COGS501: Notes on Reading #1
These are some notes to help you read Henrietta Cedergren and David Sankoff, "Variable Rules: Performance as a Statistical Reflection of Competence", Language, 50(2) pp. 333-355, 1974.
The basic idea of linear regression is to predict the M values of a dependent variable (which we treat as a column vector b), on the basis of the values of N independent variables (which we put in the rows of an M by N matrix A), using the N coefficients that we put in a column vector x.
Since we don't expect the prediction to be perfect, we add an error term, and choose x so the (sum of squared) errors are as small as possible in the matrix equation
b = Ax + error
In Matlab, we can do this by setting
x = A\b;
The predicted values can then be calculated as
c = A*x;
Note that this creates each predicted value ci as
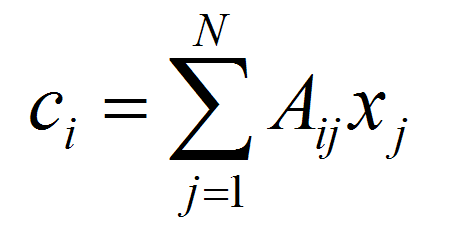
so that in the homework exercise, where N=3,
c13 = A13,1x1 + A13,2x2 + A13,3x3
But what if the independent ("predictor") don't simply add up (after having been suitably multiplied by the coefficients xi), but instead multiply or combine in some other way?
For example, suppose that our independent variables are correlated with some length dimensions of an object, whereas our dependent variable is related to its volume. For example, we might measure the overall height and main trunk diameter of trees, and try to predict the amount (weight) of wood that a tree will produce.
We shouldn't expect to get very far with a model of the form
mass of tree = x1 + x2*H + x3*D
where H is height and D is diameter, and x1, x2 and x3 are regression coefficients. But let's see!
I located some actual Alaskan tree biomass data (documented here), with 29 variables provided for each of 281 trees. Column #1 is tree species; #4 is "tree diameter at 1.37 m aboveground" (i.e. breast height), in centimeters; Column #5 is tree height (in meters); Column #11 is "total wood green weight" (in grams); Column #12 is "total wood dry weight". (There are only 95 trees for which all four of these numerical measurements are available.)
We can see what the problem is going to be if we bring the data into Matlab and plot diameter against green weight:
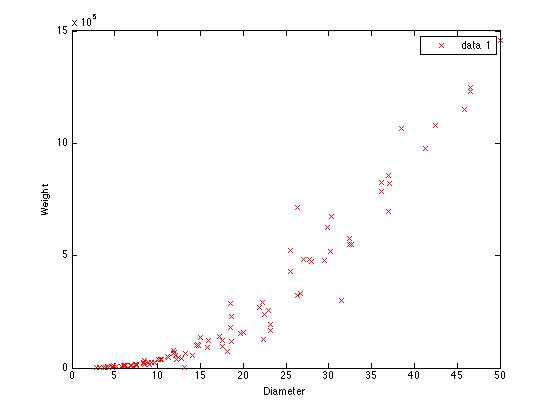
Of course, we can still fit the line that minimizes the sum of squared errors -- and you might be surprised to learn that it's a pretty good fit, even with the single predictor variable of diameter: we get an r2 of 0.8898, and a p value that is so small, the computer can't distinguish it from 0.
Most experimental linguists, psychologists and biologists would be very happy to do so well. We should be pleased: we got a highly significant result, we accounted for nearly 90% of the variance -- what's not to like?
Well, it should be pretty clear from a plot that we're missing something:

One thing that we're missing is the height -- but that looks somewhat similar:

Regressing weight against height gives us a somewhat lower r2 of 0.7491 -- though the p value is still indistinguishable from 0.
And regressing against both diameter and height at once only improves the fit to r2 = 0.8902, just a pitiful .0004 better than the diameter alone.
The problem isn't our predictor variables, it's the functional form of our model.
And here the grade-school physics of the situation points us in a different direction. Since weight is proportional to volume, and a tree is roughly a cylinder (whose volume is height*pi*(diameter/2)^2), a simple starting point might be a model something like
mass of tree = x1 + x2 * H*D^2
where H is height, D is diameter, and x1 and x2 are regression coefficients. We can try this out by creating a new variable, in Matlab-ese something like
HD = H.*D^2;
and plotting (and regressing) green weight against the new variable:

This improves the fit to r2 = 0.9661 -- but more important, the pattern of residuals is much more reasonable-looking.
There's more to do here -- a bit of poking around will convince us that different tree species work a bit differently, for example -- but this is enough to make the point.
The lesson so far? It's all too easy to fit a completely inappropriate model, and still get numerically excellent results.
As Dick Hamming used to love to say, "Beware of finding what you're looking for!"
Against this background, I'm skeptical of the second of the three criteria that Cedergren and Sankoff suggest for the formulation of what they call "variable rules" (p. 336):
The statement that a given feature tends to have a fixed effect independent of the other aspects of the environment may be mathematically formulated in a number of different ways. In choosing amng them, we must consider three basic criteria. First, the formulation must predict rule frequencies that jibe with the observed data. Second, it must be as universally applicable as posible; a different type of mathematical structure for each variable rule is to be avoided. Third, the formulation should have some reasonable interpretation as a statement about linguistic competence. [emphasis added]
While there's no reason to multiply models beyond necessity, it's dangerous (and unnecessary!) to insist that every linguistic relationship that we might want to model should be fit to the procustean bed of any single "mathematical structure".
Both because of what the data itself tells us, and also often because of reasoning from more general principles (as in the case of the physics of tree weight), individual problems often need individual solutions.
The consequences of fitting an inappropriate model may be much worse than a lower-than-necessary r2 -- it's easy to be led to wrong conclusions about the qualitative effects (and interactions) of variables.
This is not an unusual or weird or obscure effect. It's so common in practice that one particular sub-case even has a name (and a wikipedia entry): Simpson's Paradox.
That said, Cedergren and Sankoff's discussion of one particular class of cases -- modeling the proportion of successes (i.e. "rule applications") as a function of independent influences on underlying probabilities -- is absolutely on target.
Let's go through a simple example, in which a "rule" (say, whether or not to simplify a consonant cluster) is independently influenced by two factors (say social group and following phonological context). We'll assume that the "rule" applies about half the time in the least-favorable situation, and that each of the two factors can take on two values, one of which substantially increases the probability that the rule will apply.
The true underlying model -- and we know that it's true in this case because we created it -- is as follows:
The base rate of application (factor values 0 0) is 0.5.
When factor 2 is present, it multiplies the rate of non-application by 0.2, so that the true rate of application given factor values 0 1 is (1.0 - 0.5*0.2) = 0.9.
When factor 1 is present, it multiplies the rate of non-application by 0.1, so that that the true rate of application in condition 1 0 is (1.0 - 0.5*0.1) = 0.95.
And factors 1 and 2 are independent, so that the true rate of application in condition 1 1 is (1.0 - 0.5*0.2*0.1) = 0.99.
Some matlab code that generates 1,000 random data points is here.
The resulting "data", from one random run:
| Factor 1 | Factor 2 | Rule applies | Total opportunities | Proportion |
It should be obvious that if we try to predict the observed proportions using an additive model, we're going to run into trouble.
>> A1 = [1 0 0; 1 0 1; 1 1 0; 1 1 1];
>> y1 = applications ./ opportunities;
>> x = A1\y1 x = 0.5409 0.3050 0.2570 >> [1 1 1]*x ans = 1.1028
This predicts case [0 0] as 0.541 instead of 0.5; case [0 1] as 0.8 rather than 0.9; case [1 0] as 0.81 rather than 0.95; and case [1 1] as (the impossible proportional rate of) 1.10 rather than 0.99.
Regression has helpfully spread the errors out, so the overall fit is not too terrible -- we still get r2 of 0.76 or so, with p < 0.05. (If the cases are not equally frequent, as will often happen, we might do quite a bit better than that, since the model can stick the rarer conditions with bigger deviations ...)
But if we follow the prescriptions of Cedergren and Sankoff, things are going to work out much better.
>> A2 = [0 0; 0 1; 1 0; 1 1];
>> b = glmfit(A2, [counts totals], 'binomial');
>> yhat = glmval(b, A2, 'logit');
>> yhat
yhat =
0.5194
0.8924
0.9456
0.9926
This time, the r2 -- proportion of variance accounted for -- is 0.9983.
But what are 'binomial' and 'logit', anyow, and what are glmfit() and glmval() really doing? Basically it's the same thing that we did with the trees. We're replacing the observed variables -- here frequencies of occurrence -- with new variables that we believe ought to have a linear relationship to the predicting factors.
For this to work, we basically need two things. First, we need to map probabilities in the model (or proportions in the data) from the interval 0-1 to unbounded values on the number line. And second, we need the multiplication of probabilities to turn into addition, because our linear models are additive.
Oh, and it would be nice if p = .5 turned out to be 0, with higher and lower p values mapped symmetrically onto the positive and negative numbers.
In this case, the change-of-variables trick that's usually used is called the logit function:

Note that for p=0.5, logit(p) = 0; and as p approaches 1, logit(p) approaches positive infinity, while as p approaches 0, logit(p) heads for negative infinity.
And of course, multiplying or dividing "odds" (and "odds" is what p/(1-p) really is, if you think about it) will turn into adding or subtracting "log odds".
We'll come back later to the details of how this transformation of variables (and the corresponding un-transformation later on) really works.
The point for now -- the basic point of Cedergren and Sankoff's paper -- is that if (we think that) our data was generated by the interaction of independent random variables, we should construct our model with a mathematical structure that reflects this belief.
Once we accept this, our task is to figure out what the right mathematical structure is, and how to use it in model building.
But let's not forget Hamming's Rule: "Beware of finding what you're looking for".
[Note: the Matlab code used to generate the figures and regression results discussed above is here.]