Draft
May 26, 1998
A low level of reading achievement in the inner city has been recognized for
more than three decades. What is remarkable is the stability of the problem, in
the face of many large scale efforts at remediation. The over-all view of the
situation is best provided by the NAEP data, reporting average reading
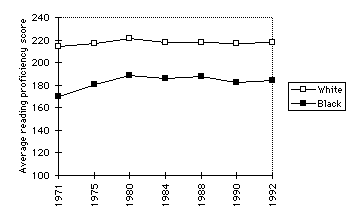
proficiency scores by race/ethnicity. Figure 1 shows the figures for 9 year
olds, the age group closest to those we are concerned with. The figure shows
that despite a slight improvement from 1971 to 1980, both black and white
scores and the black/white differential are essentially stable from 1980. The
interpretation of this difference in average scores is important here: Score
level 200 is required for "partial skills and undersetanding," and the black
average has not reached that level, while the whites are past that level on the
way to score level 250, which "Interrelates ideas and makes generalizations."
On the whole, the average reading proficiency of the black 9 year olds through
1992 was at the level of "simple discrete reading tasks."
Figure 1. NAEP average reading proficiency scores by race for 9 year olds,
1971-1992
The Extended Day Program gave the 40 elementary students involved a great deal
of individual attention. Children engaged in many activities with the Penn
students, volunteers from West Philadelphia High School and Woodruff staff. The
most systematic tutoring in reading was done by the Woodruff staff and Penn
students. The researchers who obtained the data in this report selected
illustrated books from a wide range that had been determined to be at the
students' grade level.[2] Children read the
texts aloud; when there were errors or difficulties, tutors supplied the word
only when the child had made several wrong efforts, paused for at least five
seconds, or indicated that they had no idea what the word was.
Two types of data were recorded: words where no effort was made to pronounce a
guess or a version, and words that were read aloud in a form that could not be
interpreted as corresponding to the sense intended in the text. Throughout this
proceeding we distinguished carefully between differences in pronunciation and
mistakes in reading (Labov 1965, Goodman 1969). It has been well established
that speakers of AAVE frequently do not pronounce the second element of apical
consonant clusters (in past, passed, etc.), although there is good
evidence that these clusters are intact in their underlying mental
dictionaries.[3] When students read words like
worked as work, this was not rated as a mistake in reading unless
there was clear evidence that they had failed to grasp the past tense
meaning.
The main body of findings to follow is the result of the analysis of the
second type of data, where readers gave some version of the word aloud. These
data permit us to locate the source of the reading difficulty more precisely
than the simple inability to read the word. However, an examination of the
words that were not read at all is consistent with the findings of the analysis
of attempted reading errors. A total of 450 reading errors from 20 children
form the body of data to be examined in the sections that follow.
Our first contact with the reading problems of second and third grade children
showed that they suffered a high level of frustration in attempting to read the
books that were designed for 2nd and 3rd grade readers. One might point to many
of the sources of reading problems identified in the literature: a lack of
familiarity with the vocabulary or the subject matter, poor strategies for
deducing the meanings of unfamiliar words from context, lack of attention to
the main ideas, and so on. However, the first priority was given to the
analysis of their ability to use sound/letter correspondences to identify words
that are included in their speaking and hearing competence. A great deal of
recent discussion of children's decoding abilities has focused on predictors of
success or failure in reading, and the development of phonemic or phonological
awareness has played a major role (NRC 1998: 110-112). Our focus is not on
prediction but upon the actual description of children's ability to use the
regularities of grapheme-to-phoneme correspondence to identify words. In this
respect, we continue the tradition of Calfee and Venezky (1968) who examined
children's abilities to decode specific alphabetic elements and relations; we
extend this approach to the reading of inner city African American children. We
have reason to believe that there are specific weaknesses in this population's
grapheme-to-phoneme processing. Earlier studies of the reading errors of AAVE
speaking youth indicated that the alphabet was used consistently for the first
consonant and vowel, but that it was frequently ignored for the following
material (Labov, Cohen, Robins and Lewis 1968).
If it should turn out that there were little relationship between the
frequency of errors and the phonemic structure of words, one would conclude
that weakness in decoding skills was not an important part of the causes of
reading failure, and turn to other aspects of reading. But if there is a high
correlation between frequency of reading errors and the complexity of the word
and syllable, we can conclude that there is a great deal to gain by reinforcing
children's knowledge of these relations.
The analysis must necessarily combine graphic and phonemic relations. Our
first question on any letter is whether the reader paid attention to it and
recognized it for what it is. The second question is whether it was interpreted
properly as an individual phoneme, as a part of a digraph indicating an
individual phoneme, or as a part of a cluster of phonemes which function
jointly as the onset, nucleus, and coda of the syllable.[4] A third question is whether it was combined with other
elements to produce a recognizable version of the intended word.
This analysis of reading errors is consistent with findings from studies of
children's abilities to use sound/letter correspondences in reading nonsense
words (Venezky 1972; Venezky and Johnson 1972; Calfee, Venezky and Chapman
1972). However, the pronunciation of nonsense words introduces factors which
underestimate the actual reading competence of children, since rules of
sound/letter correspondence are not equally productive, and the role of
exceptions in weakening the person's confidence in the validity of rules is not
yet understood. The study of meaningful reading in context has the advantage of
eliminating the artifactual nature of nonsense words. Yet it introduces the
opposing problem of overestimating decoding skills by mixing the process of
decoding with the recognition of sight words. By focusing on the distribution
of letter/sound correspondences in reading errors, where sight words are least
likely to appear, we should come closer to a valid estimate of decoding skills.
Table 2 and Figure 4 show the distribution of reading errors for the onsets of
the first syllable--all of the consonants that precede the first vowel.
Table 2 and Figure 4. Distribution of reading errors for onsets of first
syllables.
N |
Total |
Percent errors |
Inverse |
L/R transfer |
R/L transfer | ||
First consonant |
414 |
17 |
4 |
0 |
0 |
0 | |
Soft c |
20 |
5 |
25 |
1 |
1 |
0 | |
Digraph |
42 |
14 |
33 |
3 |
0 |
0 | |
sC cluster |
39 |
14 |
36 |
3 |
0 |
2 | |
Cr/l cluster |
93 |
32 |
34 |
5 |
9 |
3 | |
sCr cluster |
9 |
7 |
78 |
0 |
0 |
3 | |

Perhaps the most important finding of this study is shown in the first column
on the left: errors in reading the initial consonant. This measure indicates
whether or not the reader accurately detected what letter was present, but not
the application of contextual rules of sound/letter correspondences. For
example, the word ceiling was read as "killing," showing a failure to
apply the rule that c is pronounced as /s/ before a front vowel e
or i. However, it was recognized as c. The percent of errors
is very low: 3%. The 17 errors include four which indicate problems in spatial
location rather than identification of letters: the familiar reversal was
for saw, yes for eyes, and two misreadings of them
which began with m.
Thus it is clear that the children's reading problems are not the result of
children's failure to learn values of the letters of the alphabet. Consistent
with earlier studies of Harlem adolescents (Labov et al. 1968), we do not find
2nd and 3rd graders in West Philadelphia who fail to use the alphabet
accurately for the initial consonant. A comparison can be made with a study
which used the standard methodology of testing children's ability to give
plausible readings of nonsense words: the Wisconsin study of Venezky, Chapman
and Calfee (as cited in Venezky 1972). The West Philadelphia reading of lone
initial consonants is comparable to the decoding skills of the highest quartile
of Wisconsin children tested at the end of grade 2. For the recognition of the
invariant consonants m, d, l, b, the range was 97 to 99% correct in
initial position. Since our measure looks only at words that were read
incorrectly, the actual rate of success in reading all m,d,l,b would be
much greater; yet for the 75 words in our list beginning with these consonants,
the West Philadelphians made only one error in the initial consonant. The West
Philadelphia children are far superior to the Wisconsin lowest quartile, whose
error rates were close to 10% for all four consonants.[5]
This situation contrasts sharply with error patterns for any words in which
the onset has more than a single consonant. The third row of Table 2 and third
column of Figure 4 shows reading errors associated with initial digraphs. The
list of errors includes not only cases of digraphs read as a single grapheme
(scenes -> sense, thump -> jump, their -> her, three ->
tree), and as another digraph (that -> what), but there were also
inverse errors, where a phoneme corresponding to a digraph was used when only a
single consonant was printed (tank -> think, trout -> throat,
suggested -> shoulder). Such inverse errors are shown as black bars in
the error column for all items in Figure 2 and figures to follow.
The column labeled sC- cluster designates all words that have consonant
clusters or "blends" beginning with s-. Here we find an
additional type of error--readings in which the second element of the cluster
is transferred to the right, on the other side of the vowel nucleus. Thus we
have stall -> /sæt´l/ steel -> settle, strong ->
short. There are also reverse, right-to-left locational errors, with a
segment moving from the coda of the syllable to the onset, as in settling
-> stealing.
The next category, Cr/l clusters, involves onset clusters where the
second consonant is a grapheme indicating a liquid phoneme-- an /r/ or an /l/.
The first consonant is a grapheme corresponding to an obstruent:
phoneme: that is, either a stop (p,t,k,b,d,g) or a fricative
(f,s).[6], Errors with clusters of
this type are more numerous and show the same pattern. In addition to the loss
of the second grapheme (dragons -> danger, crops -> coops, shrubs
-> shubs, drawn -> down), there are frequent re-assignments of the
second element to the syllable coda, as in cloud -> cold, tried ->
tired, friendly -> fire, slimy -> smelly). In some cases, an element
of the coda is moved into the onset: dirtying -> drying, peddlars ->
platters, fell -> flew). There are also a good share of inverse errors,
where a single consonant is read as a cluster: tack -> track, double
-> trouble.
The distribution of errors among the various types of complex onsets is
remarkably stable, close to 35%. In the smaller subset of words with
three-member onsets, the combination of sC- and Cr- problems is
uniformly responsible for errors: strong -> short, screamed -> scare,
struggle -> /s/. The fact that the spatial location of the second
segment is uncertain is not surprising. Thus Adams (1990) notes:
Although the visual system is quite fast and accurate at processing item
information (such as the identities of the individual letters of a word), it is
both slow and sloppy about processing their spatial locations. --113.
Adams found (1979) that a major difference between less skilled and more
skilled readers was in their ability to view and report ordered pairs of
letters, particularly in their sensitivity to the frequency with which a pair
of consonants occurred in printed English.
In our data, the contrast between simple and complex onsets is almost
categorical: when words are read wrong, it is rare to find that a lone initial
consonant is involved; but if a complex onset was present in the word, it is
very likely responsible for the error. The pedagogical implications of this
fact will be developed in section 8.
The view of reading errors for the vowel nucleus shows a much higher level of
errors than the onset. By far the lowest value is shown in the column for the
first vowel. In the majority of the reading errors, the first vowel was
recognized for what it is; yet the percent of errors is seven times as great as
for the first consonant.
One might attribute this higher rate for the first vowel to the fact that it
is not as salient in the word, but comes after an initial consonant. However,
when we compare in the next row the error rate for words read wrongly with
initial vowels, it is 22%, not far behind the overall rate of 29% for the first
vowel, and much greater than the 4% for the first consonant: uses ->
sees, united -> /´nayt´d/, over -> /Uv´r/, even ->
any, etc.
Table 3 and Figure 5. Distribution of reading errors for the vowel nucleus.
N |
Total |
Percent errors |
Inverse |
Exceptions | ||
First vowel |
436 |
128 |
29 |
0 |
0 | |
Initial vowel |
36 |
8 |
22 |
0 |
0 | |
Silent e |
61 |
55 |
90 |
8 |
3 | |
Double vowel |
118 |
70 |
59 |
8 |
7 | |
r-controlled vowel |
55 |
39 |
71 |
18 |
0 | |
Bisyllabic shortening |
27 |
36 |
75 |
1 |
1 | |
Unstressed vowel |
127 |
97 |
76 |
5 |
0 |
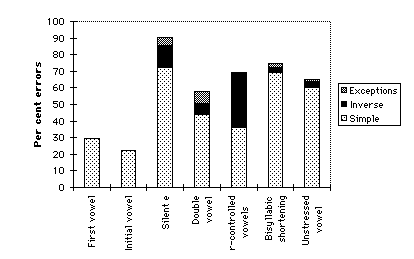
Complications in the nucleus are responsible for a much higher rate of the
reading errors than complications in the consonantal onset; the rates in Figure
3 are all well above 50%. The first of these columns shows the distribution of
errors for words containing the "silent e" pattern, that is, a final
orthographic e in the second syllable after a lone consonant. Of all
regularities in English vowel system, this is one of the most reliable. It
consists of two parts:
(1) An e after a lone consonant is not pronounced. (Only exceptions:
Nike, adobe).
(2) The vowel of the first syllable has its appropriate long sound.
(Exceptions: (a) have, give, live; (b) love, glove, shove, hover,
oven, above, cover, dove; (c) move, prove.
The exceptions to the second part of this rule are heavily concentrated in the
specific environment of -ov-[7]
and there are a vast number of words which follow the pattern regularly.
Nevertheless, the West Philadelphia students have plainly not mastered the
silent e rule. We observe a large number of simple errors. Some are
simply a preservation of the short sound of the vowel in defiance of the silent
e: plane -> plan, globes -> globs, aside -> acid, ate ->
after, Pete -> pet, fluoride -> /flohrid/, concrete -> /kaNkret/.
In other cases, a vowel is supplied that has no relation to the
basic rule: device -> /divoys/, stated -> started, arrive ->
/riyv/, mice -> /miys/. Some errors are plainly motivated by the
exceptions noted above: moves -> more, moves -> most, moved ->
most.
A most significant set of errors are the inverse errors, where a long
vowel is supplied when a short vowel is dictated by the spelling: slid ->
slide, crops -> coops, hymns -> /haymz/, children -> chide, listen
-> lice, twenty -> twice, suppertime -> supertime, hopscotch ->
hopescotch. These indicate that the mastery of the simple regular CVC
pattern is not complete. The fact that slid can be realized as slide
shows that the reader does not control either the rule that i is
short /i/ in the environment C(C)VC (Exceptions: none), or the rule that i
is long /ay/ in the environment C(C)VCe (Exceptions noted above).
The third column in Figure 5 indicates that when an error does occur in a word
subject to the CVCe regularity, in nine out of ten cases the silent /e/ rule is
not being used accurately.
There is no simple regularity governing sequences of two vowels: the often
quoted rule that the first vowel says its own name applies only to AY, AI,
EE, OA, UE but not to AU, AW, EY, OO, OY, OU, OW, UY. The analysis
of the individual patterns would require a larger data set, based on frequency
of all words in the texts read. However, Table 4 gives some indication of the
patterns involved in the 108 reading errors with double vowels in the nucleus.
The words in which the errors occur are classified as "regular" if they follow
the major regularity that can be described by a rule. For example, the word
looked is considered regular since all oo combinations before /k/
are pronounced with short /u/ (Exception: kook); the word dew is
regular since it shows ew -> /uw/, while sew is irregular.
In Table 4, there are very few errors involving the most regular double vowel
combinations: AY, AI, OA. But the most transparent double vowel of all, EE, is
well represented among the list of errors. The irregular combination EA is also
well represented, with threatened -> /t´rt´nd/, earth ->
each, dean -> Dianne, etc. The totals for all vowels indicate a relation
between irregularity and reading errors (Chi-square = 3.8, p < .05).
Table 4. Errors and successes with double vowels in words with reading errors.
(Upper figure: reading of VV correct; lower figure; reading of VV
incorrect).
Regular Irregular Inverse
ee 3/3 2
ei 1/4
ea 16/6 1/3 1
ew 1/5
eo 1/0
ey 1/1
ie 1/2
ai 0/1 2
ay 4/1
oi/y 2/0 1
oa 0/1
oo 4/1 2
ou 2/6 4/9 1
ow 0/3
aw 2/5 3
ue 0/2
Total 36/33 7/20 12
The next category, r-controlled vowels, refers to vowels followed by
/r/ in the same closed syllable: here, card, hardware, store, board
etc., but not merry, orange or arrest. This category seems to
show the effect of the phonetic pattern of AAVE. In Philadelphia, speakers of
AAVE show a wide range of variation in the realization of postvocalic /r/, with
most speakers averaging about 50% consonantal and 50% vocalized /r/.[8] In this data set, there are only three examples
of an orthographic r not being registered in the interpretation of the
word: earth -> each, return -> runting and Missouri ->
messes. It is more common to find that the vowel supplied is not the one
indicated in the spelling: star -> store, stare -> store, war ->
/wiyr/, where -> worry, their -> her, Hampshire -> hemisphere.
More often, we find the /r/ pronounced as if it occurred in a different
location in the word: assorted -> across, strong -> short, threaten
-> /Q´rt´nd/, tried -> tired, dirtying -> drying, Corvette
-> /kohrvend´r/. But the most common type of error is inverse: an
/r/ is supplied although there is no indication in the spelling that an
r is present. Thus we have
another -> Arthur
stated -> started
economy -> /´kohrn´mi/
cousins -> /kohrzinz/
agent -> /ohrgid/
Albert -> /ahrb´rt/
ocean -> /owkohrn/
moves -> more
they -> their
while -> where
glide -> girlies
This pattern of errors indicates that postvocalic /r/ is a stumbling block in
the reading patterns of the West Philadelphia speakers of AAVE. Since /r/ does
not have a stable representation in the spoken language, the step from
orthographic representation to phonemic interpretation appears to be
obstructed.
Problems with the interpretation of bisyllabic words are too frequent and
complex to be dealt with here. One of the problems lies with the readers
assigning long vowel status to the vowel in a second syllable that is
storage -> /stohreyj&/
notice -> /natays/
carrot -> /kærowt/
pirate -> /p´riyt/
ocean -> /owkohrn
aphid -> /æp´hiyd/
models -> /midey/
moment -> mommy
There are many other difficulties involved in bisyllabic words, but it is clear
that rules for assigning stress must be incorporated to advance one's reading
level. This problem is highlighted by a question that students have asked more
than once: why is comfortable not pronounced "comfort-table"?
The last column in Figure 5 concerns unstressed vowels. As in the previous
case, the number and variety of errors involving unstressed vowels is too great
to allow a simple analysis. But there is a remarkable tendency to simply omit a
final syllable, which is the converse of the tendency discussed above to assign
a full value to unstressed vowels. Thus we have a second syllable simply
omitted:
closet -> /klowz/
seconds -> six
dizzy -> diz
broomy -> broom
morning -> moon
nasty -> nast
grouchy -> grouch
daydreamers -> daydreams
strangest -> strange
Even greater problems are created by trisyllabic words with unstressed vowels
in a middle syllable: separate -> sport, incident -> /inhent/.
This is not surprising, since all of the problems outlined so far are
multiplied in such multisyllabic words.
In previous discussions of how one might apply knowledge of AAVE to the
teaching of reading, it was emphasized that the relation between the written
and the spoken language was far more complex at the ends of words (or
syllables) than at the beginning. This is particularly true for AAVE, where the
tendency to simplify final consonants is more extreme than in other dialects,
particularly in absolute final position, or "citation form." It was therefore
suggested that in the teaching of reading to speakers of AAVE, more attention
be given to the ends of words than the beginnings (Labov 1983, 1995). So far,
the special phonological character of AAVE has been reflected in reading errors
only in the r-controlled vowels. Further evidence will appear in this section
of the analysis.
The error rate for the lone post-vocalic consonant shown in Table 5 and Figure
4 comes close to the error rate for the first vowel. While it is higher than
for the initial consonant, it is considerably lower than any of the more
complex codas.[9] Again, this figure reflects
the fact that even readers who are operating at one or two years behind grade
have the ability to recognize and integrate individual letters into the reading
process. The errors that do occur are the result of a wide variety of causes
which are often connected with the problems reflected at the end of the last
section: the segmentation of syllables.
Final geminates seem at first glance to be no different from final lone
consonants. In speech, English phonological rules automatically reduce them to
single consonants. Yet they produce a distinctly higher rate of errors in the
words involved here. It is not clear that the errors of planning -> play
and passing -> pages have anything to do with the -nn- and
-ss- involved here. It is even less clear how the -tt- in
letting is involved in the misreading lesting. But the overall
picture is that any complication in the coda will be a focus of difficulty in
decoding.
The final digraphs -ch, -th, -ng, -ck lead to a further increase in the
likelihood that this will be the site of a reading error. It is the set of
words with -gh spellings that are responsible for this increase, marked
in the table and figure as exceptions: thoughts -> things, thoughts ->
though, right -> ridge. This is hardly surprising.
The fourth and fifth categories in Table 5 and Figure 6 deal with clusters of
two different consonants. In speech, English clusters are frequently
simplified; this happens in different ways, depending on whether the second
element is a tongue-tip or apical consonant (/t, d/) or a consonant of a
different type formed with the lips (/p, b/) or the back of the tongue(/k,g/).
In speech, the apical consonants are frequently deleted by speakers of all
dialects, yielding forms like good ol' boy or las' month.
Clusters ending in non-apical consonants follow a different pattern. If the
first element is nasal consonant (/m,n/) it is often vocalized, and the second
element is rarely dropped. If the first consonant is an /s/, we find that
second element in words like wasp or ask is occasionally deleted,
but not as often as with apical consonants.[10]
These patterns of simplification are found in all English dialects, but for
AAVE, it occurs at a relatively high rate, and simplification in absolute final
position is very high.[11] This means that
when a word is explicitly introduced to a learner ("This is gold."), the
final /d/ is in a position where it is least likely to be pronounced or
heard.
The most likely focus for reading errors in the final set of consonants is
therefore in the group of clusters that are most reduced in AAVE speech: the
apical clusters -st, -nd, -nt, -ld, -lt. Of the 38 words with such final
clusters, 26 are the site of a reading problem.
It is sometimes thought that AAVE does not simplify clusters with
heterogeneous voicing like -lt in belt or dealt, and
-nt in sent and went. The rate of simplification is lower
for such clusters than homogeneous clusters, but there is a regular rate of
reduction for all speakers (Labov et al. 1968). The reading problems are
comparable:
Homogeneous Heterogeneous
-ld -lt
bald -> blad salty -> sailintli
mold -> molid split -> spilt
children -> chide
mold -> miles
fieldlets -> findlets
-nd -nt
behind -> beginning twenty -> twice
round -> right moment -> mommy
seconds -> six moment -> meat
wanted -> water
agent -> /ohrgid/
Among the highest rates of simplification in speech are the clusters in -st,
exemplified here by roasted -> rose, suggested -> shoulder,
strangest -> strange. It is not an accident that the word posts
is read as pots, since the cluster -sts is categorically
unpronounceable in AAVE (Labov et al. 1968:131), and this is one of the ways of
reducing it to a speakable form.
There are also significant rates of inverse errors involved with
consonant clusters: Audrey -> Andrew, decided -> dances, disease ->
distance. It is interesting to note that these additions of clusters where
no errors were found in the spelling all involve the insertion of an apical
nasal consonant /n/.
Only 10 non-apical clusters are found in the list of reading errors, and of
these, only are the site of an error: Hampshire -> hemisphere,
clumping-> climbing, Ralph -> /ripU/, and the inverse hiding ->
hanking. [12]
The orthographic problems posed by non-apical clusters are no different from
those posed by apical clusters, and this difference must therefore be
attributed to the intersection of speech patterns and phonological perception
with decoding of the visual signal.
Table 5 and Figure 6. Distribution of errors in the consonantal coda.
N |
Total |
Inverse |
R/L transfer |
Exceptions | ||
Lone consonant |
225 |
56 |
0 |
0 |
0 | |
Final geminate |
48 |
18 |
0 |
0 |
0 | |
Final digraph |
34 |
14 |
0 |
0 |
4 | |
Final apical cluster |
58 |
46 |
10 |
1 |
0 | |
Final non-apical cluster |
11 |
5 |
1 |
0 |
0 |

Appended to the coda are the English series of grammatical inflections: the
plural -s, the possessive -'s, the third singular -s on
the present tense of the verb, the comparative -er and superlative
-est, the regular past tense -ed, and the present participle
-ing. Here one would expect to see the most specific effects of the home
language of the West Philadelphia students, since AAVE treats the various
suffixes quite differently. In the body of reading errors, there is a fair
amount of data on three of these: the plural -s, past -ed, and
participle -ing. We have a small set of possessives, sufficient to give
a bare indication of how readers treat this suffix.
Though the inflections represented by a single consonant form part of
the coda of the preceding syllable, they are treated differently in speech from
other members of the coda. For example, the word goes usually shows the
length and phonetic position of the free vowel in go, as opposed to the
checked syllable of rose. In reading, we would also expect that those
who are familiar with the functions of these particles will treat them
differently from other members of the coda.
Table 6 and Figure 7. Distribution of errors for grammatical inflections.
N Total Inverse % errors
errors
Plural -s 89 47 12 53
Participle -ing 34 19 8 56
Preterit -ed 25 21 0 84
Possessive -'s 3 3 0 100

Every study of AAVE shows that the plural inflection is intact. There are only
two points of difference from other dialects to be noted:
(a) Like many other Southern dialects, AAVE does not use the plural inflection
with nouns of measure: e.g., three books but three cent, five
year.
(b) The -s is generalized to nouns that take a zero plural in
other dialects: deers, sheeps, fishes, and nouns with the -en
plural: mens, womens.
Some pre-adolescents will omit the plural inflection, but Torrey's
study of second graders in Harlem in 1967 showed over 95% use of the plural in
spontaneous speech, and no difficulty in semantic interpretation. Ball's
replication in Michigan in 1983 showed similar results. Because the plural is
regularly pronounced, we count every omission of it as a probable error in
reading.
Table 6 and Figure 7 show a sizeable error rate for plural -s, but by
no means as high as the other elements in this section, and quite moderate when
compared with the coda in Figure 6. Furthermore, the pattern of inverse errors
indicates a consciousness of the use of the plural as a grammatical inflection.
In changing -> changes, thinking -> things and passing ->
pages the reader is plain substituting one inflection for another. It is
interesting to note that many of the simple omissions involve the variant
-es, used after sibilants and i (from y): dresses ->
dress (twice), witches -> witch (twice), houses -> house,
bodies -> body . The actual percentage of simple errors of the plural
-s is then reduced to a small number.
It follows that the West Philadelphia readers have a better understanding of
the consonantal representation of the plural as -s than the alternate
spelling -es. The ability to read the -s inflection is shown in
such errors as treaters -> treats, where the -er on the
unusual word treaters is omitted but not the plural itself.
So far, no observations of AAVE have indicated any difference from other dialects in the use of the -ing suffix.[13] At first glance, it seems surprising that there is such a high error rate in the reading errors: 61% of the words involving -ing show errors. But a second glance shows that most of these are inverse errors: -ing being supplied where it did not exist in the original text. The significance of such inverse errors for a suffix is quite different for the silent -e rule. Instead of showing a lack of knowledge, it indicates that readers are aware of the -ing suffix and are willing to supply it to make sense of the text. In order to explore this topic more deeply, we would need a different type of data, examining the reader's efforts to interpret the entire sentence. At the moment, it seems clear that the treatment of -ing is comparable to the treatment of plural -s, both suffixes that are well known and recognized in AAVE.
As noted above, many studies of the simplification of past tense clusters show
that AAVE speakers have the same variable behavior as in all other dialects of
English. The second element of clusters ending in -t or -d is
deleted, less often when the following word begins with a vowel and less often
with stressed syllables. Most importantly for this section, the deletion occurs
less often when the -t or -d represents a separate morpheme,
either the regular past -ed or the participle -ed used with the
passive or the perfect. It is important to note that this has nothing to do
with knowledge of the past tense, for the irregular verbs like told and
gave are used consistently for the past in the same way as other
dialects. The fact that this is a phonological rule is underlined even more
sharply by the fact that the /´d/ form used after apical stops is never
deleted: the suffix is quite regular in wanted, interested, demanded.
At the same time, it should be noted that the grammatical constraint is weaker
in AAVE than in other dialects, and experimental evidence shows that core
speakers of AAVE are not able to use the information of the -ed suffix
in a written text to obtain past tense information.[14] The rate of errors shown in Table 6 and Figure 7 is very
high, comparable to the monomorphemic apical clusters in Table 5 and Figure 6.
This similarity in error rates suggest that the readers are behaving as if the
past tense clusters do not contain any special information, consistent with the
experimental results on semantic interpretation.
Because the realization of -ed is variable in speech, the absence of
-ed was never counted as an error when it was omitted except after
apical consonants -t and -d. Thus tricked -> trick was
not included as an error, since we must follow the basic principle of
distinguishing (possible) differences in pronunciation from mistakes in
reading. The case of acted -> act is counted as an error, since this
full syllable is never omitted in spontaneous speech. The error list does
include 7 cases from several readers where the -ed is pronounced as
[´d] after non-apical consonants: tricked -> /trik´d/, forced
-> /fohrk´d/, winked -> /wiNk´d/, tucked -> /tUk´d/,
watched -> / wac&´d/ (twice), screeched ->
/skriyc&´d/, looked -> /luk´d/. In these cases, we can
conclude that the reader has not detected the past tense information, since the
suffixes would never be pronounced in this way in speech.[15]
The high error rate for the -ed form, as compared with the plural,
therefore reflects the high rate of variation in speech and the unreliability
of the printed signal for deriving past tense information for speakers of AAVE.
Every study of spontaneous speech in AAVE shows that the possessive suffix is
absent in attributive position. Although it appears regularly in absolute
position (This is hers, that is mines), it is close to 100% absent in
the basilectal vernacular in such constructions as my brother house, the
dude old lady. Furthermore, the experiments of Torrey and Ball show that
second grade children cannot assign a semantic interpretation to -s ro
distinguish pairs like the duck nurse vs. the duck's nurse. There
are only three occurrences of the possessive -s in the reading errors,
all involving the form witch's. As Table 6 shows, the -s does is
absent from the reading in all three cases.
In spite of the limitations of the data set on grammatical affixes, the
over-all picture that emerges from Table 6 and Figure 7 is quite clear. The
inflections that are stable in AAVE show only a moderate percent of reading
errors, including a high proportion of inverse errors. The significance of
these inverse errors is the opposite of inverse errors in phonology, as in the
reading of CVC syllables with long vowels. Inverse grammatical errors indicate
that the suffix is part of the inventory of forms that the reader is willing to
supply in the effort to make sense of a sentence when other difficulties
arise.
On the other hand, suffixes that do not have a stable position in the
underlying grammar will show a very high rate of reading errors, and will not
be supplied when they are not present in the text.
In assessing the pedagogical implications of this research, the first step is
to sum up the strengths and weaknesses of the Woodruff 2nd and 3rd graders in
decoding skills. One clear strength is in the accuracy of their recognition of
consonants. For initial consonants, it is very high: at least 96%. In this
respect, the goals of the initial phase of their phonics program can be said to
have succeeded. This level of accuracy is less for the first vowel, but it is
still moderately high, and even when a lone consonant is imbedded in the middle
of a word, it is recognized correctly 80% of the time. The next steps in
advancing the level of reading can build on these skills.
The findings show that this level of accuracy contrasts sharply with a very
great degree of difficulty the Woodruff students have with any syllable
structure other than CVC. Complexities in the consonantal onset are responsible
for more than 30% of the errors in words read incorrectly, and when more than
one consonant occurs , this rate jumps to 40, 50 and 80%, depending on the
structures involved. When more than one vowel occurs in a word, this is
responsible for the mistake in an even higher proportion of reading errors:
from 60 to 90%. It is startling to find that the most reliable of all the sound
to letter correspondences in the choice of long or short vowels--the silent
e rule--is not learned at all.
We can couple these findings with what we know about the teaching of phonics
in the Woodruff school. The most commonly used phonics book is the Steck-Vaughn
series (York 1995). The approach to phonics is typical of many other phonics
books. Table 7 shows the distribution of topics, the ordering, and the amount
of effort devoted to each phonics area. It is clear that the lion's share of
the attention goes to the first, lone consonant and the first (short) vowel;
62% of the lessons are devoted to these topics. If we add in the lone consonant
after the vowel, we find that 72% is devoted to the CVC structure. It is not
simply the proportion of lessons that is involved here, but their ordering. It
is not until page 157 that long vowels are introduced.
Table 7. Topics of lessons for Year 1 of Steck-Vaughn Phonics Series.
Pages |
Letter |
Consonants |
Vowels |
|||||
|
recognition |
Initial |
Med/final |
Blends |
Digraphs |
Short |
Long |
Y |
0- |
10 |
|
||||||
10- |
10 |
|||||||
20- |
8 |
2 |
||||||
30- |
7 |
2 |
2 |
|||||
40- |
4 |
8 |
||||||
50- |
10 |
1 |
2 |
|||||
60- |
4 |
2 |
7 |
|||||
70- |
6 |
1 |
6 |
|||||
80- |
5 |
2 |
7 |
|||||
90- |
4 |
10 |
||||||
100- |
8 |
1 |
1 |
|||||
110- |
6 |
10 |
||||||
120- |
5 |
6 |
||||||
130- |
4 |
3 |
4 |
|||||
140- |
4 |
4 |
6 |
|||||
150- |
6 |
5 |
||||||
160- |
10 |
|||||||
170- |
10 |
|||||||
180- |
10 |
|||||||
190- |
8 |
2 | ||||||
200- |
2 |
8 |
6 | |||||
210- |
10 |
|||||||
22-0 |
10 |
|||||||
230- |
8 |
|||||||
Total |
28 |
69 |
22 |
12 |
18 |
74 |
46 |
8 |
Grammatical inflections are introduced at the end of the first year: three
pages devoted to plurals, 5 to verbal -s and -ing. Discussion of
vowel digraphs or r-controlled vowels, diphthongs or shwa is relegated to the
second year. This is not an unreasonable procedure, if we follow the
hierarchical principle of beginning with the simplest objects and relations and
adding more complex ones only when they have been mastered. It is an open
question whether or not this level of success in identifying initial consonants
could be achieved with less time and effort. The question to be considered here
is whether the grave defects in decoding more complex structures which persist
even into the fourth grade might be corrected by following a different
strategy.
At present, we do not know how much time is devoted to the whole phonics
series, either in individual or group sessions. But it is clear that no school
child is likely to work through all of the lessons of the Steck-Vaughn or any
other series. The long vowels are not introduced until page 160 of the texts.
There are 129 lessons in the first year; to keep pace would mean 3 or 4 lessons
every week: the long vowels are not introduced until lesson 79, and one would
have to guess from the end result that the children had not been exposed for
any length of time to this topic.[16]
The implications of this report suggest strategies that are radically
different from those most widely used in the field. One general strategy is
obvious: that more time should be devoted to the "rhyme": the vowels and
consonants which follow the consonantal onset, and especially to the consonants
at the ends of words. The lessons devoted to the initial lone consonant should
be accompanied by lessons that consider the same consonant in final and perhaps
medial position in the syllable.
The second general strategy that emerges from this report is that the CVC
syllable should not dominate the introductory phonics lessons to the extent
that it does. The high prevalence of inverse errors in the long/short vowel
pattern shows that teaching CVC patterns in isolation does not lead to an
understanding of the basic relations involved. The fact that children learn to
read the word hop accurately does not mean that they understand when a
given spelling regularly indicates a short vowel, since in other occasions they
read hope as hop. Knowing that hop is /hap/ is not
sufficient; they must also know that hope cannot be /hap. By introducing
CVCe words earlier, in conjunction with CVC, one would allow the child to learn
not only that bit is /bit/, and bite is /bayt/, but also
that bit is not /bayt/ and that bite is not /bit/; that hope
is not /hap/. It is this contrastive relation which would solidify the
child's understanding of the CVC structure.
The same argument applies to vowel combinations. The more stable vowel
digraphs, like OA and AI, may be introduced early to solidify the contrast
between cot and coat, rod and road, pan and pain, mad
and maid.
These are particular strategies. The general approach that seems
necessary is to increase learners' awareness of the structure of words
very soon after they have achieved accurate letter recognition. This can be
done by many means, consistent with any explicit or implicit approach to
phonics that controls the reading vocabulary. We are developing and testing
methods that will increase the accuracy of students' early perception of the
number of graphemes in the onset, a nucleus and coda, so that they are ready to
apply decoding strategies to structures that are recognized as CVC, CCVC, CVVC,
and so on.
This research into methods accompanies the gathering a larger body of
data to confirm or revise the findings presented here. The suggestions put
forward here are designed to contribute to the thinking of the many educators
who are engaged in the long and difficult process of improving the teaching of
reading.
Adams,
Marilyn Jager 1990. Beginning to Read: Thinking and Learning about
PrintCambridge, MA: MIT Press.
Baugh, John. 1983. Black Street Speech: its history, structure and
survival. Austin: University of Texas Press.
Calfee, Robert C. and Richard L. Venezky 1968. Component skills in beginning
reading. Technical Report No. 60. Madison, WI: Wisconsin Research and
Development Center for Cognitive Learning, U. of Wisconsin.
Clymer, T.. 1963. The utility of phonic generalizations in the primary grades.
Reading Teacher16:252-258.
Fasold, Ralph.. 1972. Tense Marking in Black English. Arlington, VA.:
Center for Applied Linguistics.
Goodman, Kenneth S. 1969. Dialect barriers to reading comprehension. In J.
Baratz & R. W. Shuy (eds), Language Differences: Do they
interfere?Newark: DE, International Reading Association. Pp. 14-28.
Labov, William 1995. Can reading failure be reversed: a linguistic approach to
the question. In V. Gadsden and D. Wagner (eds.), Literacy Among
African-American Youth: Issues in Learning, Teaching and
Schooling.Cresskill, NJ: Hampton Press. Pp. 39-68.
Labov, William, P. Cohen, C. Robins and J. Lewis.. 1968. A study of the
non-standard English of Negro and Puerto Rican Speakers in New York City.
Cooperative Research Report 3288. Vols I and II. Philadelphia: U.S. Regional
Survey (Linguistics Laboratory, U. of Pa.)
Labov, William. 1972. Language in the Inner City. Philadelphia: Univ. of
Penn.
Labov, William. 1983. Recognizing Black English in the classroom. In J.
Chambers (ed.), Black English: Educational Equity and theLaw. Ann Arbor:
Karoma Press. Pp. 29-55.
NAEP 1994. National Assessment of Educational Progress: Achievement of U.S.
Studenets in Science 1969-1992, Math 1973-1992, Reading 1971-1992, Writing
1984-1992. Washington: Department of Education.
Torrey, Jane. 1983. Black children's knowledge of standard English. American
Educational Research Journal20:627-643.
Venezky, Richard L. 1972. Language and Cognition in Reading. Technical Report
No. 188. Madison, WI: Wisconsin Research and Development Center for Cognitive
Learning, U. of Wisconsin.
Wolfram, Walt. 1969. A Sociolinguistic Description of Detroit Negro
Speech.Arlington, VA: Center for Applied Linguistics.
York, Barbara 1995. Phonics: Book A. Austin, TX: Steck-Vaughn.
This report is the product of a seminar
held in the spring of 1998, Linguistics/AFAM 161, "The Sociolinguistics of
Reading." The organization and planning of the Extended Day Program is the work
of the Woodruff staff and B. Baker; data on reading errors were collected by
Baker, Bullock, Ross and Brown. We gratefully acknowledge the support of the
Center for Community Partnerships, directed by I. Harkavy, and the Kellogg
Foundation for the organization and development of this activity. We are
particularly indebted to the staff of the Woodruff School.
[2] The books read included Come to My
Island, Math Workbook, Martin Luther King, , History of Jazz, Spelling Words,
V-Tech game, Molly's Monsters, Five Little Monkeys, Maya Angelou, Alexander and
the Terrible, Horrible, NO Good, Very Bad Day, Lil's Purple Plastic Purse, I
Like Me, Little Witch's Big Night, The Grouchy Lady Bug, Magic School Bus at
the Waterworks, The Witch Baby, Kyla's Big Day, Daydreamers.
[3] The main evidence for this fact is that the
clusters are realized in their full form much more frequently when the next
word begins with a vowel, and that there is little or no hypercorrection
(Labov, Cohen, Robins and Lewis 1968, Labov 1972, Baugh 1983).
[4] The onset of a syllable consists of
all the consonants that precede the first vowel. The nucleus consists of
the vowel and glide that form the peak of sonority of the syllable. The
coda is the consonant or consonants that follow the nucleus. Thus in
cat the onset is /c/, the nucleus is /æ/, and the coda is /t/. In
strengths, the onset is /str/, the nucleus is /e/, and the coda is
/NQs/.
[5] A certain number of errors are to be
expected for the rule for the softening of /c/ before front vowels /i/ and /e/.
Here again, the West Philadelphia children are not markedly different from the
Wisconsin group who had just finished the second grade. The average per cent of
errors for such words was 30%, with quartile scores ranging from 19 to 40%
(Venezky 1972: Figure 1). For those words read wrong in West Philadelphia which
involved a syllable initial c, one third did not apply this rule:
ceiling -> killing, forced -> /fohrk´d/, ocean -> /okohrn/.
This included one inverse example, where softening was applied before an
unstressed vowel, spelled u:: circus -> /s´rsis/. On the
other hand, the softening rule was correctly applied in the majority of cases,
even when other errors were made: process -> /prowsiys/, voice ->
vice, ceiling -> /sæniy/, etc.
[6] In some clusters, the first element is a
digraph, as in three or shrewd. In this case, the word is counted
in both the digraph category and the Cr/l category.
[7] Though the scope of this set of exceptions
is limited, its regularity was plainly observed by the student who read over
as /Uv´r/.
[8] In a city like New York, where the
surrounding vernacular of the mainstream community shows uniform vocalization
of /r/, speakers of AAVE use 100% vocalized /r/ (Labov et al. 1968).
[9] The lone consonant here is assigned to the
coda, but in many cases it actually occupies an "ambisyllabic" position,
sharing membership in the preceding and following consonant.
[10] When the cluster is complicated by an
additional final /s/, as in wasps, desks, ghosts the rate of
simplification is much higher, and for speakers of AAVE, it is categorical, as
indicated above.
[11] For most English dialects, absolute final
position is the least likely place for simplification to occur. Guy 1981 shows
that white speakers in New York City also have a high rate of simplification in
final position, but this is not typical of most mainstream dialects.
[12] The difference between the rate of errors
in the apical clusters and the non-apical clusters is significant with a
chi-square of 5.9.
[13] It has been observed that the constraint
on using the progressive with stative verbs is weakened in AAVE.
[14] In reading a sentence like Last month,
I read the sign, subjects can transfer the past tense information in
last month to derive the past tense pronunciation of read. But in
the sentence, When I passed by, I read the sign, results were random.
[15] These are not to be identified with the
duplicated plurals that are commonly heard in speech, where /´d/ is added
after the regular form, as in pickted, lookted.[16]
This situation can be generalized to the phonics programs as a whole. In 1963, Clymer examined the teachers' manuals of four widely used basal programs, and extracted 121 phonics generalizations; of these, he found that 45 were clearly stated in all four programs (1963; cited in Adams 1990). It is generally assumed that no reading program can actually teach all of these relations, but that some initial exposure to the general principles will help children to continue to abstract the patterns themselves as they continue to read. The initial configuration of phonics teaching is therefore of great importance. From our examination of reading errors, some suggestions emerge which might be helpful in reforming this initial configuration.