The vowel categories
English has an unusually rich and complex vowel system, and a great deal of variation in vowel pronunciation across dialects. Standard English spelling does not identify pronunciations clearly or reliably, as poems like this one indicate. Therefore, the easiest way to start is with a list of vowel categories or equivalence classes, each represented by a set of words whose vowels are all pronounced alike. For each vowel category, we'll pick a single word as a convenient way to name the class. This doesn't tell us how the words in each vowel class are pronounced -- and of course the pronunciation varies across dialects. Different dialects also differ in how many distinctions they make. Therefore each phonological equivalence class tells us only that the vowels in it behave the same way.
Across English dialects, we need something like 24 "lexical sets" to do the job. This particular classification comes from J. C. Wells' Accents of English:
| Number | Name | Other Examples | Number | Name | Other Examples |
| 1 | KIT | ship, rib, dim | 13 | THOUGHT | Waugh, hawk, broad |
| 2 | DRESS | step, ebb, hem | 14 | GOAT | soap, robe, home |
| 3 | TRAP | bad, cab, ham | 15 | GOOSE | loop, mood, boom |
| 4 | LOT | stop, odd, Tom | 16 | PRICE | ripe, tribe, time |
| 5 | STRUT | cup, rub, hum | 17 | CHOICE | boy, void, coin |
| 6 | FOOT | bush, look, good | 18 | MOUTH | pouch, loud, noun |
| 7 | BATH | staff, clasp, dance | 19 | NEAR | beer, weird, fierce |
| 8 | CLOTH | cough, long, gone | 20 | SQUARE | care, air, wear |
| 9 | NURSE | curb, turn, work | 21 | START | far, sharp, farm |
| 10 | FLEECE | reap, seed, seize | 22 | NORTH | for, York, storm |
| 11 | FACE | late, babe, name | 23 | FORCE | ore, floor, coarse |
| 12 | PALM | bra, Brahms, blah | 24 | CURE | boor, tour, gourd |
Because of splits and mergers, any particular choice of sets is likely to make some distinctions that are unnecessary for a given dialect, and also to fail to make some other useful distinctions.
For example, very few American dialects distinguish the TRAP and BATH sets -- though many British dialects do. The NORTH and FORCE sets have merged for most speakers on both sides of the Atlantic, though a few dialects still distinguish them at least in part. You can see if they have merged for you by asking whether "for" and "four" are pronounced the same, or "horse" and "hoarse". There are some people for whom they are different!
In the Philadelphia area, the TRAP set (whose vowel is sometimes called "short a") has split into two. According to Labov 1989:
Short a is tense in closed syllables before nasals (man, fan, stand, Dan, etc.) with the exception of irregular verbs (ran, swam, began) and tense before voiceless fricatives (pass, fast, path, laugh, etc.) but lax in all open syllables (hammer, passage) unless the second syllable is an inflectional suffix where the vowel is tense (passing, laughing), and tense before /d/ in three words mad, bad, glad but lax in all other words before /d/ and lax before learned words like alas and wrath.
Thus to cover Philadelphia pronunciation properly, we'd have to split
Wells' TRAP set into two. We could call one the MAD set (man, pass, mad,
etc.) -- the cases that Labov describes as "tense" -- and the
other the TRAP set -- the residual cases that Labov describes as "lax".
So far you have no basis for knowing what these terms refer to, but you
can conclude that for Philadelphia speakers, the vowels of words in the
MAD set are similar to one another, and different from the vowels of words
in the TRAP set.
[In fact the "tense" vowels are higher and fronter
in the IPA chart given below].
The idea of naming an English vowel type by referring to a set of example words is a helpful one. As we've indicated, though, this doesn't tell us anything about how a vowel category is actually pronounced. One way to indicate actual pronunciation is to give some audio examples. This is useful, but often we want to say something more systematic about the nature of vowel pronunciations, their relationships, how they are changing, etc. For this, use of the IPA vowel chart is helpful. The full chart is given below.
It represents a sort of three-dimensional space:
- degree of opening of the vocal tract runs from top to bottom;
- fronter vs. backer position of the tongue runs from left to right;
- spread vs. rounded lips is indicated by pairs of symbols at a given place in the chart.

You can learn more about the acoustic value of points in this vowel space by downloading the IPA Help program from SIL's web site.
In terms of IPA vowel symbols, we can give the nominal pronunciation of the vowels in Wells' lexical sets as follows, for the varieties of British and American speech that we might hear from a news reader in a national broadcast:
| British | American | Keyword | British | American | Keyword | ||
| 1 |
|
|
KIT | 13 |
|
|
THOUGHT |
| 2 |
|
|
DRESS | 14 |
|
|
GOAT |
| 3 |
|
|
TRAP | 15 |
|
|
GOOSE |
| 4 |
|
|
LOT | 16 |
|
|
PRICE |
| 5 |
|
|
STRUT | 17 |
|
|
CHOICE |
| 6 |
|
|
FOOT | 18 |
|
|
MOUTH |
| 7 |
|
|
BATH | 19 |
|
|
NEAR |
| 8 |
|
|
CLOTH | 20 |
|
|
SQUARE |
| 9 |
|
|
NURSE | 21 |
|
|
START |
| 10 |
|
|
FLEECE | 22 |
|
|
NORTH |
| 11 |
|
|
FACE | 23 |
|
|
FORCE |
| 12 |
|
|
PALM | 24 |
|
|
CURE |
Note that the colon-like character indicates extra length of the preceding sound, while a sequence of two characters indicates a sound that starts one way and ends another.
This presentation leaves out a great deal of variation in pronunciation. Some of this variation just chances the sound quality of certain words without changing any lexical class definitions. For example, some American have a relatively front vowel in the LOT class (for instance, people from the Chicago area), while others have a much backer vowel.The category covers the same set of words, but is just pronounced differently. In other cases, particular words or classes or words move from one class to another. For example, some Americans pronounce the vowel in "king", "sing", "bring" like the vowel in KIT or the vowel in FLEECE. Finally, there are many splits and mergers. Nearly all Americans merge the CLOTH and THOUGHT classes, and also merge the LOT and PALM classes; a large proportion of Americans also merge all four of these classes into one. Some mergers depend on the context -- additional mergers of vowel categories before /r/ and /l/ are especially common. Some people pronounce "Mary", "marry" and "merry" differently (with the vowels of the FACE, TRAP and DRESS classes, respectively) while others merge them -- without of course merging examples like "mate", "mat", "met" that don't involve a following /r/.
There are some annoying aspects of the IPA character set as it applies to English, which we will modify for the rest of this discussion. Basically we'll use the regular a in place of the upside-down a, and the regular r in place of the upside-down r. You should do the same in your homework.
- The IPA assigns the normal printed a character to a low front
vowel which is hardly ever found, and assigns the upside-down a
(or "turned a ") character
 to the very common open central vowel, such as the vowel in American
English "pot". It will be a lot easier to read and write IPA
descriptions of English if we just take the regular lower-case a
to be the American "pot" vowel.
to the very common open central vowel, such as the vowel in American
English "pot". It will be a lot easier to read and write IPA
descriptions of English if we just take the regular lower-case a
to be the American "pot" vowel. - The IPA assigns the upside-down r character ("turned r")
 to the particular kind
of "bunched-tongue r" used by most speakers of American English,
while reserving the ordinary r for the "trilled r"
as found in Spanish (and many other languages). Since the trilled r
is not found in American English, it's again easier to read and write
if we use the standard r symbol.
to the particular kind
of "bunched-tongue r" used by most speakers of American English,
while reserving the ordinary r for the "trilled r"
as found in Spanish (and many other languages). Since the trilled r
is not found in American English, it's again easier to read and write
if we use the standard r symbol.
Given these changes, then the relevant lexical sets for "standard" American vowels become something like this:
|
IPA
|
Name
|
IPA
|
Name
|
||
| 1 |
|
KIT | 14 | GOAT | |
| 2 |
|
DRESS | 15 | GOOSE | |
| 3 & 7 |
|
TRAP & BATH | 16 | PRICE | |
| 4 & 12 |
|
LOT & PALM | 17 | CHOICE | |
| 5 |
|
STRUT | 18 | MOUTH | |
| 6 |
|
FOOT | 19 | NEAR | |
| 8 & 13 |
|
CLOTH & THOUGHT | 20 | SQUARE | |
| 9 |
|
NURSE | 21 | START | |
| 10 |
|
FLEECE | 22 & 23 | NORTH & FORCE | |
| 11 |
|
FACE | 24 | CURE |
The consonant categories
The full set of basic IPA consonant categories is shown in the table below:
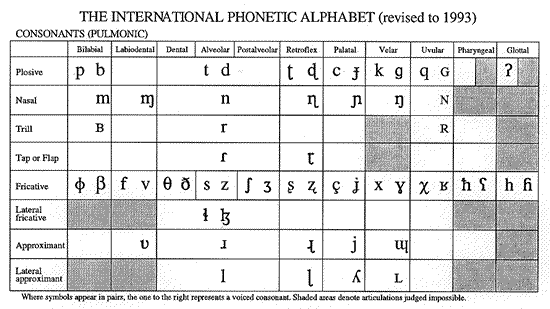
The subset of 22 IPA symbols relevant to English dictionary-style pronunciations is given below:

Of these, some have basically their normal value in English spelling: p, b, t, d, k, g, m, n, f, v, s, z, l.
The "right-tailed n" ![]() is
the velar nasal sound at the end of "hang" or "ring".
is
the velar nasal sound at the end of "hang" or "ring".
The alveolar tap "fishhook" ![]() is the sound that spelled "t" or "d" becomes (for
most American speakers) in "Peter" or "ladder" or
"at all".
is the sound that spelled "t" or "d" becomes (for
most American speakers) in "Peter" or "ladder" or
"at all".
The interdental fricatives "theta" ![]() and "eth"
and "eth" ![]() are the sounds at the start of "thin" and "this" respectively.
are the sounds at the start of "thin" and "this" respectively.
The palatal fricatives "esh" ![]() and "yogh"
and "yogh" ![]() are
the sounds in the middle of "ashen" and "azure" respectively.
are
the sounds in the middle of "ashen" and "azure" respectively.
The palatal approximant j is essentially the consonant spelled 'y' in English, as in "yield" or "yes".
In addition to the consonants in this table, you will need a few other things:
- The consonant w, as in "will" or "wallaby" -- due to a peculiarity of IPA classification, it does not appear in the main consonant table.
- To make "affricates" such as the initial sounds in "chunk"
or "jest", you need to combine a stop and a fricative. For
English, there are two cases:
- the voiceless palatal affricate (like the start of "chip")
which in IPA is written

- the voiced palatal affricate (like the start of "jut")
which in IPA is written

- the voiceless palatal affricate (like the start of "chip")
which in IPA is written
- Stress is marked before the affected syllable; primary stress is marked
by a raised vertical line, while secondary stress is marked by a lowered
vertical line. Thus "California" is written

Writing IPA with ASCII
For the vowels, given the obvious correspondences [a], [e], [i], [o], [u], the following IPA subset should be sufficient:
| IPA Character | Description | ASCII |
|
|
script a |
A
|
|
|
ash (ae ligature) |
{
|
|
|
turned a |
6
|
|
|
turned script a |
Q
|
|
|
epsilon |
E
|
|
|
schwa |
@
|
|
|
reversed epsilon |
3
|
|
|
small capital i |
I
|
|
|
open o |
O
|
|
|
slashed o |
2
|
|
|
oe ligature |
9
|
|
|
capital oe ligature |
&
|
|
|
upsilon |
U
|
|
|
barred u |
}
|
|
|
wedge |
V
|
|
|
small capital y |
Y
|
For the consonants, given the obvious correspondences [p] [t] [k] [b] [d] [g] [m] [n] [s] [f] [v] [l] [r] [j] [w] [h], the following should suffice:
| |
eth | D |
|
|
left-tail n | J |
| eng (right-tail n) | N | |
| esh | S | |
| theta | T | |
| ezh (yogh) | Z | |
| glottal stop | ? |
For main stress, use double quote marks ("), and for secondary stress, use percentage sign (%).
Some IPA fonts can be downloaded from here. If you want more detail on the use of ordinary "ascii" characters to represent IPA symbols, consult this reference.
Several chapters of a definitive work-in-progress on regional variation in the pronunciation of North American English can be found here.