triples of numbers). Vectors of higher dimensionality can't really be visualized, but the 2-D or 3-D intuitions are often useful in thinking about higher-dimensional cases as well. In particular, this graphical way of thinking about scalar multiplication of a vector remains true for vectors of any dimensionality.
If you visualize a vector as a directed magnitude, running from the origin to the specified point in n-space, then you can think of adding vectors as the geometric equivalent of placing the vectors "tail to head". In the picture below, a is added graphically to b to make c.
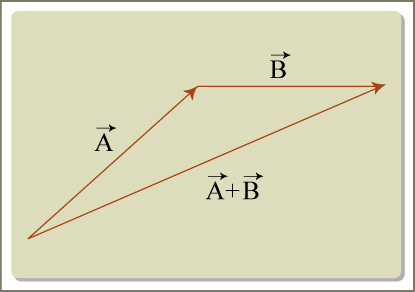
The magnitude (length) of a vector is a scalar, equal to the square root of the sum of the squares of its elements. This is a special case of the fact that the Euclidean distance between two points in n-space is the square root of the sum of the squares of the element-wise differences.
If we symbolize the magnitude of a vector a as |a|, then a/|a| will always be a vector of unit length.
Another important operation on vectors is the inner product (or dot product) of two vectors. This is the sum of the pair-wise products of corresponding elements.
Thus the inner product of [1 3 2 6] and [5 4 7 8] is 1*5 + 3*4 + 2*7 + 6*8, or 79. As in this example, the inner product of two vectors, of any number of elements, is always a scalar. Obviously if two vectors do not have the same number of elements, their inner product is undefined.
In order to understand how Matlab expresses an inner product of vectors, we need to consider matrices first.
A matrix is an m by n array of real numbers (later complex numbers), e.g. a member of the set R^(m x n), where m and n are any non-zero positive integers. We can write the matrix as a table with m rows and n columns. We can index an element of a matrix with two positive integers -- the row index and the column index. Thus element i,j is at the intersection of row i and column j. It's conventional to number rows and columns starting from 1.
In defining a matrix for Matlab, we can separate rows with a newline or with a semicolon. Matlab prints out matrices as nicely-formatted tables.
>> [1 2 3 4
5 6 7 8]
ans =
1 2 3 4
5 6 7 8
>> [1 2 3 4; 5 6 7 8]
ans =
1 2 3 4
5 6 7 8
Matlab can index elements of vectors or matrices as follows:
>> a = [ 3 1 6 4]
a =
3 1 6 4
>> a(2)
ans =
1
>> A = [3 1 6 4; 7 8 10 9]
A =
3 1 6 4
7 8 10 9
>> A(1,2)
ans =
1
Matlab (and most treatments of linear algebra) consider vectors to be particular types of matrices, namely those with only one column (an n by 1 matrix) or only one row (a 1 by n matrix). A vector viewed as a matrix with only one column is (not surprisingly) a column vector. A vector viewed as matrix with only one row is a row vector. In linear algebra, by convention, the column vector is viewed as the basic case. However, in Matlab, if you type in a vector in a form like [4 3 2 1], it is entered as a row vector (because you might have been entering the first row of a matrix).
The normal linear algebra convention is that vectors are symbolized with lower-case constants/variables (a, b, c, ... x, y, z) while matrices are symbolized with upper-case (A, B, C, ...). Matlab doesn't care, however.
We'll consider four basic operations on matrices -- transposition, scalar multiplication, matrix addition, and matrix multiplication -- before returning to the question of how to express the inner product in Matlab.
Transposition is the interchange of rows and columns in a matrix. The usual linear algebra notation is a superscript capital T -- thus A with a superscript capital T means "A transpose". For easier typing, Matlab using the single quote -- thus in Matlab, A' is "A transpose". Element i,j in A' is element j,i in A.
>> A
A =
3 1 6 4
7 8 10 9
>> A'
ans =
3 7
1 8
6 10
4 9
Transposition obviously changes a column vector into a row vector -- and vice versa:
>> a=[1;2;3;4]
a =
1
2
3
4
>> a'
ans =
1 2 3 4
Matrix addition is like vector addition: element-wise addition of corresponding elements in two matrices with the same dimensions. Addition is undefined if the two matrices do not have the same dimensions.
>> A=[1 2 3 4; 5 6 7 8]
A =
1 2 3 4
5 6 7 8
>> B=[11 12 13 14; 15 16 17 18]
B =
11 12 13 14
15 16 17 18
>> A+B
ans =
12 14 16 18
20 22 24 26
Matrix multiplication is defined for a pair of matrices if their "inner" dimensions agree: thus we can multiply A times B if A has dimension m x n and B has dimension n x p. The result is a matrix of dimension m x p.
In conventional mathematical notation, matrix A times matrix B would be written simply AB. For Matlab, the expression AB would just be a two-character variable name, and the product of matrix A and matrix B is written A*B. One common mathematical convention is to denote matrices with boldface uppercase letters, vectors with boldface lowercase letters, and scalars with italic lowercase letters. But Matlab doesn't know about typefaces!
The easiest way to think about matrix multiplication C = AB is that element i,j of C (the result) is the inner product (sum of element-wise products) of row i of A and column j of B.
>> A=[1 2 3 4; 5 6 7 8]
A =
1 2 3 4
5 6 7 8
>> B=[1 2; 3 4; 5 6; 7 8]
B =
1 2
3 4
5 6
7 8
>> A*B
ans =
50 60
114 140
In the example above, we multiply a 2 x 4 matrix times a 4 x 2 matrix, resulting in a 2 x 2 matrix. Element 1,2 of the result (for instance) is 60, which is the inner product of the first row of A [1 2 3 4] and the second column of B [2 4 6 8]: 1*2 + 2*4 + 3*6 + 4*8 = 60.
From the definitions of matrix multiplication and transposition, it follows that (AB)' = B'A'.
>> A=[1 2 3 4;5 6 7 8];
>> B=[1 2;3 4;5 6;7 8];
>> (A*B)'
ans =
50 114
60 140
>> B'*A'
ans =
50 114
60 140
Since vectors are just "degenerate" matrices, we can now see that in order to get the inner product of two vectors, we have to treat the first one as a row vector (1 x n) and the second one as a column vector (n x 1), the result being a 1 x 1 matrix (i.e. a scalar).
>> a=[1 2 3 4]
a =
1 2 3 4
>> b=[2 4 6 8]'
b =
2
4
6
8
>> a*b
ans =
60
Now we can finally see how to write the inner product of two vectors! If a and b are column vectors (the default assumption), then the inner product of a and b is (in Matlab notation) a'*b.
Note that we can therefore write the sum of squares of a column vector a as a'*a.
The sum of squares of a row vector b is b*b'.
Thus we can exemplify normalizing a vector to unit length by dividing it by its (geometric) length:
>> a
a =
2
4
6
8
>> c=a/sqrt(a'*a)
c =
0.1826
0.3651
0.5477
0.7303
>> c'*c % Show that c is really of unit length!
ans =
1.0000
Like scalar multiplication, matrix multiplication is associative: (AB)C = A(BC).
Matrix multiplication is (also like scalar multiplication) distributive (over matrix addition): A(B+C)=AB+AC.
However, matrix multiplication is non-commutative: in general, AB does not equal BA. This is obvious in part because the inner dimensions might not agree: thus if A is 4 x 2 and B is 2 x 1, then AB is defined but BA is not. However, even multiplication of square matrices is not in general commutative:
>> A=[1 2; 3 4]
A =
1 2
3 4
>> B=[5 6; 7 8]
B =
5 6
7 8
>> A*B
ans =
19 22
43 50
>> B*A
ans =
23 34
31 46
Without further explanation for now, it's worth mentioning that there are three ways of looking at a matrix multiplication C=AB:
- Each entry of C is the product of a row and a column: Cij = inner product of ith row of A and jth column of B (as we said above).
- Each column of C is the product of a matrix and a column: jth column of C is A times jth column of B
- Each row of C is the product of a row and a matrix: ith row of C is ith row of A times B
Just as we gave a geometric interpretation to scalar multiplication of vectors and vector addition, we can also give a geometric interpretation of the inner product of two vectors: for (column) vectors a and b, the inner product a'b is the cosine of the angle between a and b, multiplied by the product of their lengths.
Thus the cosine of the angle between a and b is = a'b/|a||b|
It follows that when two vectors are at right angles, their inner product must be zero -- since cosine of 90 degrees is zero. Thus two vectors are orthogonal if and only if their inner product is zero.
If two vectors are colinear (i.e. they fall on the same line), then the angle between them is 0. Since the cosine of 0 is 1, it follows that their inner product divided by the product of their lengths must be 1. Let's examplify this in Matlab:
>> a=rand(5,1) % Random 5-element column vector
a =
0.7919
0.9218
0.7382
0.1763
0.4057
>> b=a*2.345 % Multiply by a scalar
b =
1.8571
2.1617
1.7311
0.4133
0.9514
>> a'*b/(sqrt(a'*a)*sqrt(b'*b)) % Length-normalized inner product is 1
ans =
1
We used "rand" to create a 5 x 1 matrix (i.e. a column vector) a of pseudo-random numbers; then we created a colinear vector b by scalar multiplication of a; then we calculated the cosine of the angle between a and b, as the inner product of a and b divided by the product of their lengths; this was (as it should be!) 1.
(What would the result be if we length-normalized each vector before taking the inner product? What about if we used a negative scalar, e.g. -2.345? Try it!)
Two vectors that are colinear (i.e. one of them is a scaled version of the other) are said to be linearly dependent; two vectors that are not linearly dependent are linearly independent.
For reasons that will become clear later, combinations of vectors created by addition and scalar multiplication are called linear combinations. Thus a linear combination of a set of vectors a1, ... an is a weighted sum, in which each vector is multiplied by some scalar coefficient, or weight, ci, and the results are all added up.
We can generalize the notion of linear independence to a set of vectors a1, ..., an: they are linearly independent if no one of them can be expressed as a linear combination of the others.
For a simple example where vectors are pairwise linearly independent, but are not setwise independent, consider the set of 2-element vectors {[1 0], [0 1], [1 1]}. No pair is linearly dependent (just graph them and think about the angles involved); but the third vector is the sum of the first two.
Vector spaces, subspaces and basis sets
A vector space is a set (typically infinite) of vectors that contains the origin and is closed under vector addition and scalar multiplication.
A subspace of a vector space is a subset that is also a vector space.
If we start with a set of vectors S, there will be some set of vectors V that we can make out of combinations of S by scalar multiplication and vector addition. In this case we say that the set of vectors S spans the vector space V.
So we can say that if a vector space V consists of all linear combinations of vectors b1, ... , bn, then those vectors span the space V. For every vector v in V, there will then be some set of (scalar) coefficients c1, ..., cn such that
v = c1*b1 + ... + cn*bn
If each of the n bn ... bn vectors has m elements, we can arrange them as the columns of an m x n matrix B. If we then call c an n x 1 vector containing the n coefficients c1, ..., cn, then the above equation can be rewritten in matrix form as
v = Bc
(since B is m x n, and c is n x 1, the result will be an m x 1 column vector, which is just right for v) In this case, the result v is a linear combination of the columns of B, with each of the elements of c being a scalar multiplier for the corresponding column of B. This follows from the basic definition of matrix multiplication.
If in addition the set of vectors b1, ... bn are all linearly independent, then they form a basis for V.
Note: the reason for the stipulation of independence is that if any of the vectors in the set were linearly dependent on another vector in the set, it could be obviously be removed without changing the vector space that is spanned.
For example, the two vectors [1 0] and [0 1] span the plane, because every point [x y] can be expressed as a linear combination of [1 0] and [0 1]. Note that the number of vectors in a basis is typically finite; in fact, for a vector space consisting of vectors with with M components, the basis set can have no more than M members.
Given the above, it's natural to define a vector space in terms of a matrix whose columns span it.
For a given basis set B and a given vector v in the space that B spans, the coefficients expressing v in terms of B are unique. However, there is no unique basis for a given vector space V: in general, there are infinitely many bases. Nevertheless, all the bases of a given vector space have something in common: the number of vectors is always the same. Thus if B and C are both bases for V, then B and C must both contain the same number of vectors -- which must be less than or equal to the number of elements in the vectors in V. This number is called the dimension of the vector space V.
Note: another ambiguity of terminology! When we talk about the dimension of a vector space, we might mean the number of elements in its vectors -- or the number of vectors in (any of) its basis sets.
Let's give a simple geometrical example. Consider points on a plane. We can identify each such point using two coordinates. One way to get these two coordinates is to lay out two axes at right angles to each other, each provided with a length scale. Then any point in the plane will "project" to some value on each of these two axes, and will thus be identified. We can change the length scale on the axes, and we can rotate the axes, and still we can use them to identify each point in the plane. In fact, the axes don't have to be at right angles -- as long as they are not parallel, then we can still identify any point in the plane by identifying its projection onto each of the axes.
Each of these axes is defined by a (2-element) vector, whose direction (from the origin) defines the orientation of the axis, and whose magnitude defines its length scale.
We can't solve the problem with just one vector -- for any point on the axis it defines, there will a line such that all the points on that line project to the same location on that axis. Also, there is no point in adding a third vector -- we can express any such vector in terms of the coordinate system defined by the other two.
If all the points that we care about happen to lie on a single line, then we can identify them with a single axis. However, we might still choose to give their coordinates in terms of locations in a plane -- in this case, we would be dealing with a one-dimensional subspace of the two-dimensional vector space R^n. Similarly, we might describe points on a (one-dimensional) line or a (two-dimensional) plane in terms of three-dimensional coordinates, i.e. three-element vectors.
If all the vectors in a basis set are (mutually) orthogonal, then it is called an orthogonal basis. If in addition the basis vectors are all of unit length, then it is an orthonormal basis.
If a vector space consists of M-element vectors, then its dimensionality -- in the sense of the number of vectors in its basis set -- must be between 1 and M, inclusive. In other words, we can embed a 2-dimensional space in a 3-dimensional one, but not the other way around.
Matrices as (linear) operators on vectors
A function f is linear if it obeys
superposition: f(a) + f(b) = f(a+b)
and
homogeneity: f(ca) = cf(a)
Superposition means that the function applied to a sum of inputs is the same as the sum of the function applied to the inputs taken individually. Homogeneity means that the function applied to a scaled input gives the same result as scaling the function applied to the (unscaled) input.
Why is linearity interesting? It's easy to deal with mathematically, and many real-world phenomena can be well modeled as linear systems. For instance, many acoustic, electrical and mechanical systems are linear, or can be treated as such under certain conditions. As a result, most signal processing (whether analog or digital) deals with the design or analysis of linear systems.
Note that a matrix of dimensions m x n, when multiplied by a column vector of dimensions n x 1, produces another column vector of dimensions m x 1. Thus an m x n matrix can be seen as a function from n-vectors to m-vectors.
It's easy to show that all such functions (i.e. those expressed by matrix multiplication) are linear. It's not much harder to show that any linear function can be expressed in this way.
As a result, the set of possible linear functions from n-vectors to m-vectors are all and only the m x n matrices.
Some special matrices.
The identity matrix is a square matrix with ones on the diagonal (the elements whose row and column indices are equal), and zeros everywhere else. It is usually symbolized with an I (for identity), or I sub n (for an identity matrix with n rows and columns). Matlab punningly uses the function eye(n) to generate I sub n:
>> eye(3)
ans =
1 0 0
0 1 0
0 0 1
>> eye(5)
ans =
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
For obvious reasons, eye(n) transforms n-element vectors to themselves.
A diagonal matrix has non-zero values on the diagonal and zeros elsewhere. The Matlab functional diag(a) will create a square diagonal matrix from a vector specifying the diagonal elements:
>> diag([1 2 3 4])
ans =
1 0 0 0
0 2 0 0
0 0 3 0
0 0 0 4
A diagonal matrix performs the transformation of scaling vectors dimension-by-dimension: thus the matrix just given will leave the first element of a vector unchanged, multiply the second element by 2, etc. If these multiplications are interpretated geometrically, then a negative number means reflection around the origin (along the dimension in question), and a zero means that any variation along the dimension in question is eliminated, lowering the effective dimensionality of a vector space thus transformed.
We can invert the effect of scaling by a diagonal matrix by scaling with another diagonal matrix whose values are the element-wise inverses:
>> diag(1./[2 3 4])*diag([2 3 4])
ans =
1 0 0
0 1 0
0 0 1
In general, the inverse of a (square n x n) matrix A is another matrix B such that A*B is the n x n identity matrix ("eye(n)").
Note that in the last example, we used element-wise division, which is written in Matlab as ./ :
>> 1./[2 3 4] ans = 0.5000 0.3333 0.2500 >> [1 2 3]./[2 3 4]
ans =
0.5000 0.6667 0.7500
Element-wise multiplication works similarly:
>> [1 2 3].*[2 3 4]
ans =
2 6 12
A set of vectors is orthogonal if the inner product of every (non-identical) pair is 0.
A set of vectors is orthonormal if the inner product of every non-identical pair is 0 (i.e. they are orthogonal), and the product of every vector with itself is 1 (i.e. the vectors all have geometric length 1). An orthogonal matrix is a square matrix whose columns are orthonormal.
(Note: this terminology is quite confusing. The term logically should be orthonomal matrix, but it isn't.)
For any orthogonal matrix, its inverse is simply its transpose. You can see that this is true essentially by inspection: if R is an orthogonal matrix, then in carrying out R'*R for elements on the diagonal, the inner product of the ith row of R' and the ith column of R will be 1; while for off-diagonal elements, the inner product of the ith row of R' and the jth column of R (i different from j) will be 0.
Another key property of an orthogonal matrix (as an operation on vectors) is that it is length-preserving. That is, for any vector a, |Ra| = |a|.
The proof is easy: (Ra)'(Ra) = a'R'Ra = a'a. Thus the length of Ra is the same as the length of a. It also follows that any length-preserving matrix is orthogonal.
An orthogonal matrix also preserves inner products (and angles), so that (Ra)(Rb) = ab.
An orthonormal basis for a vector space (unsuprisingly) is a set of basis vectors that are orthonormal. Suppose B is a matrix whose columns are a set of orthonormal basis vectors, and we want to find the coefficients (relative to B) for some arbitrary vector a. This is equivalent to solving the equation
Bx = a
because Bx is a linear combination of the columns of B, with x providing the weights. Since B is orthogonal, we can multiply on the left by B', yielding
B'Bx = B'a
which reduces to
x = B'a
(For future reference, this is the "basis" of the Discrete Fourier Transform, among other useful things).
In two dimensions, a rotation (counterclockwise) by angle theta is accomplished by a rotation matrix with the structure
cos(theta) -sin(theta) sin(theta) cos(theta)
Note that this is an orthogonal matrix, as it must be since rotation is a length-preserving transform.
One way to remember this formula is to consider certain special cases:
- For a 360-degree rotation (theta = 2*pi), this is just eye(2), as it should be!
- For a 180-degree rotation (theta = pi), this is [-1 0; 0 -1]; i.e. it reflects along both the 1st and 2nd dimensions.
- For a 90-degree rotation (theta = pi/2), this is [0 -1; 1 0]; thus it operates
as follows:
>> R=[0 -1;1 0] R = 0 -1 1 0 >> R*[1 0]' ans = 0 1 >> R*[0 1]' ans = -1 0 >> R*[1 1]' ans = -1 1
We can perform a rotation in the plane defined by any pair of coordinates in an n-dimensional space, by embedding the 2-D rotation matrix in the appropriate four cells in eye(n). Thus in 3-space, we can rotate in the plane defined by the 1st and 3rd dimensions with a matrix like this:
cos(theta) 0 -sin(theta)
0 1 0
sin(theta) 0 cos(theta)
One way to create more general multi-dimensional rotation matrices is by combining such matrices, each of which accomplishes a rotation in a single plane defined by a pair of coordinates. Although all rotation matrices are orthogonal, the inverse is not true, since orthogonal matrices can also accomplish reflections.
Advanced Review
If the foregoing went down easily, go on to learn (or remind yourself) about singular value decomposition and eigenanalysis. If not, don't worry -- we'll get back to this stuff later.
Singular Value Decomposition (SVD)
There are plenty of other sorts of special matrices, and also plenty of other geometrical transformation that we can contemplate. However, what we have seen so far is enough to let us define an extremely general and useful result: singular value decomposition.
Any m by n matrix X can be factored into X = U*S*V' , where U is an m by m orthogonal matrix, S is an m by n diagonal matrix, and V is an n by n orthogonal matrix.
Another way to put this is that ANY matrix can be viewed as a rigid rotation (with possible reflection), followed by an axis scaling, followed by another rigid rotation/reflection.
We'll see a number of applications of SVD. Here's a Matlab example, both to show how to do SVD in Matlab and to show that it works, in the sense that constructed examples of rotations and scaling are corrected decomposed! We start by setting up some rotation and scaling matrices in three dimensions.
>> % 3-D rotations by 22.5 degrees, 2 dimensions at a time:
>> mxr = [1 0 0; 0 cos(pi/8) -sin(pi/8);0 sin(pi/8) cos(pi/8)]
mxr =
1.0000 0 0
0 0.9239 -0.3827
0 0.3827 0.9239
>> myr = [cos(pi/8) 0 -sin(pi/8);0 1 0; sin(pi/8) 0 cos(pi/8)]
myr =
0.9239 0 -0.3827
0 1.0000 0
0.3827 0 0.9239
>> mzr = [cos(pi/8) -sin(pi/8) 0; sin(pi/8) cos(pi/8) 0; 0 0 1]
mzr =
0.9239 -0.3827 0
0.3827 0.9239 0
0 0 1.0000
>> % axis-wise scalings:
>> mxs = [0.5 0 0; 0 1 0; 0 0 1]
mxs =
0.5000 0 0
0 1.0000 0
0 0 1.0000
>> mys = [1 0 0; 0 1.5 0; 0 0 1]
mys =
1.0000 0 0
0 1.5000 0
0 0 1.0000
>> mzs = [1 0 0; 0 1 0; 0 0 2.0]
mzs =
1 0 0
0 1 0
0 0 2
Now we'll try producing some matrices by combining various of these operations,
and then using SVD to decompose the combined result:
>> M = mzr*mxs*mzr'
M =
0.5732 -0.1768 0
-0.1768 0.9268 0
0 0 1.0000
>> [U,S,V] = svd(M)
U =
0.3827 0 0.9239
-0.9239 0 0.3827
0 1.0000 0
S =
1.0000 0 0
0 1.0000 0
0 0 0.5000
V =
0.3827 0 0.9239
-0.9239 0 0.3827
0 1.0000 0
>> U*S*V'
ans =
0.5732 -0.1768 0
-0.1768 0.9268 0
0 0 1.0000
As you can see, svd() correctly reproduces the matrix.
Can you figure out how U, S and V are related to mzr and mxs?
mzr*mxs*mzr'
rotates counterclockwise by 22.5 in the xy plane (pi/8), scales the x-axis by .5, and then rotates back; whereas
U*S*V'
rotates clockwise by 67.5 degrees in the xz plane (-3*pi/8), scales the z-axis by .5, and then rotates back. Since mzr*mxs*mzr' = U*S*V', these two transformation sequences must accomplish the same thing -- can you visualize it?
Basically the result is to "squash" the space along a particular direction. We generated one transformation by rotating the space so as to line this direction up with the x-axis, doing the squashing, then rotating back. SVD generates the other one by rotating the space so as to line this direction up with the z-axis, doing the squashing, then rotating back. Since all we gave svd() was the overall transformation matrix, it has no way to "know" which of the the equivalent procedures we used to generate the transformation. In choosing its answer, it will try to arrange for the singular values (the numbers along the diagonal of S) to be sorted in descending order.
In the following example, svd() correctly figures out that the z dimension has been obliterated in between the two rotations. Can you figure out how it has re-construed the rotations?
>> mzp = [1 0 0; 0 1 0; 0 0 0];
>> M=mxr*mzp*myr
M =
0.9239 0 -0.3827
0 0.9239 0
0 0.3827 0
>> [U,S,V]=svd(M)
U =
1.0000 0 0
0 0.9239 0.3827
0 0.3827 -0.9239
S =
1 0 0
0 1 0
0 0 0
V =
0.9239 0 -0.3827
0 1.0000 0
-0.3827 0 -0.9239
>> U*S*V'
ans =
0.9239 0 -0.3827
0 0.9239 0
0 0.3827 0
Eigenvectors and eigenvalues
The result of multiplying an n x n matrix A by a n x 1 vector x is another n x 1 vector. Likewise, the result of multiplying a scalar s by an n x 1 vector x is another n x 1 vector. This raises the possibility that we could choose A, x and s such that
Ax = sx
That is, there might be vectors x that matrix A just "scales", i.e. changes in length but not in direction.
In this case, we call x an eigenvector of A, and s is the corresponding eigenvalue. This is not a normal situation, since typically x changes direction when multiplied by A. If A is a multiple of the identity matrix, then it does not change the direction of any vector, and every vector is an eigenvector for it. However, normally eigenvectors and eigenvalues are rare, special and revealing, as the etymology of the term implies -- German eigen means "own, proper, individual, particular, special, exact, peculiar".
Suppose an n x n matrix A has n linearly independent eigenvectors, and we arrange these as the columns of a matrix E. Then the ith column of the product AE is A times the ith column of E. Since the columns of E are the eigenvectors of A, this is equivalently the ith column of E times the ith eigenvalue. We can express this through the matrix expression EL, where L is a diagonal matrix with the eigenvalues of A on the diagonal; the ith column of the result is just the product of the ith eigenvector (the ith column of E) by the ith eigenvalue (the ith diagonal element of L). Thus
AE = EL
Multiplying on the left by E inverse gives us
E^(-1)AE = L
Multiplying on the right by E^(-1) gives us the eigenvector-eigenvalue factorization
A = ELE^(-1)
Note that E is not unique. If we multiply an eigenvector by a scalar, it remains an eigenvector. Sometimes there is even more freedom -- in the limit, for the identity matrix, any vector is an eigenvector, and so E can be any invertible matrix.
Furthermore, not all matrices have n linearly independent eigenvectors. In such a case, E does not exist. If E exists, then the matrix A is said to be diagonalizable.
An important fact: the eigenvectors of A are also eigenvectors of A^k, and the corresponding eigenvalues are the original ones raised to the kth power.
Another important fact: A real symmetric matrix A (matrix A is symmetric iff A = A') can be factored into
A = QLQ'
where the columns of Q are orthonormal eigenvectors, and L is a diagonal matrix of eigenvalues. This is known as the spectral theorem -- we'll learn why later. Notice that this means that any transformation implemented by such a matrix can be interpreted as a rotation, an axis scaling, and the inverse of the original rotation.
Notational note: usually the greek letter lamba is used for eigenvalues -- lower case lamba for individual eigenvalues, and upper case lamba for the diagonal matrix with the eigenvalues on the diagonal.
Relationship between Eigenvector/eigenvalue factorization and SVD
Recall the definition of Singular Value Decomposition: any m by n matrix X can be factored into X = USV' , where U is an m by m orthogonal matrix, S is an m by n diagonal matrix, and V is an n by n orthogonal matrix.
It should be clear that there is a relationship between this and eigenvector/eigenvalue analysis.
For the specific case of real symmetric matrices, where we had A = QLQ', and Q was orthogonal, the relationship is easy. SVD's U matrix is exactly the eigenvector matrix; S is exactly the eigenvalue matrix; and V will be the same as U. Let's illustrate this in Matlab:
%% to make a random real symmetric matrix,
%% we take the covariance of a random square matrix:
>> A=cov(rand(4))
A =
0.0116 0.0025 -0.0078 0.0147
0.0025 0.0527 -0.0211 0.0112
-0.0078 -0.0211 0.0207 -0.0098
0.0147 0.0112 -0.0098 0.0211
>> [U,S,V]=svd(A)
U =
0.1794 -0.5781 0.0107 -0.7960
0.8111 0.4703 -0.3074 -0.1629
-0.4461 0.1349 -0.8595 -0.2100
0.3332 -0.6531 -0.4083 0.5439
S =
0.0695 0 0 0
0 0.0280 0 0
0 0 0.0086 0
0 0 0 0.0000
V =
0.1794 -0.5781 0.0107 -0.7960
0.8111 0.4703 -0.3074 -0.1629
-0.4461 0.1349 -0.8595 -0.2100
0.3332 -0.6531 -0.4083 0.5439
>> %% Now we check that A*U = U*S
>> A*U
ans =
0.0125 -0.0162 0.0001 -0.0000
0.0563 0.0132 -0.0026 -0.0000
-0.0310 0.0038 -0.0074 -0.0000
0.0231 -0.0183 -0.0035 -0.0000
>> U*S
ans =
0.0125 -0.0162 0.0001 -0.0000
0.0563 0.0132 -0.0026 -0.0000
-0.0310 0.0038 -0.0074 -0.0000
0.0231 -0.0183 -0.0035 0.0000
>> %% Now we check that diagonalization works as advertised
>> inv(U)*A*U
ans =
0.0695 0.0000 -0.0000 -0.0000
0.0000 0.0280 -0.0000 0.0000
0.0000 -0.0000 0.0086 0.0000
-0.0000 0.0000 0.0000 0.0000
>> S
S =
0.0695 0 0 0
0 0.0280 0 0
0 0 0.0086 0
0 0 0 0.0000
There is a more general relationship between SVD and eigenanalysis. In the SVD factorization
A = USV'
the columns of U are eigenvectors of AA', and the columns of V are eigenvectors of A'A. The singular values on the diagonal of S are the square roots of the nonzero eigenvalues of both AA' and A'A.
This is pretty easy to derive:
AA' = (USV')(USV')' = (USV')(VS'U') = USS'U' , SS' is diagonal with values that are the squares of those in S, etc.
The SVD factorization X = USV' is much more general than the eigenvector/eigenvalue factorization X = ELE^(-1)
- SVD applies to matrices of any shape, not just square ones
- SVD applies to any matrix, not just diagonalizable ones or those that pass some other test
However, the eigenvector/eigenvalue concepts are extremely important and (paradoxically) are applied more widely. In part this is precisely because the factorization is more restrictive: when it applies, some important other properties apply, especially the behavior under exponentiation. This last is responsible for the role that eigenvectors and eigenvalues play in solving differential equations, difference equations, Markovian systems, and so on.