This is the first of a sequence of lectures discussing various levels of linguistic analysis.
We'll start with morphology, which deals with morphemes (the minimal units of linguistic form and meaning), and how they make up words.
We'll then discuss phonology, which deals with phonemes (the meaningless elements that "spell out" the sound of morphemes), and phonetics, which studies the way language is embodied in the activity of speaking, the resulting physical sounds, and the process of speech perception..
Then we'll look at syntax, which deals with the way that words are combined into phrases and sentences. Finally, we'll take up two aspects of meaning, namely semantics, which deals with how sentences are connected with things in the world outside of language, and pragmatics, which deals with how people use all the levels of language to communicate.
The peculiar nature of morphology
From a logical point of view, morphology is the oddest of the levels of linguistic analysis. Given the basic design of human spoken language, the levels of phonology, syntax, semantics and pragmatics are arguably unavoidable. They needn't look exactly the way that they do, perhaps, but there has to be something to do the work of each of these levels.
But morphology is basically gratuitous: anything that a language does with morphology, it usually can also do with syntax; and there is always some other language that always the same thing with syntax.
For instance, English morphology inflects nouns to specify plurality: thus dogs means "more than one dog". This inflection lets us be specific, in a compact way, about the distinction between one and more-than-one. Of course, we could always say the same thing in a more elaborated way, using the resources of syntax rather than morphology: more than one dog. If we want to be vague, we have to be long winded: one or more dogs.
Modern Standard Chinese (also known as "Mandarin" or "Putonghua") makes exactly the opposite choice: there is no morphological marking for plurality, so we can be succinctly vague about whether we mean one or more of something, while we need to be more long-winded if we want to be specific. Thus (in Pinyin orthography with tone numbers after each syllable):
| 1. | na4er5 | you3 | gou3 | ||
| there | have | dog | |||
| "there's a dog or dogs there." | |||||
| 2. | na4er5 | you3 | ji3 | zhi1 | gou3 |
| there | have | several | CLASSIFIER | dog | |
| "there's dogs there" | |||||
As an example of another kind of morphological packaging, English can make iconify from icon and -ify, meaning "make into an icon." Perhaps it's nice to have a single word for it, but we could always have said "make into an icon." And many languages lack any general way to turn a noun X into a verb meaning "to make into (an) X", and so must use the longer-winded mode of expression. Indeed, the process in English is rather erratic: we say vaporize not *vaporify, and emulsify not *emulsionify, and so on.
In fact, one of the ways that morphology typically differs from syntax is its combinatoric irregularity. Words are mostly combined logically and systematically. So when you exchange money for something you can be said to "buy" it or to "purchase" it -- we'd be surprised if (say) groceries, telephones and timepieces could only be "purchased," while clothing, automobiles and pencils could only be "bought," and things denoted by words of one syllable could only be "acquired in exchange for money."
Yet irrational combinatoric nonsense of this type happens all the time in morphology. Consider the adjectival forms of the names of countries or regions in English. There are at least a half a dozen different endings, and also many variations in how much of the name of the country is retained before the ending is added:
| -ese | Bhutanese, Chinese, Guyanese, Japanese, Lebanese, Maltese, Portuguese, Taiwanese |
| -an | African, Alaskan, American, Angolan, Cuban, Jamaican, Mexican, Nicaraguan |
| -ian | Argentinian, Armenian, Australian, Brazilian, Canadian, Egyptian, Ethiopian, Iranian, Jordanian, Palestinian, Serbian |
| -ish | Irish, British, Flemish, Polish, Scottish, Swedish |
| -i | Afghani, Iraqi, Israeli, Kuwaiti, Pakistani |
| -? | French, German, Greek |
And you can't mix 'n match stems and endings here: *Taiwanian, *Egyptese, and so on just don't work.
To make it worse, the word for citizen of X and the general adjectival form meaning associated with locality X are usually but not always the same. Exceptions include Pole/Polish, Swede/Swedish, Scot/Scottish, Greenlandic/Greenlander. And there are some oddities about pluralization: we talk about "the French" and "the Chinese" but "the Greeks" and "the Canadians". The plural forms "the Frenches" and "the Chineses" are not even possible, and the singular forms "the Greek" and "the Canadian" mean something entirely different.
What a mess!
It's worse in some ways than having to memorize a completely different word in every case (like "The Netherlands" and "Dutch"), because there are just enough partial regularities to be confusing.
This brings up George W. Bush. For years, there has been a web feature at Slate magazine devoted to "Bushisms", many if not most of them arising from his individual approach to English morphology. Some of the early and famous examples, from the 1999 presidential campaign, focus on the particular case under discussion here:
"If the East Timorians decide to revolt, I'm sure I'll have a statement." Quoted by Maureen Dowd in the New YorkTimes, June 16, 1999
"Keep good relations with the Grecians."Quoted in the Economist, June 12, 1999
"Kosovians can move back in."CNN Inside Politics, April 9, 1999
President Bush, if these quotes are accurate, quite sensibly decided that -ian should be the default ending, after deletion of a final vowel if present. This follows the common model of Brazil::Brazilians and Canada::Canadians, and gives Bush's East Timor::East Timorians, Greece::Grecians and Kosovo::Kosovians, instead of the correct (but unpredictable) forms East Timorese, Greeks and Kosovars. And why not? The President's method is more logical than the way the English language handles it.
Despite these derivational anfractuosities, English morphology is simple and regular compared to the morphological systems of many other languages. One question we need to ask ourselves is: why do languages inflict morphology on their users -- and their politicians?
What is a word?
We've started talking blithely about words and morphemes as if it were obvious that these categories exist and that we know them when we see them. This assumption comes naturally to literate speakers of English, because we've learned through reading and writing where white space goes, which defines word boundaries for us; and we soon see many cases where English words have internal parts with separate meanings or grammatical functions, which must be morphemes.
In some languages, the application of these terms is even clearer. In languages like Latin, for example, words can usually be "scrambled" into nearly any order in a phrase. As Allen and Greenough's New Latin Grammar says, "In connected discourse the word most prominent in the speaker's mind comes first, and so on in order of prominence."
Thus the simple two-word sentence facis amice "you act kindly" also occurs as amice facis with essentially the same meaning, but some difference in emphasis. However, the morphemes that make up each of these two words must occur in a fixed order and without anything inserted between them. The word amice combines the stem /amic-/ "loving, friendly, kind" and the adverbial ending /-e/; we can't change the order of these, or put another word in between them. Likewise the verb stem /fac-/ "do, make, act" and the inflectional ending /-is/ (second person singular present tense active) are fixed in their relationship in the word facis, and can't be reordered or separated.
Among many others, the modern Slavic languages such as Czech and Russian show a similar contrast between words freely circulating within phrases, and morphemes rigidly arranged within words. In such languages, the basic concepts of word and morpheme are natural and inevitable analytic categories.
In a language like English, where word order is much less free, we can still find evidence of a similar kind for the distinction between morphemes and words. For example, between two words we can usually insert some other words (without changing the basic meaning and relationship of the originals), while between two morphemes we usually can't.
Thus in the phrase "she has arrived", we treat she and has as separate words, while the /-ed/ ending of arrived is treated as part of a larger word. In accordance with this, we can introduce other material into the white space between the words: "she apparently has already arrived." But there is no way to put anything at all in between /arrive/ and /-ed/. And there are other forms of the sentence in which the word order is different -- "has she arrived?"; "arrived, has she?" -- but no form in which the morphemes in arrived are re-ordered.
Tests of this kind don't entirely agree with the conventions of English writing. For example, we can't really stick other words in the middle of compound words like swim team and picture frame, at least not while maintaining the meanings and relationships of the words we started with. In this sense they are not very different from the morphemes in complex words like re+calibrate or consumer+ism, which we write "solid", i.e. without spaces. A recent (and controversial) official spelling reform of German make changes in both directions splitting some compounds orthographically while merging others: old radfahren became new Rad fahren, but old Samstag morgen became new Samstagmorgen..
As this change emphasizes, the question of whether a morpheme sequence is written "solid" is largely a matter of orthographic convention, and in any case may be variable even in a particular writing system. English speakers feel that many noun-noun compounds are words, even though they clearly contain other words, and may often be written with a space or a hyphen between them: "sparkplug", "shot glass". These are common combinations with a meaning that is not entirely predictable from the meanings of their parts, and therefore they can be found as entries in most English dictionaries. But where should we draw the line? are all noun compounds to be considered words, including those where compounds are compounded? What about (say) government tobacco price support program? In ordinary usage, we'd be more inclined to call this a phrase, though it is technically correct to call it a "compound noun" and thus in some sense a single -- though complex -- word. Of course, in German, the corresponding compound would probably be written solid, making its "wordhood" plainer.
Universality of the concepts "word" and "morpheme"
Do the concepts of word and morpheme then apply in all languages? The answer is "(probably) yes". Certainly the concept of morpheme -- the minimal unit of form and meaning -- arises naturally in the analysis of every language.
The concept of word is trickier. There are at least two troublesome issues: making the distinction between words and phrases, and the status of certain grammatical formatives known as clitics.
Words vs. phrases
Since words can be made up of several morphemes, and may include several other words, it is easy to find cases where a particular sequence of elements might arguably be considered either a word or a phrase. We've already looked at the case of compounds in English.
In some languages, this boundary is even harder to draw. In the case of Chinese, the eminent linguist Y.R. Chao (1968: 136) says, 'Not every language has a kind of unit which behaves in most (not to speak all) respects as does the unit called "word" . . . It is therefore a matter of fiat and not a question of fact whether to apply the word "word" to a type of subunit in the Chinese sentence.' On the other hand, other linguists have argued that the distinction between words and phrases is both definable and useful in Chinese grammar. The Chinese writing system has no tradition of using spaces or other delimiters to mark word boundaries; and in fact the whole issue of how (and whether) to define "words" in Chinese does not seem to have arisen until 1907, although the Chinese grammatical tradition goes back a couple of millennia.
Status of clitics
In most languages, there is a set of elements whose status as separate words seems ambiguous. Examples in English include the 'd (reduced form of "would"), the infinitival to, and the article a, in I'd like to buy a dog. These forms certainly can't "stand alone as a complete utterance", as some definitions of word would have it. The sound pattern of these "little words" is also usually extremely reduced, in a way that makes them act like part of the words adjacent to them. There isn't any difference in pronunciation between the noun phrase a tack and the verb attack. However, these forms are like separate words in some other ways, especially in terms of how they combine with other words.
Members of this class of "little words" are known as clitics. Their peculiar properties can be explained by assuming that they are independent elements at the syntactic level of analysis, but not at the phonological level. In other words, they both are and are not words. Some languages write clitics as separate words, while others write them together with their adjacent "host" words. English writes most clitics separate, but uses the special "apostrophe" separator for some clitics, such as the reduced forms of is, have and would ('s 've 'd), and possessive 's.
The possessive 's in English is an instructive example, because we can contrast its behavior with that of the plural s. These two morphemes are pronounced in exactly the same variable way, dependent on the sounds that precede them:
| Noun | Noun + s (plural) | Noun + s (possessive) | Pronunciation (both) |
| thrush | thrushes | thrush's | iz |
| toy | toys | toy's | z |
| block | blocks | block's | s |
And neither the plural nor the possessive can be used by itself. So from this point of view, the possessive acts like a part of the noun, just as the plural does. However, the plural and possessive behave very differently in some other ways:
- If we add a following modifier to a noun, the possessive follows the modifier,
but the plural sticks with the head noun:
Morpheme stays with head noun Morpheme follows modifier Plural The toys I bought yesterday were on sale. *The toy I bought yesterdays were on sale. Possessive *The toy's I bought yesterday price was special. The toy I bought yesterday's price was special.
In other words, the plural continues like part of the noun, but the possessive acts like a separate word, which follows the whole phrase containing the noun (even though it is merged in terms of sound with the last word of that noun phrase).
- There are lots of nouns with irregular plurals, but none with irregular
possessives:
Plural (irregular in these cases) Possessive (always regular) oxen ox's spectra spectrum's mice mouse's
Actually, English does have few irregular possessives: his, her, my, your, their. But these exceptions prove the rule: these pronominal possessives act like inflections, so that the possessor is always the referent of the pronoun itself, not of some larger phrase that it happens to be at the end of.
So the possessive 's in English is like a word in some ways, and like an inflectional morpheme in some others. This kind of mixed status is commonly found with words that express grammatical functions. It is one of the ways that morphology develops historically. As a historical matter, a clitic is likely to start out as a fully separate word, and then "weaken" so as to merge phonologically with its hosts. In many cases, inflectional affixes may have been clitics at an earlier historical stage, and then lost their syntactic independence.
[A book that used to be the course text for LING001 lists the English possessive 's as an inflectional affix, and last year's version of these lecture notes followed the text in this regard. This is an easy mistake to make: in most languages with possessive morphemes, they behave like inflections, and it's natural to think of 's as analogous to (say) the Latin genitive case. Nevertheless, it's clear that English possessive 's is a clitic and not an inflectional affix.]
Words nevertheless useful
Important distinctions are often difficult to define for cases near the boundary. This is among the reasons that we have lawyers and courts. The relative difficulty of making a distinction is not a strong argument, one way or the other, for the value of that distinction: it's not always easy, for example, to distinguish homicide from other (and less serious) kinds of involvement in someone's death. Despite the difficulties of distinguishing word from phrase on one side and from morpheme on the other, most linguists find the concept of word useful and even essential in analyzing most languages.
In the end, we wind up with two definitions of word: the ordinary usage, where that exists (as it does for English or Spanish, and does not for Chinese); and a technical definition, emerging from a particular theory about language structure as applied to a specific language.
Relationship between words and morphemes
What is the relationship between words and morphemes? It's a hierarchical one: a word is made up of one or more morphemes. Most commonly, these morphemes are strung together, or concatenated, in a line. However, it is not uncommon to find non-concatenative morphemes. Thus the Arabic root /ktb/ "write" has (among many other forms)
| katab | pefective active |
| kutib | perfective passive |
| aktub | imperfective active |
| uktab | imperfective passive |
The three consonants of the root are not simply concatenated with other morphemes meaning things like "imperfective" or "passive", but rather are shuffled among the vowels and syllable positions that define the various forms. Still, a given word is still made up of a set of morphemes, it's just that the set is not combined by simple concatenation in all cases.
Simpler examples of non-concatenative morphology include infixes, like the insertion of emphatic words in English cases like "un-frigging-believable", or Tagalog
| bili | 'buy' | binili | 'bought' |
| basa | 'read' | binasa | 'read' (past) |
| sulat | 'write' | sinulat | 'wrote' |
Categories and subcategories of words and morphemes
The different types of words are variously called parts of speech, word classes, or lexical categories. The Cambridge Encyclopedia of Language gives this list of 8 for English:
noun
pronoun
verb
adjective
adverb
conjunction
preposition
interjection
This set might be further subdivided: here is a list of 36 part-of-speech tags used in the Penn TreeBank project. Most of the increase (from 8 to 36) is by subdivision (e.g. "noun" divided into "singular common noun," "plural common noun," "singular proper noun," "plural proper noun," etc., but there are a few extra odds and ends, such as "cardinal number."
Other descriptions of English have used slightly different ways of dividing the pie, but it is generally easy to see how one scheme translates into another. Looking across languages, we can see somewhat greater differences. For instance, some languages don't really distinguish between verbs and adjectives. In such languages, we can think of adjectives as a kind of verb: "the grass greens," rather than "the grass is green." Other differences reflect different structural choices. For instance, English words like in, on, under, with are called prepositions, and this name makes sense given that they precede the noun phrase they introduce: with a stick. In many languages, the words that correspond to English prepositions follow their noun phrase rather than preceding it, and are thus more properly called postpositions, as in the following Hindi example:
Ram cari-se kutte-ko mara
Ram stick-with dog hit
"Ram hit the dog with an stick."
Types of morphemes:
Bound Morphemes: cannot occur on their own, e.g. de- in detoxify, -tion in creation, -s in dogs, cran- in cranberry.
Free Morphemes: can occur as separate words, e.g. car, yes.
In a morphologically complex word -- a word composed of more than one morpheme -- one constituent may be considered as the basic one, the core of the form, with the others treated as being added on. The basic or core morpheme in such cases is referred to as the stem, root, or base, while the add-ons are affixes. Affixes that precede the stem are of course prefixes, while those that follow the stem are suffixes. Thus in rearranged, re- is a prefix, arrange is a stem, and -d is a suffix. Morphemes can also be infixes, which are inserted within another form. English doesn't really have any infixes, except perhaps for certain expletives in expressions like un-effing-believable or Kalama-effing-zoo.
Prefixes and suffixes are almost always bound, but what about the stems? Are they always free? In English, some stems that occur with negative prefixes are not free, such as -kempt and -sheveled. Bad jokes about some of these missing bound morphemes have become so frequent that they may re-enter common usage.
Morphemes can also be divided into the two categories of content and function morphemes, a distinction that is conceptually distinct from the free-bound distinction but that partially overlaps with it in practice.
The idea behind this distinction is that some morphemes express some general sort of referential or informational content, in a way that is as independent as possible of the grammatical system of a particular language -- while other morphemes are heavily tied to a grammatical function, expressing syntactic relationships between units in a sentence, or obligatorily-marked categories such as number or tense.
Thus (the stems of) nouns, verbs, adjectives are typically content morphemes: "throw," "green," "Kim," and "sand" are all English content morphemes. Content morphemes are also often called open-class morphemes, because they belong to categories that are open to the invention of arbitrary new items. People are always making up or borrowing new morphemes in these categories.: "smurf," "nuke," "byte," "grok."
By contrast, prepositions ("to", "by"), articles ("the", "a"), pronouns ("she", "his"), and conjunctions are typically function morphemes, since they either serve to tie elements together grammatically ("hit by a truck," "Kim and Leslie," "Lee saw his dog"), or express obligatory (in a given language!) morphological features like definiteness ("she found a table" or "she found the table" but not "*she found table"). Function morphemes are also called "closed-class" morphemes, because they belong to categories that are essentially closed to invention or borrowing -- it is very difficult to add a new preposition, article or pronoun.
For years, some people have tried to introduce non-gendered pronouns into English, for instance "sie" (meaning either "he" or "she", but not "it"). This is much harder to do than to get people to adopt a new noun or verb.
Try making up a new article. For instance, we could try to borrow from the Manding languages an article (written "le") that means something like "I'm focusing on this phrase as opposed to anything else I could have mentioned." We'll just slip in this new article after the definite or indefinite "the" or "a" -- that's where it goes in Manding, though the rest of the order is completely different. Thus we would say "Kim bought an apple at the-le fruit stand," meaning "it's the fruit stand (as opposed to anyplace else) where Kim bought an apple;" or "Kim bought an-le apple at the fruit stand," meaning "it's an apple (as opposed to any other kind of fruit) that Kim bought at the fruit stand."
This is a perfectly sensible kind of morpheme to have. Millions of West Africans use it every day. However, the chances of persuading the rest of the English-speaking community to adopt it are negligible.
In some ways the open/closed terminology is clearer than content/function,
since obviously function morphemes also always have some content!
The concept of the morpheme does not directly map onto the units of sound that represent morphemes in speech. To do this, linguists developed the concept of the allomorph. Here is the definition given in a well-known linguistic workbook:
Allomorphs: Nondistinctive realizations of a particular morpheme that have the same function and are phonetically similar. For example, the English plural morpheme can appear as [s] as in cats, [z] as in dogs, or ['z] as in churches. Each of these three pronunciations is said to be an allomorph of the same morpheme.
Inflectional vs. Derivational Morphology
Another common distinction is the one between derivational and inflectional affixes.
Derivational morphemes makes new words from old ones. Thus creation is formed from create by adding a morpheme that makes nouns out of (some) verbs.
Derivational morphemes generally
- change the part of speech or the basic meaning of a word. Thus -ment added to a verb forms a noun (judg-ment). re-activate means "activate again."
- are not required by syntactic relations outside the word. Thus un-kind combines un- and kind into a single new word, but has no particular syntactic connections outside the word -- we can say he is unkind or he is kind or they are unkind or they are kind, depending on what we mean.
- are often not productive or regular in form or meaning -- derivational morphemes can be selective about what they'll combine with, and may also have erratic effects on meaning. Thus the suffix -hood occurs with just a few nouns such as brother, neighbor, and knight, but not with most others. e.g., *friendhood, *daughterhood, or *candlehood. Furthermore "brotherhood" can mean "the state or relationship of being brothers," but "neighborhood" cannot mean "the state or relationship of being neighbors." Note however that some derivational affixes are quite regular in form and meaning, e.g. -ism.
- typically occur "inside" any inflectional affixes. Thus in governments, -ment, a derivational suffix, precedes -s, an inflectional suffix.
- in English, may appear either as prefixes or suffixes: pre-arrange, arrange-ment.
Inflectional morphemes vary (or "inflect") the form of words in order to express the grammatical features that a given language chooses, such as singular/plural or past/present tense. Thus Boy and boys, for example, are two different forms of the "same" word. In English, we must choose the singular form or the plural form; if we choose the basic form with no affix, we have chosen the singular.
Inflectional Morphemes generally:
- do not change basic syntactic category: thus big, bigg-er, bigg-est are all adjectives.
- express grammatically-required features or indicate relations between different words in the sentence. Thus in Lee love-s Kim, -s marks the 3rd person singular present form of the verb, and also relates it to the 3rd singular subject Lee.
- occur outside any derivational morphemes. Thus in ration-al-iz-ation-s the final -s is inflectional, and appears at the very end of the word, outside the derivational morphemes -al, -iz, -ation.
- In English, are suffixes only.
Some examples of English derivational and inflectional morphemes:
| derivational | inflectional |
| -ation | -s Plural |
| -ize | -ed Past |
| -ic | -ing Progressive |
| -y | -er Comparative |
| -ous | -est Superlative |
Properties of some derivational affixes in English:
| -ation | is added to a verb | to give a noun |
| finalize confirm |
finalization confirmation |
|
| un- | is added to a verb | to give a verb |
| tie wind |
untie unwind |
|
| un- | is added to an adjective | to give an adjective |
| happy wise |
unhappy unwise |
|
| -al | is added to a noun | to give an adjective |
| institution universe |
institutional universal |
|
| -ize | is added to an adjective | to give a verb |
| concrete solar |
concretize solarize |
Keep in mind that most morphemes are neither derivational nor inflectional! For instance, the English morphemes Melissa, twist, tele-, and ouch.
Also, most linguists feel that the inflectional/derivational distinction is not a fundamental or foundational question at all, but just a sometimes-useful piece of terminology whose definitions involve a somewhat complex combination of more basic properties. Therefore we will not be surprised to find cases for which the application of the distinction is unclear.
For example, the English suffix -ing has several uses that are arguably on the borderline between inflection and derivation (along with other uses that are not).
One very regular use of -ing is to indicate progressive aspect in verbs, following forms of "to be": She is going; he will be leaving; they had been asking. This use is generally considered an inflectional suffix, part of the system for marking tense and aspect in English verbs.
Another, closely related use is to make present participles of verbs, which are used like adjectives: Falling water; stinking mess; glowing embers. According to the rule that inflection doesn't change the lexical category, this should be a form of morphological derivation, since it changes verbs to adjectives. But in fact it is probably the same process, at least historically as is involved in marking progressive aspect on verbs, since "being in the process of doing X" is one of the natural meanings of the adjectival form X-ing.
There is another, regular use of -ing to make verbal nouns: Flying can be dangerous; losing is painful. The -ing forms in these cases are often called gerunds. By the "changes lexical categories" rule, this should also be a derivational affix, since it turns a verb into a noun. However, many people feel that such cases are determined by grammatical context, so that a phrase like Kim peeking around the corner surprised me actually is related to, or derived from, a tenseless form of the sentence Kim peeked around the corner. On this view, the affix -ing is a kind of inflection, since it creates a form of the verb appropriate for a particular grammatical situation, rather than making a new, independent word. Thus the decision about whether -ing is an inflection in this case depends on your analysis of the syntactic relationships involved.
It's for reasons like this that the distinction between inflectional and derivational affixes is just a sometimes-convenient descriptive one, and not a basic distinction in theory.
What is the meaning of an affix?
The meanings of derivational affixes are sometimes clear, but often are obscured by changes that occur over time. The following two sets of examples show that the prefix un- is easily interpreted as "not" when applied to adjectives, and as a reversing action when applied to verbs, but the prefix con- is more opaque.
| un- | untie |
| unshackle | |
| unharness | |
| unhappy | |
| untimely | |
| unthinkable | |
| unmentionable |
| con- | constitution |
| confess | |
| connect | |
| contract | |
| contend | |
| conspire | |
| complete |
Are derivational affixes sensitive to the historical source of the roots they attach to?
Although English is a Germanic language, and most of its basic vocabulary derives from Old English, there is also a sizeable vocabulary that derives from Romance (Latin and French). Some English affixes, such as re-, attach freely to vocabulary from both sources. Other affixes, such as "-ation", are more limited.
| ROOT | tie | consider |
| free form | free form | |
| Germanic root | Latinate root | |
| SOURCE | Old English tygan, "to tie" | Latin considerare, "to examine" |
| PREFIX | retie | reconsider |
| SUFFIX | reties | reconsiders |
| retying | reconsideration | |
| retyings | reconsiderations |
The suffix -ize, which some prescriptivists object to in words like hospitalize, has a long and venerable history.
According to Hans Marchand, in The Categories and Types of Present-Day English Word Formation (University of Alabama Press, 1969), the suffix -ize comes originally from the Greek -izo. Many words ending with this suffix passed from Ecclesiastical Greek into Latin, where, by the fourth century, they had become established as verbs with the ending -izare, such as barbarizare, catechizare, christianizare. In Old French we find many such verbs, belonging primarily to the ecclesistical sphere: baptiser (11th c.), canoniser (13th c.), exorciser (14th c.).
The first -ize words to be found in English are loans with both a French and Latin pattern such as baptize (1297), catechize, and organize (both 15th c.) Towards the end of the 16th century, however, we come across many new formations in English, such as bastardize, equalize, popularize, and womanize. The formal and semantic patterns were the same as those from the borrowed French and Latin forms, but owing to the renewed study of Greek, the educated had become more familiar with its vocabulary and used the patterns of Old Greek word formation freely.
Between 1580 and 1700, the disciplines of literature, medicine, natural science and theology introduced a great deal of new terminology into the language. Some of the terms still in use today include criticize, fertilize, humanize, naturalize, satirize, sterilize, and symbolize. The growth of science contributed vast numbers of -ize formations through the 19th century and into the 20th.
The -ize words collected by students in in this class six years ago show that -ize is almost entirely restricted to Romance vocabulary, the only exceptions we found being womanize and winterize. Even though most contemporary English speakers are not consciously aware of which words in their vocabulary are from which source, they have respected this distinction in coining new words.
Constituent Structure of Words
The constituent morphemes of a word can be organized into a branching or hierarchical structure, sometimes called a tree structure. Consider the word unusable. It contains three morphemes:
- prefix "un-"
- verb stem "use"
- suffix "-able"
What is the structure? Is it first "use" + "-able" to make "usable", then combined with "un-" to make "unusable"? or is it first "un-" + "use" to make "unuse", then combined with "-able" to make "unusable"? Since "unuse" doesn't exist in English, while "usable" does, we prefer the first structure, which corresponds to the tree shown below.
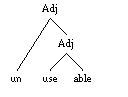
This analysis is supported by the general behavior of these affixes. There is a prefix "un-" that attaches to adjectives to make adjectives with a negative meaning ("unhurt", "untrue", "unhandy", etc.). And there is a suffix "-able" that attaches to verbs and forms adjectives ("believable", "fixable", "readable"). This gives us the analysis pictured above. There is no way to combine a prefix "un-" directly with the verb "use", so the other logically-possible structure won't work.
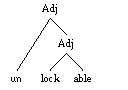
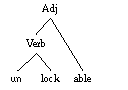
Now let's consider the word "unlockable". This also consists of three morphemes:
- prefix "un-"
- verb stem "lock"
- suffix "-able"
This time, though, a little thought shows us that there are two different meanings for this word: one corresponding to the left-hand figure, meaning "not lockable," and a second one corresponding to the right-hand figure, meaning "able to be unlocked."
In fact, un- can indeed attach to (some) verbs: untie, unbutton, uncover, uncage, unwrap... Larry Horn (1988) points out that the verbs that permit prefixation with un- are those that effect a change in state in some object, the form with un- denoting the undoing (!)of that change.
This lets us account for the two senses of "unlockable".. We can combine the suffix -able with the verb lock to form an adjective lockable, and then combine the prefix un- with lockable to make a new adjective unlockable, meaning "not able to be locked". Or we can combine the prefix un- with the verb lock to form a new verb unlock, and the combine the suffix -able with unlock to form an adjective unlockable, meaning "able to be unlocked".
By making explicit the different possible hierarchies for a single word, we can better understand why its meaning might be ambiguous.
Morphology FAQ
These questions and answers are based on some patterns of error observed in homeworks and exams in previous years.
Can a word = a morpheme?
Yes, at least in the sense that a word may contain exactly one morpheme:
| Word (=Morpheme) | Word Class |
| car | noun |
| thank | verb |
| true | adjective |
| succotash | noun |
| gosh | interjection |
| under | preposition |
| she | pronoun |
| so | conjunction |
| often | adverb |
Are there morphemes that are not words?
Yes, none of the following morphemes is a word:
| Morpheme | Category |
| un- | prefix |
| dis- | prefix |
| -ness | suffix |
| -s | suffix |
| kempt (as in unkempt) |
bound morpheme |
Can a word = a syllable?
Yes, at least in the sense that a word may consist of exactly one syllable:
| Word | Word Class |
| car | noun |
| work | verb |
| in | preposition |
| whoops | interjection |
Are there morphemes that are not syllables?
Yes, some of the following morphemes consist of more than one syllable; some of them are less than a syllable:
| Morpheme | Word Class |
| under | preposition (> syll.) |
| spider | noun (> syll.) |
| -s | 'plural' (< syll.) |
Are there syllables that are not morphemes?
Yes, many syllables are "less" than morphemes. Just because you can break a word into two or more syllables does not mean it must consist of more than one morpheme!
| Word | Syllables | Comments |
| kayak | (ka.yak) | neither ka nor yak is a morpheme |
| broccoli | (bro.ko.li) or (brok.li) | neither bro nor brok nor ko nor li is a morpheme |
| angle | (ang.gle) | neither ang nor gle is a morpheme |
| jungle | (jung.gle) | neither jung nor gle is a morpheme |
So (if you were wondering -- and yes, some people have trouble with this) there is no necessary relationship between syllables, morphemes, and words. Each is an independent unit of structure.
What are the major differences between derivational and inflectional affixes?
First, it's worth saying that most linguists today consider this distinction as a piece of convenient descriptive terminology, without any fundamental theoretical status. Then we can point to the basic meanings of the terms: derivational affixes "derive" new words from old ones, while inflectional affixes "inflect" words for certain grammatical or semantic properties.
| derivational | inflectional | |
| position | closer to stem | further from stem |
| addable on to? | yes | not in English |
| meaning? | (often) unpredictable | predictable |
| changes word class? | maybe | no |
Are clitics inflectional or derivational morphemes?
The answer would depend on your definitions -- and as we explained earlier, the categories of "inflection" and "derivation" are descriptive terms that really don't have a strong theoretical basis. However, based on comparison to typical examples of inflectional and derivational affixes, the answer seems to be "neither", in that clitics are not really lexical affixes at all.